부제: Twyman 법칙과 신뢰할 수 있는 실험을 위하여
개요
(https://unsplash.com/photos/MDiwNU1pIdo)
제 경험상. 데이터 분석을 “공부하는” 사람의 관점에서 데이터 분석 업무는 상당히 우아한 작업으로 상상되곤 합니다.
- 의사결정권자 / PO 혹은 협업 중인 유관 부서의 요청으로,
- 사내 인프라에 구축되어 있는 위키나, 데이터 카탈로그를 참조하여 필요한 데이터를 파악하고,
- DB에서 필요한 부분의 데이터를 쿼리로 얻어
- 약간의 EDA, 시각화, 조금 욕심을 낸다면 regression을 비롯한 modeling까지 여러 방법들을 통해 데이터를 “조리하여”
- 청중의 심금을 울리는 리포트를 만들어내고,
- 이전에는 하지 못한 / 앞으로 해볼 수 있는 액션을 제시하고.
- 비즈니스에 임팩트를 빵 ! 만들어 내는 거죠.
(다시 한번, 제 경험입니다) 저는 어떤 질문이나 주제에 대한 답을 찾는 데이터 분석을 하게 되면 위 작업들 중 뒷 부분. 특히 “흥미로운, 새로운 발견” 에 포커스를 두는 경우가 꽤 많았습니다.
안타깝게도 “데이터 분석 프로젝트가 한 건 많은데 결과물은 없었습니다…” 라는 결론을 더 많이 내는 것을 알게 된 것은 나중의 일이었습니다.
옛날옛적에 Twyman 이라는 선생님이 있었습니다.
이 Twyman 선생님께서는 후대에 저 같은 데이터 분석가가 나타날 줄 아셨는지, 이러한 말을 했다고 해요.
흥미로워 보이거나 좀 달라보이는 통계치는 아마 니 실수다 ㅋㅋ

https://www.rsmb.co.uk/tony-twyman-awards
조금 더 짧게 표현하자면, “다시 해” 정도가 되겠죠?
물론 정말 저렇게 말하진 않았습니다. 구전동화의 프레임을 빌려온 이유가 있는데요. 책이나 저널, 인터뷰 등 공식적으로는 말한 적은 없고 오히려 다른 사람들이 Twyman 선생님께서 저렇게 말하셨대 ! 라고 하는 것이 전달 되었기 때문이죠.
이번 글에서는 우아한 분석을 다시 하게 만드는 실수의 이유와 예시들을 다뤄보겠습�니다.
잘못된 데이터 설계
한가지 예시를 들어보겠습니다.
우리가 교육부 소속의 데이터 분석팀이라고 해보겠습니다. (실제로 있는지는 모르겠어요) 전공을 자유롭게 선택 할 수 있는 공학계열 대학에서 졸업 후 진로를 조사했고 그 데이터의 결과가 아래 그림과 같았다고 할 때 어떤 결론을 낼 수 있을까요?
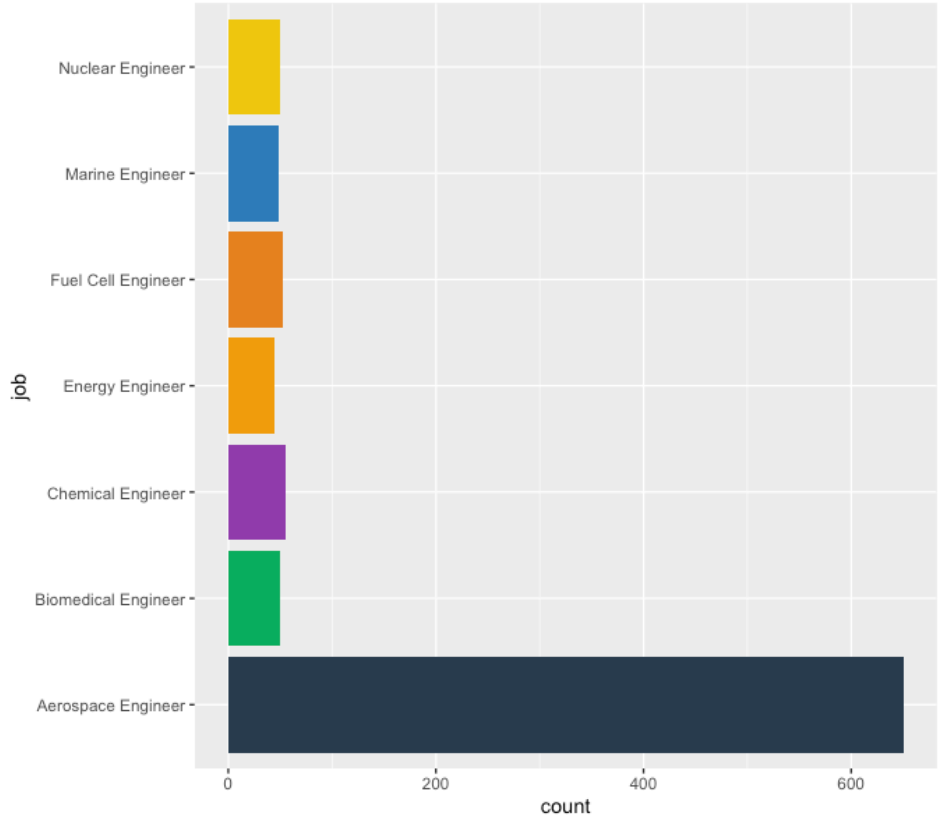
화성갈끄니까~~
오. Aerospace Engineer, 항공우주학부에 힘을 실어보자 !
해볼 수 있을 겁니다. (인력의 수요와 공급, 사회와 과학 기술 발전과 같은 이야기들은 다른 분들이 더 잘 고민해줄겁니다)
이제 우리는 한 30년 쯤 후, 많은 미디어나 블로그 책 등에서 “당시 데이터 분석을 통해 항공우주에 대한 수요를 파악했던 데이터 분석팀의 엄청난 노력이 있었다.” 라고 표현 되는 것을 명예롭게 누리면 됩니다.
정말로 그럴까요?
문득 생각난 Twyman 선생님의 말
흥미로워 보이거나 좀 달라보이는 통계치는 아마 니 실수다 ㅋㅋ
를 다시 기억해보고 데이터를 다시 보았습니다.
아뿔싸. 데이터 수집용 설문의 설계에 오류가 있었습니다.

https://www.protopie.io/blog/prototype-dropdown-menu 를 수정
공학 대학을 졸업했지만, engineer가 아닌 다른 직군으로 커리어를 설정한 학생들의 경우는(…) 해당 선택지가 없었고 자연스럽게 맨 위에 있던 Aerospace Engineer를 골랐던 것이죠.
전공별로 어느정도의 차이는 있을 수 있지만 저렇게 “압도적으로” 차이가 생긴 것은 실수를 가정하고 다시 검토해 볼 필요는 있습니다.
(이 경우라면 “그 외” 라는 선택지를 만드는 것도 하나의 방법이겠죠.)
분석 결과를 이해하지 못했을 때
실험이 잘 설계되어 있어도 다른 오류들이 항상 데이터 분석을 호시탐탐 노릴 수 있습니다.

https://talk.op.gg/s/lol/free/2371466/ . (갱플 너프 좀 ㅜ)
16–18세기 대항해시대에 바닷사람들을 괴롭혔던 괴혈병의 경우. 아주 잘 설계된 (A/B) 실험을 통해 “감귤과 레몬으로 치료 할 수 있다” 는 인사이트를 발견했는데요. 영국 해군의 질병위원회는 이를 활용해 농축 오렌지주스를 선원들에게 지급했다고 합니다. (바다로 나아갈때 짐을 줄이기 위한 방법으로는 아주 적합하죠.)
안타깝게도 농축하는 과정에서 가열하는 과정이 있었고, 당연히 비타민은… (말잇못)
그 결과 선원들은 실험의 결과와 인사이트를 신뢰하지 않았고, 괴혈병을 치료하기 위해 나쁜 피를 제거 하는 의사결정을 했다고 합니다.
영향은 있지만 그 정도까진 아닌 경우
이번 예시는 데이터와 실험, 기술의 최첨단을 달려가는 구글의 이야기 입니다.
https://www.businessinsider.com/google-search-turns-20-2018-9
2006년쯤에 구글은 검색 결과를 10개에서 20개로 늘리는 실험을 했습니다. (이미지의 10 results)
정확한 이유는 제가 구글러가 아니기 때문에 알 수 없지만, 결과를 많이 보여주면 더 좋은 page rank를 만들어 낼 수 있고, 그로 인해 더 정확한 결과를 보니 고객들도 좋아하고 이는 더 매출을 크게 만들어내고… 의 이유가 아닐까요?
그리고 실험의 결과, 매출은 20%가 감소했다고 합니다 (!)
그 당시 구글에서 생각했던 원인 중 하나는 “결과를 보여주는 시간 (Time to display) 이 500ms 가 증가했기 때문에” 라고 해요.

0.25초의 차이…
(나중에 이뤄진) 연구에 따르면 페이지가 보여지는 시간이 “100ms 증가할때 0.6% 정도의 매출이 감소” 한다고 합니다.
500ms 면 3% 언저리가 감소 했어야 하는데, 20% 라는 �것은 뭔지 모르지만 다른 이유가 더 있었다는 의미죠. (구글은 나중에 보여지는 20개 중 광고의 개수 가 주요 요인이라는 것을 조사결과를 통해 알 수 있었습니다)
(아, 구글은 지금도 10개의 결과를 한 페이지에 보여주고 있습니다. 제 기준)
Intention to Treat (ITT)
(치료 의향 분석이라고도 표현 되고 있습니다)
나도 이젠 젊어지고 싶따…
또 다른 멀티버스에서의 우리는 제약회사의 데이터 분석팀입니다. (최근 닥스2 봄)
어떤 신약을 만들었고, 이 약을 10주간 먹은 그룹과 그렇지 않은 그룹을 비교하는 것이 목표입니다.
100/100명으로 실험은 충분히 잘 설계 되었는데, 체질에 따라 약은 부작용이 있을 수 있다는 것을 미처 고려하지 못했습니다.
A그룹에서 3명이 (부작용으로 인해) 약을 B그룹의 약으로 변경한 상황 에서 우리는 비교 분석을 어떻게 해야할까요? (B그룹은 부작용이 없는 약을 먹는 그룹입니다)
- A그룹 97명 vs B그룹 100명
- A그룹 97명 vs B그룹 100명 + A에서 먹다만 3명
- A그룹 100명 vs B그룹 100명
첫번째의 경우, B그룹의 사람 중 3명 정도는 A약에 대해 부작용이 있을 수 있는데, 이를 고려 하지 않은 상태로 비교 하는 것은 bias가 있을 수 있습니다.
두번째, 부작용이 있는 3명을 B에 넣음은 B그룹은 부작용이 6명 있는 것으로 볼 수 있고, 마찬가지로 위험한 결론을 낼 수 있습니다.
마지막, 처음 분류했던 “의도 대로” A그룹과 B그룹을 비교하는 것을 Intention-To-Treat 방법이라고 표현합니다.
뭔가 이상합니다. B약을 먹었는데 A그룹으로 비교를 한다니.
사실 마지막 방법은 (표현하자면)
- A약을 먹는다 vs B약을 먹는다
의 전략에서
- A약을 먹는다. 만약 부작용이 있다면 B약을 먹는다 vs B약을 먹는다.
의 전략으로 실험의 방향이 바뀌게 된 것입니다.
(위의 첨부된 링크와 이 링크 에도 쓰여있는데 Per Protocal analysis 라고 시험을 모두 완수한 피험자만을 대상으로 하는 통계 분석 방법도 있긴 합니다.)
그 외의 여러 이유들
너무 유명한 Survivorship Bias
개발에는 TDD, DB는 정합성 등이 있는 것과는 다르게, 데이터 분석을 위한 실험과, 이어지는 결과 해석은 생각치도 못했던 이유들이 신뢰성에 영향을 주게 됩니다.
가령
Survirorship Bias- 잘못 계산 하여 의미가 옅어진
Statistical power나pvalue,Confidence Interval,Sample size - Test / Control 끼리 서로 영향을 주고 받을 수 있는 실험 설계
- 잘못된
randomize - 이상하게 차이가 많이나는 Test / Control의 비율 (1%이상)
Carry over effectSimpson’s paradoxPrimacy & Novelty Effect
등 정말정말 많은 이유들이 있습니다.
이들에 대해서 설명하는 너무 좋은 글들이 많이 있기 때문에 따로 서술하진 않겠습니다.
요약
너무 특이한 결과를 만들어 내는, 그래서 잘못된 결론을 낼 수도 있는
데이터 실험과, 분석을 만들 수 있는 이유와 예시들을 몇가지 다뤄봤습니다.
그리고 이를 방지하는 방법은. “분석 과정을 서로서로 코드리뷰 하듯 같이 피드백 하면서 그 결과에 신뢰성을 만들어 나갈 수 있는 프로세스가 아닐까…” 라고만 생각합니다.
누가 Trustworthy Driven Analysis 같은 것을 만들어 줬으면 좋겠지만, 도메인마다 데이터마다 질문마다 너무 다를 수 밖에 없기 때문에 또 어려운… (뇌피셜)
어쩌면 “실험은 꼭 성공했으면 한다라는 욕심을 줄이는 것” 도 하나의 방법일 것 같아요. (실험은 실패가 많아도 이상할 게 없습니다)
아래는 링크드인에서 감명받아 주워온 글의 일부인데요. 데이터 분석가들이 “우아한” 분석 업무 못지 않게 문화와 가이드에 대한 고민도 하게 되는 것은 꽤 당연한 이야기 같습니다.


어렵겠지만 데이터 분석. 너무 잘 풀린다 싶으면 다시 되돌아 보는 습관이 필요할지도…?
