Table Of Contents
이 글은 작성자 블로그에서도 보실 수 있습니다.
Intro
사내에 데이터 프로덕트라는 팀이 생겼습니다. 데이터 싸이언티스트라는 포지션으로 일해온지 이제 만 3년이 되었는데, 데이터 프로덕트라는 명칭은 알것 같으면서도 분명 모르는 것이었습니다.
저도 몰랐지만 여러분들 중에서도 모르는 사람이 있을 것 같습니다. 하지만 그게 무엇인지에 대한 설명을 듣고 나면 금방 이해가 될 것입니다. 데이터 프로덕트에 관한 정의는 DJ Patil의 유명한 책 Data Jujitsu에서 2012년에 등장하였습니다. 그는 여기서 데이터 프로덕트를 “데이터를 사용하여 최종목적을 달성하는데 도움을 주는 프로덕트(제품)“이라고 말하였습니다.
데이터 프로덕트를 만들어내는 입장에서 생각해보면, 데이터 프로덕트 자체가 비지니스인 기업과, 데이터프로덕트를 사용해서 자신들의 서비스를 이용하는 사용자들에게 편의를 제공하거나, 서비스의 가치를 높일 수 있는 방식으로 사용하는 회사들이 있을 것입니다.
전자는 영국의 유명한 Dunhumby와 같은 데이터 전문기업이나 여러가지 솔루션 기반의 완성품을 제공하는 AI 스타트업들과 AI 유니콘들이 있을 것이고, 후자로 치면 대표적으로 번역기와 같이 멋진 서비스나, 이미지검색 기능, 심지어 Tensorflow와 같은 ML전용 툴을 제공하는 Google, 클라우드 서비스를 통해서 이미 �학습된 ML 모델을 제공해주는 Amazon, 그리고 애플리케이션의 모든 곳에서 개인화 기능을 제공하는 Netflix같은 회사들이 있을 것입니다. 여기서 오늘은 Netflix와 같이 ML 기능을 데이터 프로덕트의 주제로 삼고자 합니다.
데이터 프로덕트를 만들라고 하였으니, 가장 떠오르는 일은 ML 기능을 개발해야겠다고 생각하는 것이었습니다. 그렇지만 하루하루의 실적과 상황에 따라 울고 웃는 스타트업에서 수 명의 데이터팀 구성원들이 모두 ML개발에 매달려서 “4주후에 뵙겠습니다” 라고 말할 수는 없는 노릇입니다. 그래서 우리는 만들어야 하는 데이터 프로덕트의 정의를 아래와 같이 정했습니다.
- Data as Product
- 데이터 자체가 가치를 가질 수 있는 것.
- 요약 통계를 가지고 있는 테이블로써 내부구성원들의 의사결정에 도움이 될 수 있는 정보
- 특정한 목적을 가지고 유저들에게 제공될 수 있는 결과물로써, 분석을 통해 큐레이션 되어있는 추천 목록 등
- 주로 머신러닝 등의 모델에 사용될 수 있는 다양한 속성을 가진 메타테이블 (상품 또는 유저)
- 그리고 위 데이터들에 대한 시각화 정보
- Data-Driven Product
- 데이터 이용한 모델링을 통해서 특정한 유저스토리를 만족시킬 수 있는 기능으로써의 제품
- 머신러닝을 이용하여 특정한 서비스가 되는 경우 (예: 챗봇)
- 머신러닝 또는 모델을 이용하여 사용자의 눈에 보이지는 않지만 사용자의 편의를 증대시켜주는 기능(예: 추천 또는 예측)
- 그 밖에 데이터를 이용하여 사용자에게 유용한 정보를 주는 방식으로 사용성을 개선시키는 기능(예: 마이페이지 대시보드)
- Data Science Product
- 통계학 또는 데이터 분석기법(마이닝 등)을 이용하여 작성된 분석 보고서
Data Product Project
대략적으로 어떤 것이라는 것을 알았으니 이제는 데이터 프로덕트를 만들어야 하고, 여러 사람으로 구성된 팀이라는 특성상 누가 무엇을 언제까지 누구와 일해서 누구에게 어떤 목표를 이루도록 해야 하는지와 같은 게획이 필요하게 되었습니다. 그리고 단순한 ad-hoc이 아닌 많은 일들 중에서 위와 같은 조건을 만족하는 것을 Project라고 부르도록 하겠습니다. 그리고 Project를 관리하는 수 많은 방법과 툴을 사용할 수도 있을 것입니다. 이를테면 툴로써 Jira 또는 Trello를 사용한다거나, 수행방법론으로써 Waterfall을 언급 할 수도 있을 것입니다.
그렇지만 초기에 우리는 이런 프레임워크가 없었습니다. 그리고 개발팀에서 사용하는 Jira라는 툴에 대한 라이센스가 있었기 때문에 데이터팀에서도 이 것에 대한 활용을 해보기 위한 적응기간을 가지고 있었습니다. 하지만 이것이 데이터프로덕트를 만드는 프로젝트를 할 때에 얼마나 효과가 있었는지에 대한 의문이 있었습니다. 왜냐하면 프로젝트를 말 그대로 매니지 하기 위해서는 현재 어떤 단계에서 프로젝트가 진행되고 있고, 진행중인 업무(Jira에서 티켓이라는 형태로 만들어진 Task)가 얼마나 난이도가 있는지, 얼마나 지연되고 있는지, 반드시 필요한 일인지 이런 것들을 평가할 수 있어야 하는데 Jira가 그런 용도로 사용될 수 있는지 알지 못했기 때문이니다.
또 하나의 어려운 점은, 데이터 프로덕트라는 것이 PM 조직에서 쉽게 기획하기 어려운 일이고 따라서 어떤 일들은 명확한 목표와 기한을 가진일로써 기획되지 않은 채로 시작되기도 한다는 점이었습니다. 그러니깐, 프로젝트이기는 하지만 전통적인 의미에��서의 프로젝트가 아닐수도 있는 셈이었습니다. 그렇다면 기한도, 규모도 미리 정하기 어려운 상태로 스스로 관리하는 프로젝트라고 불러도 되는 그런 종류의 일일 수도 있는 것입니다.
아래 두 가지 원칙을 정하고, 프레임워크를 세우기로 했습니다.
- 모두가 공통으로 사용하는 도구를 활용한다.
- 프로젝트를 수행하는데 있어서 모두가 같은 용어와 이해를 가져야 한다.
Framework
리서치를 하는 도중에 아래의 문서로부터 큰 도움을 받을 수 있었습니다.
데이터와 관련된 프로젝트들에는 어떠한 흐름이 있습니다. 흔히 말하는, 데이터 준비, 피쳐 엔지니어링, 모델링, 평가와 같은 것들입니다. 좀 더 상세하게 이런 것을 정형화 한 방법론중에 Crisp-DM이라는 것이 있습니다.
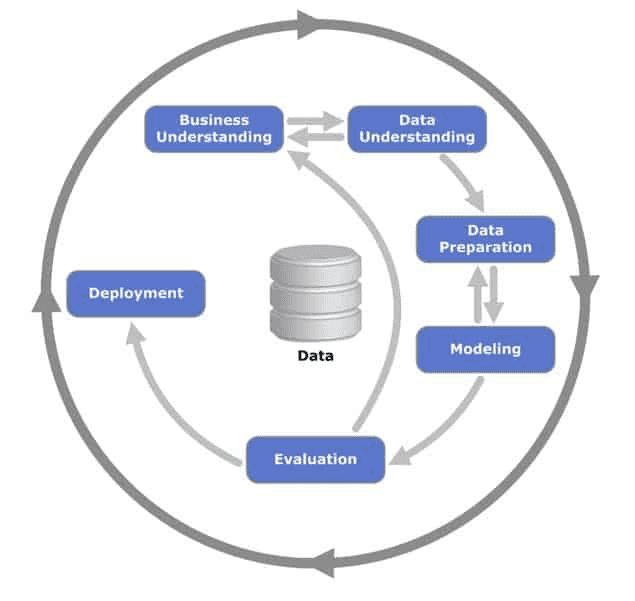
Crisp-DM 프레임워크는 데이터마이닝이 시작된 90년대에 처음 등장하였는데 ML위주의 데이터 프로덕트가 많아진 지금까지도 이 흐름의 유형은 유효해 보입니다. 심지어 거의 모든 것이 지금에도 유효하다는 것이 놀라울 정도입니다. Crisp-DM은 지금까지도 가장 많은 데이터싸이언스/데이터 프로덕트 조직에서 사용되고 있는 방법론입니다.
비지니스에 대한 이해로부터 출발해서, 데이터 조사 및 준비작업, 그리고 모델링, 평가, 배포에 이르는 흐름은 지속적으로 Feedback 고리 안에서 순환합니다. 한 단계가 끝나야지만 다음 단계로 나아가는 Waterfall 방식과 확실히 다릅니다.
그리고 이제는 너무나도 유명한 Microsoft의 TDSP도 있습니다. TDSP는 머신러닝이 본격화되면서 머신러닝의 특성을 좀 더 자세히 담고 있습니다. 이를테면, 피쳐 엔지니어링이라던지, 데이터파이프라인 구성과 같은 세부 항목들이 추가된 것과 같은 것들입니다. 하지만 큰 틀에서 유사점이 많기에 Crisp-DM의 상세버전이라고 보는게 더 맞을 것 같습니다. 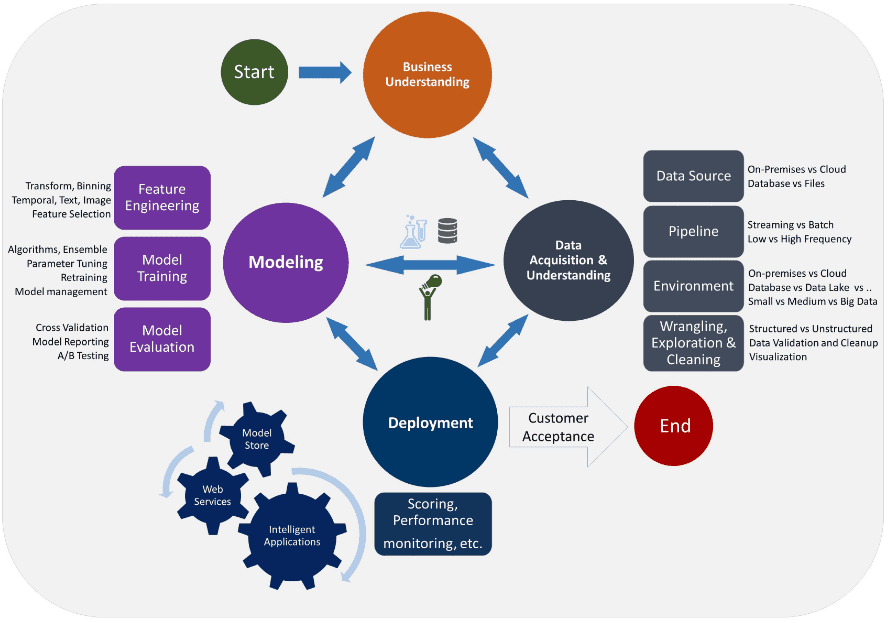
그런데 이러한 좋은 프레임워크과 Jira를 결합해보고 싶었습니다. 앞에서 이야기한대로 우리팀은 이제 Jira라는 유료툴을 사용해보기로 했으니까요(이야기의 효율을 위해 Jira라는 툴을 어느정도 알고 있다고 전제하고 쓰는 것에 대해 양해를 구하도록 하겠습니다).
앞에서 저희팀에서 Jira 도입 초기에는 자유롭게 Task들을 생성하는 방식으로 사용되고 있었다고 이야기 했습니다. 다행인 것은 이 Task들을 하나로 묶어줄 수 있는 개념이 있습니다. Epic입니다. 이전에 Task라는 것이(이것은 Ticket이라고 부르기도 합니다.) 자유롭게 생성될 수 있는 개념이었다면, 이제부터 Task는 반드시 정해진 이름으로만 만들 수 있도록 하였습니다. 그 이름은 위의 프레임워크의 흐름에 따라서 각각 리서치 및 탐색, 논의, 모델링, 프로덕트화, A/B테스트,결과분석 이라는 이름으로 정했습니다. 그럼 모든 Task는 Epic 아래에 동일��한 모습으로 존재하게 됩니다. 이렇게요.

간단하게 설명을 덧붙이자면 아래와 같습니다.
🏆 논의 : 내외부의 구성원들과 이 프로젝트를 진행할 수 있을지에 대한 논의를 거쳐야 합니다. (짧게는 몇일, 길게는 1~2주이며 이 기간을 넘어가면 Pending으로 자동으로 넘깁니다) 프로젝트가 다음 단계로 넘어가기 위해서는 반드시 수요일 Data Weekly에서 현재까지 내용을 공유하고 의견을 받아야 합니다.
💭 모델링 : 제안된 내용을 증명하는 단계로써, 쿼리 및 스크립트를 이용한 모델링을 수행합니다. 이 단계에서는 모든 Task를 더 세분화하여 Sprint로 진행할 수 있습니다.
📺 프로덕트화: 서비스 사용 및 운영을 위한 Product화 작업을 수행합니다. 이 단계에서는 모든 Task를 더 세분화하여 Sprint로 진행할 수 있습니다.
🧪 A/B테스팅 : 본격적인 실험을 수행하기 위한 작업 (이 영역은 비지니스 담당자 및 PM과 함께 진행)
👀 결과분석 : A/B테스팅 결과 분석을 포함하며, 모델이 추가적으로 develope 되어야 하거나, 추가적인 action이 필요한 경우에도 Task가 생성될 수 있다.
Task를 프레임워크로 구성했기 때문에 실제로 작업단위는 Task아래의 Sub-Task로써 존재하게 됩니다. 이 Sub-Task에는 이전과 마찬가지로 자유로운 이름으로 생성될 수 있습니다. Sub-Task도 Task와 층위만 다를 뿐, Jira 프레임워크상에서는 Task와 동일하게 취급되고 관리되기 때문에 아무 문제가 없습니다. 이제 정형화된 태스크를 관리하는 방식을 활용했을 때 어떻게 되는지를 보겠습니다. 아래에서 보는 것처럼 Jira의 로드맵을 통해서 한눈에 현재 Epic들의 진행상태를 볼 수 있습니다. 다시 말하면 Epic은 각각의 Project단위로 생각할 수 있습니다.
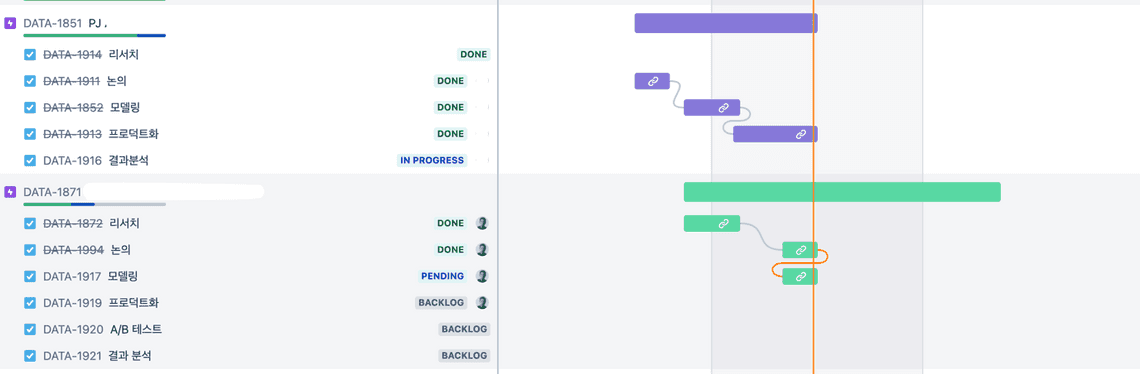
정형화된 Task의 장점은 그림에서 나타나는 것처럼, 현재 각 단계가 어떤 상태에 있으며(Backlog, Progress, Done) 얼마만큼 시간을 사용했는지를 확인할 수 있다는 점입니다. 실제로 소요된 시간으로 표시가 되는데, 저희 기준에서는 그것이 진행된 Sprint 기간을 의미합니다. 이제 보다 상세한 내용을 보기 위해서는 스프린트를 보아야 합니다.
스프린트
스프린트는 Jira에서도 가장 사랑받는 기능입니다. Agile 방법론에서도 많이 쓰이는 스프린트는 정해진 기간 단위에서 계획을 세우기 좋고, 리소스를 나눠서 작업하기 좋습니다. 물론, 누구보다도 프로젝트 매니저가 좋아하는 기능입니다. 왜냐면 스프린트는 끝나기로 한 약속이기 때문입니다. 그런데, 데이터 프로덕트와 스프린트는 어떤 면에서는 전혀 친하지 않습니다. 하나의 예를 들어볼까요. 딥러닝 모델을 개발중인데, Accuracy 90%를 달성하자고 목표를 세웠다고 봅시다. 이 달성을 하기 위해서 필요한 모델링 기간이 언제인지 사전에 알 수 있을까요? 물론, 숙련된 AI전문가라면 어느정도 예측은 가능하겠지만 많은 경우 그것은 단기간의 스프린트(예:1주)에 가능할지 예측하기 어려운 일이고, 무엇보다도 90%라는 성능이 서비스로 배포될 수 있는 목표치인지도 확실하지 않습니다. 이제 데이터 프로덕트와 스프린트는 친할 수 없다는 걸 알 수 있습니다.
좀 더 구체적으로, 일정을 정해두고 그 날짜에 맞춰서 모델링을 포함한 데이터 프로덕트를 만드는 일을 진행하는 상황을 생각해보겠습니다. ML엔지니어나 데이터사이언티스트는 초반에 데이터 준비작업과 Prototyping으로 시간을 많이 사용하였습니다. 그리고 나니 일정이 가까이 다가왔습니다. 운영을 위한 스케쥴러도 만들어야하고, 주피터로 된 시각화 및 리포트 문서도 만들어야 합니다. 이쯤되면, 모델의 성능이나 정교함은 뒤로한채 물건을 만들어내는 데에 모든 시간을 쏟을 수 밖에 없습니다. 그리고 어떻게든 만들어진 이 프로덕트는 PM에게 전달이 됩니다. 그리고 PM은 프로덕트의 기능을 테스트하기 위해 설명을 듣는 자리를 열었습니다. 기대했던 멋진 성능을 가진 데이터프로덕트는 보이지 않고, (PM의 입장에서는 당연한 기대였겠지만) 그저 작동하는 프로덕트만이 보입니다. PM은 이 성능으로는 100�만명의 유저가 사용하는 우리의 멋진 앱에 배포되는 것이 바람직 하지 않다고 말합니다. 그리고 이프로젝트는 Closing 됩니다(프로젝트 엔지니어들의 마음속에서는 Pending이겠죠)
이렇게 분명한 문제점이 있기 때문에, 데이터 프로덕트 프로젝트에 있어서 Sprint를 무조건 추구하는것이 가능하지 않고 효과적이지 않습니다. 때로는 재앙이 됩니다. 그럼 어떻게 해야할까요.
(여기서 잠깐 저희팀과 제가 운영하는 Sprint의 원칙을 같이 이야기하는 것이 도움이 될 것 같습니다. Sprint는 시간을 예측하고, 매주 목적을 달성해야 하는 개념이기 때문에, 매일 Scrum을 통해서 장애요인과 개발의 진척을 공유하고 Sub-Task의 완료를 스프린트 단위로 완성시켜야 합니다. 따라서 스프린트와 스크럼은 항상 같이 다니는 녀석입니다.)
스크럼-반 (스프린트(스크럼) + 칸반)
그래서 데이터 프로덕트팀에서는 Sprint(Scrum을 운영)와 함께 Kanban 형식의 프레임워크를 동시에 운영하기로 했습니다.
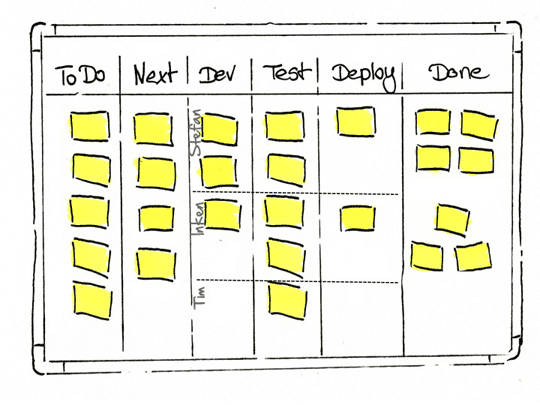
보다 정확하게는, PM과 명확한 의사결정을 내리고 개발에 돌입하기 전까지는 Kanban으로 추적하고,실제 모델링을 돌입해서 매일매일의 코드가 앞으로 나가는 상황이 되었을 때에만 Sprint를 시작하는 것입니다. 다시 앞에서 보았던 Jira Task를 관리하는 방식에서의 장점은 여기서도 강조됩니다. 리서치, 논의 단계에서 스프린트의 압박을 받지 않고 자유롭게 진행하되(그러니깐 위에서 언급한 Sprint의 규칙으로부터 자유로운 상태) 매주 이 상태가 얼마나 지속되었는지를 확인하는 방식으로만 관리됩니다. 보다 구체적으로 Kanban이라는 것은 [해야 할 일, 하고 있는 중인 일, 보류중, 완료] 등의 상태로써만 존재할 뿐이지 이것이 언제까지 완료되어야 한다는 약속은 하지 않는 것입니다.
달라진 것
분명하게 스크럼에 돌입하기 전과 후가 나누어질 수 있습니다. 그리고 스크럼이 들어가기전 단계인 리서치와 논의 단계에서는 시간에 구애받지 않고 자유롭게 Sub-Task를 구성해서 일할 수 있습니다. 필요하다면, 누군가와 같이 작업할 수도 있습니다. 충분히 준비가 되면 PM과 만나서(혹은 경우에 따라선 다른 비지니스 조직일 수도 있겠죠) 가능성을 보여주고 일을 진행하는데 필요한 의사결정을 얻을 수도 있습니다. 혹은 반대도 늘 가능합니다. 칸반 차트를 바라보는 모두가 이 작업이 너무 지연되고 있다고 느끼기 전까지는 말이죠. 일이 진행되기로 결정이되고 구체적인 목표와 방법론, Due가 확정된 이후 그러니깐 모델링에 돌입하는 단계에서부터는 엄격한 Sprint가 시작됩니다. 매일 스크럼을 하고 Project의 리더(매니저)는 일정을 관리하고 리뷰하고 매주 Agile하게 작업을 키워나갑니다. 팀의 모든 목표를 좋은 Data Product를 만드는 일이고, 새로운 Framework는 그것을 가능하게 하는데 초점이 맞추어져 있습니다. 어떤 도구가 그 것을 오히려 방해하는 경우라면 아무리 좋은 Framework도 사용할 필요가 없는 것이기 때문에, Jira를 우리의 목표에 맞춰 사용하기 위해서 이런 고민을 해왔습니다.
아직 남아있는 일들
분명히 Framework의 도입으로 여러명이서 작업해야하는 Data Product Project를 잘 관리하고 목표를 향해 나갈 수 있는 기반은 갖추어졌습니다. 하지만 여전히 몇 가지 개선할 것들이 남아있습니다.
- Project가 끝난 뒤에 Data Product의 관리
- 많은 데이터 프로덕트는 MVP 형태로 시작합니다. 데이터 프로덕트의 특성상 MVP에서는 일정한 수준의 정확도 같은 것을 만족 하는 것을 의미합니다. 하지만 코드의 리팩토링 이라던지 여전히 많은 부분들이 개선되어야 할 상태로 남아있습니다. 코드의 개선, 피드백을 통한 성능의 점진적인 보완 같은 것들은 누가 담당해야할 것인지 정해지지 않았습니다.
- PM은 유저스토리에 집중하고, 버그가 아닌이상 이런 데이터 프로덕트의 백로그들은 대부분 데이터 프로덕트를 만든 사람들이 가장 잘 알고 있습니다. 역설적이게도, 데이터프로덕트는 만든 사람들이 Owner가 되어야 한다고 생각합니다. 적어도 데이터 프로덕트 매니저라는 포지션이 일반화 되기 전까지는 말입니다.
- 따라서 데이터 프로덕트 개발자중에 한명이 Owner가 되는 일은 자연스러운 일입니다. Project가 종료된 이후엔 Onwer는 일정한 시간을 이 모델을 아주 점차로 고도화 시키는 작업을 진행해야 합니다. 당연하게도 이 부분에 있어서 역할이 애매한 영역이 아직 많이 남아있습니다.
- Project Planning
- 위와 비슷한 맥락입니다. 데이터 프로덕트라는 개념은 아직도 생소한 제품입니다. 많은 경우에 데이터 싸이언티스트나, ML엔지니어, Data Analyst가 아이디어를 먼저 내는 경우도 발생하고, 어쩌면 아이디어를 멋들어지게 기획하는 일까지도 해야할 수 있습니다. 기획에 대한 의사결정을 가지지 않은 데이터 직군이 이런 일을 한다는 것이 역시나 Grey Zone 에 있습니다. 앞에서 제시한 프레임워크에서
리서치와논의단계가 Kanban을 통해서 관리되어야 하는 이유가 바로 이것 때문입니다. 명목은리서치이지만 사실 이리서치에는기획이 포함되어 있다고 해도 과언이 아닐 것입니다. 데이터를 보고, 파이썬을 다루는 데이터 직군이 기획을 병행한다는 것은 결코 효율적인 상황이 아니기 때문에 이 곳에서도 또 다른 프레임워크가 필요할 것 같습니다.