Table Of Contents
이 글은 작성자 블로그에서도 보실 수 있습니다.
필자가 ML을 뉴스가 아닌 곳에서 제대로 처음들어본 곳은 대학원이었다. 대학원 기초과�목인 통계학 수업에서 갓 부임한 젊은 교수님은 머신러닝이 연구분야라고 하셨다. 머신러닝이 무엇인지 정확히는 몰랐어도 컴퓨터와 관련된 일이라는 것은 알았기에 통계학만 12년가량을 공부해온 교수님이 머신러닝이 연구분야라고 하신게 갸우뚱하긴 했다. 머신러닝이라는 단어 하나에 말똥거리는 원생들의 눈빛과 통계학자가 왜? 라는 듯한 미심쩍인 눈빛을 알아채셨는지 건조하고 퉁명스러운 말투로 말씀하셨다. “결국은 머신러닝도 다 통계학의 아이디어를 기반으로 하고 있습니다. 통계학자가 머신러닝을 연구하는 일은 자연스러운 일이죠.” 그 때 수업을 들었던 원생들은 각자 여러 길을 선택했지만 필자는 머신러닝도 곧 통계학이라는 믿음을 금과옥조로 여겼고, 약간의 고풍스러움 마저 간직한 이 단어를 데이터 싸이언티스트라는 이름 뒤에 슬쩍 감춰둔채로 이 일을 시작했었다.
그래서 오늘은 데이터 싸이언티스트, 그로쓰해킹, 딥러닝, 머신러닝, 마테크, 애널리틱스와 같은 용어뒤에서 묵묵히 자기 일을 하고 있는 통계라는 녀석을 주인공으로 만들어보려고 한다. 그리고 우리 분석가들은 어떻게 먼지 툴툴 묻어있던 잠든 보검들을 꺼내어 비지니스의 최전선으로 가져올 수 있었는지 몇 가지 이야기를 들어보자. 수 많은 이야기가 있지만 그 중에 필자가 아는 몇 안되는 재미있는 사례들만 소개할 뿐이니 독자들은 앞으로 더 많은 이야기들을 발굴할 수 있기 바란다.
첫 번째 이야기: 암환자의 생존율을 예측하던 모델이 고객 이탈 분석으로
Cox Proportional-Hazards Model(Cox, 1972)은 원래 병원 연구에서 시작되었다. 암환자에 대한 실험을 관찰해야 하는데, 어떤 환자들은 중도에 실험에서 이탈하기도 하고, 실험이 종료되는 시점에서 관찰 대상(예를 들면, 병이 다 나았는지 혹은 환자가 생존하였는지)의 결론이 나지 않는 상황이 발생할 수 밖에 없었다. 실험에 참가하는 환자들은 각기 투약하는 시점이나 치료 기간이 달랐기 때문에 censoring 문제도 발생하였다. 모델이 발전하는 과정에서 유용한 분포들도 사용되었는데 이를테면 이항분포를 역으로 취한 Negative Binomial이라던지 Zero-Inflated Possion 분포 같은 것들이 사용되었다.
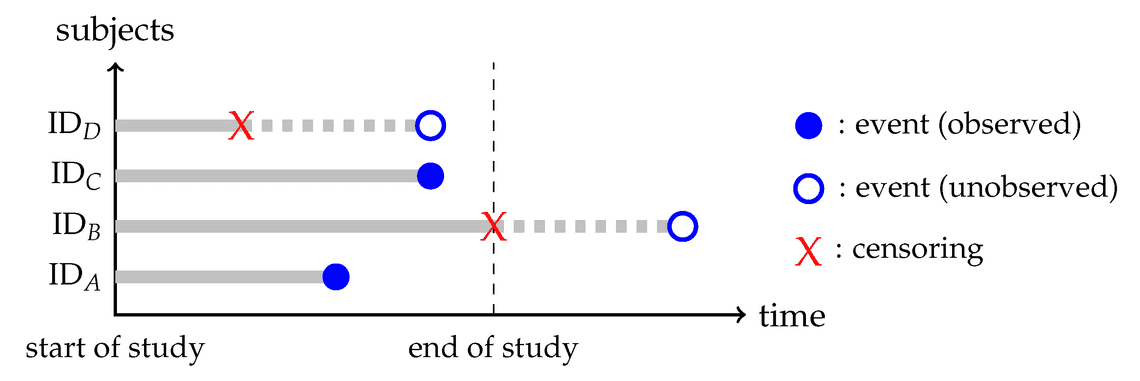
꽤나 오래된 이 모델은 고객 이탈 예측이라는 도메인에서 종종 사용된다. 이탈이라는 상황에서 분석가가 관찰 하는 시점에서 실제 고객이 이탈되었는지 여부를 모두 확인 수 없는 right censoring 개념이라던지, 중도에 데이터 유실이라던지 하는 어떤 사유로 이탈을 확인할 수 없는 상황도 유사하기 때문이다. Bayesian 추론이 발달한 지금과 같은 환경에서는 더 많은 가설을 탐색할 수도 있게 되었다. Zach Angell의 분석을 참조해보자.
두 번째 이야기: 주성분분석(PCA)에서 추천으로
통계학 커리큘럼의 뒤쪽에 등장하곤하는 PCA는 처음 접할 때는 매우 흥미롭지만 선형대수가 익숙하지 않으면 약간 헷갈리는 주제다. 이 주제는 분포 같은 것을 다루는 것이 아니라 행렬의 회전이라는 개념을 사용해서 데이터를 단지 다른 관점에서 바라보도록 만들어졌다. 하지만 이 과정에서 특정한 feature들에 의미가 더 많이 담기는 장점이 생기는데 이런 방식은 우리가 데이터를 2차원이나 3차원으로 표현할 수 있게도 해준다. PCA는 보다 넓은 의미에서 SVD(Singular Vector Decomposition)과 관계가 있는데 SVD도 PCA와 마찬가지로 행렬을 특정한 성분을 기준으로 재구성할 수 있는 역할을 한다. 재미있는 것은 PCA와 같은 알고리즘이 산업 분야에서 널리 사용되기 시작한 것은 이미지나 음향의 압축과 같은 도메인이었다는 점이다. 원본에 대비해서 약 70~80%에 해당하는 양의 정보를 유지하면서도 매우 효과적으로 데이터 양을 줄일 수 있었기 때문이다. (대략적으로 말하면 실제로 데이터는 20~30%만 사용해도 품질의 70~80%를 유지할 수 있었다는 의미다.)
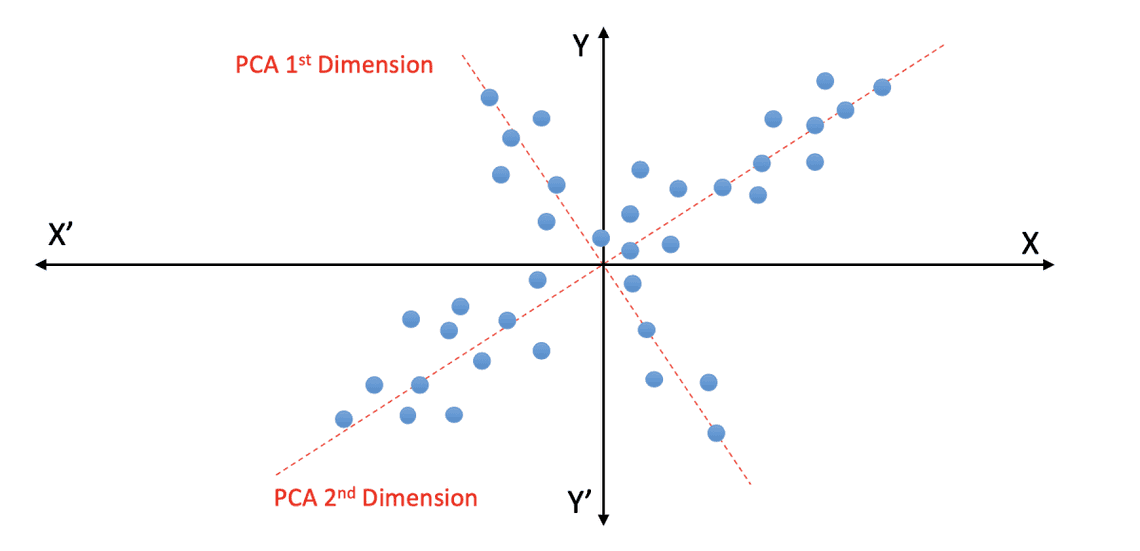
그리고, 이 PCA와 SVD는 아마존과 같은 e-commerce나 Netflix와 같은 컨텐츠 시스템에서 매우 유용하게 도입되었다. 이른바 Matrix Factorizatoin 시스템이라는 것이 도입된 것이다. 아주 간단히 이야기하면 유저가 어떤 이유로 어떤 선택을 하는지에 대한 표현을 축약할 수 있게 된 것이다. 그리고 축약된 정보를 토대로 우리는 특정 유저가 아직 선택하지 않은 어떤 상품이나 컨텐츠에 대해 어떻게 반응할지도 예측할 수 있게 되었다.

세 번째 이야기: Instrumental Varibale, 2SLS
도구 변수는 엄밀하게는 계량경제학 -특히 노동경제학- 에서 연구되고 사용되어온 이론이다. 계량경제학은 통계학이 경제학을 만나서 탄생한 학문이니(개인적인 이해입니다) 통계학과 밀접한 관련을 가지고 있다. 도구 변수가 사용된 유명한 도메인은 대학 입학이 임금에 미치는 영향을 연구한 오래된 Card,1995에 잘 나타나 있다. 대학 입학이라는 변수 요인에는 원래 공부를 열심히 하는 사람들이라는 내재 요인이 포함되어 있어서 임금을 설명할 수 있는 단일한 변수가 될 수 없었기 때문에 이를 대체할 수 있는 도구 변수를 도입한 사례이다. 역시나 꽤나 오래된 분야이기도 하다.
제품 A/B 테스트 환경에서는 이런 상황이 많이 발생한다. 어떤 요소를 테스트하고자 하는데 그 테스트에 참여하는 유저들이 가지고 있는 내재적인 특성 때문에 테스트 하고자하는 특성을 정확히 분리할 수 없기 때문이다. 이 같은 상황에 있어서 어떻게 도구변수가 유용하게 사용될 수 있었는지에 관한 Usecase로는 PAP에서도 여러번 다루어졌다. Bonnie님의 블로그 참조. 계량경제학으로부터 유래하여 유용하게 제품 분석에서 사용되는 또 다른 유용한 사례로는 Granger Causality라던지, Conditional Independence Assumption 등이 있다.
그리고 머신러닝: Non-Linear Models
마지막으로 소개할 이야기는 머신러닝이다. 여기에는 딥러닝도 포함이 된다. Decision Tree는 많이 알려진 머신러닝의 초창기 방법론이다. 그런데 이 모델을 선형모델로 생각해본적이 있는가? 비슷하게 Anova Test를 선형모델로 생각해본적이 있는가? Anova Test는 두 집단에 관한 분산분석이라고 한다. 그런데 각 집단에 대해서 0과 1이라는 이항 변수를 도입하면 Linear Regression으로 표현할 수 있다. 마찬가지로 Decision Tree도 비슷한 맥락에서 아주 많은 이항 변수로 이루어진 선형 모델로 해석할 수 있다. 10개의 Tree를 가진 Decision Tree 모델은 10개의 이항 변수로 이루어진 Logistic 모델과 다르지 않다.
그럼 딥러닝은 무엇일까? 딥러닝은 분명 컴퓨터의 XOR 논리 모델에서 시작한 것이 맞다. 0과 1이라는 문제를 처리하기 위해서 고유한 신경 모델을 사용한 것이다. 하지만 이것은 통계학의 관점에서 바라보면 Non-Linear 모델이다. 딥러닝에서 풀고자 하는 문제는 선형 모델로써는 풀 수 없는 문제이기 때문에 비선형 기법으로 풀고자 하는 것이다. 물론 비선형 모델에서 통계학이 어떤 기여를 하고 있는지를 여기에서 다 이야기하긴 어렵기도 하고 필자도 잘 알지 못한다. 하지만 최근에 딥러닝 논문들을 보면 딥러닝의 뉴런이라는 개념(weight으로 표현된다)에 있어서 이 값들을 추정하기 위해 다양한 통계적 기법들(i.e. MLE, Autoregression)이 동원되는 연구들을 지속적으로 관찰할 수 있다. 통계학에 대한 탄탄한 지식이 없다면 논문을 읽고 이해하기 어려운 것은 물론이다. 딥러닝의 많은 모델들은 예측에서부터 자연어모델, 추천에 이르기까지 많은 분야에서 사용되며 제품을 분석하고 개선하는데 큰 도움을 줄 수 있다.
단 몇 가지 사례를 소개했을 뿐이지만, 통계학이 최근의 데이터 싸이언티스트와 분석가들에게 든든한 무기가 되어주는 사례는 무수히 많다. 때로는 50년이 지난 이론이 사용되기도 하고(여러 분포에 관한 모델들), 가장 최신의 연구결과들이 사용될 수도 있다(딥러닝에 관한 통계연구들). 통계학의 많은 이론들은 제품의 분석에 있어서 매우 유용하게 사용된다. 마치 우주 전쟁이 한창이던 6~70년대에 활약하던 물리학자들이 우주 산업이 기울고 80년대부터 월스트리트로 향해 주식을 거래하며 활약하게 된 것을 Rocket Scientist라고 풍자했던 것처럼 현대의 데이터 싸이언티스트와 분석가들은 과거에 다른 영역에서 사용되던 통계학의 무기들을 곧잘 테크산업의 분석도구로 가져오는 것을 꾸준히 해내고 있다. 아무리 좋은 이론이 있었다고 해도 그것을 발굴하고 응용할 수 있는 것은 사람의 일이다.
서두에 등장했던 교수님은 원생들이 머신러닝이 아닌 통계학의 추상적인 이론만 배우는 것을 지루해하기 시작하자 학기 중반 어느때쯤에 작은 울림을 던지기로 했다. “통계학이란 결국 세상을 이해하는 하나의 철학입니다.” 필자는 그 믿음도 역시 가져왔다.