Under the Hood of Uber’s Experimentation Platform
Experimentation, 실험은 우버의 고객 경험 개선의 핵심입니다. 우버는 앱 디자인을 개선하기 위해 새로운 기능들을 시도하는 것만큼 다양한 실험 방법들을 적용하곤 합니다. Uber’s Experimentation Platform(XP)는 이 과정에서 중요한 역할을 수행합니다. 우리가 시도하는 새로��운 아이디어나, 제품 기능, 마케팅 캠페인, 프로모션, 머신러닝 모델과 같은 것들의 출시, 디버깅, 측정, 모니터링을 가능하게 합니다. XP는 우버의 driver, rider, eats, freight 서비스에서 이루어지는 실험들을 지원하고, A/B/N 실험, 인과추론을 하고, Multi-Armed Bandit(MAB) 기반의 실험들을 하기도 합니다.
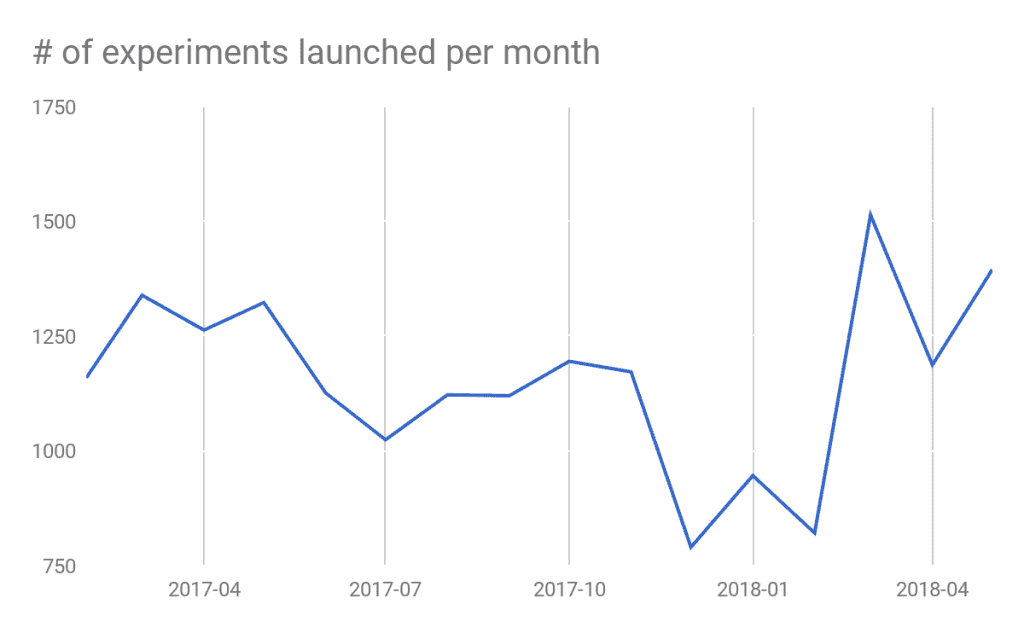
보통 1,000개가 넘는 실험들이 XP에서 진행되곤 합니다. 예를 들어, 우버가 새 Driver 앱을 출시하기 전에, XP에서 여러 단계의 실험들에서 광범위한 가설 검정들이 이루어졌습니다.
우버의 XP는 엔지니어들과 데이터 사이언티스트들이 Key Metric의 회귀가 일어나지 않도록 처치효과를 계속 모니터링 할 수 있도록 합니다. 또한 보편적인 Holdout을 구성해서 특정 도메인에 대한 장기적 관점의 실험을 가능하도록 합니다.
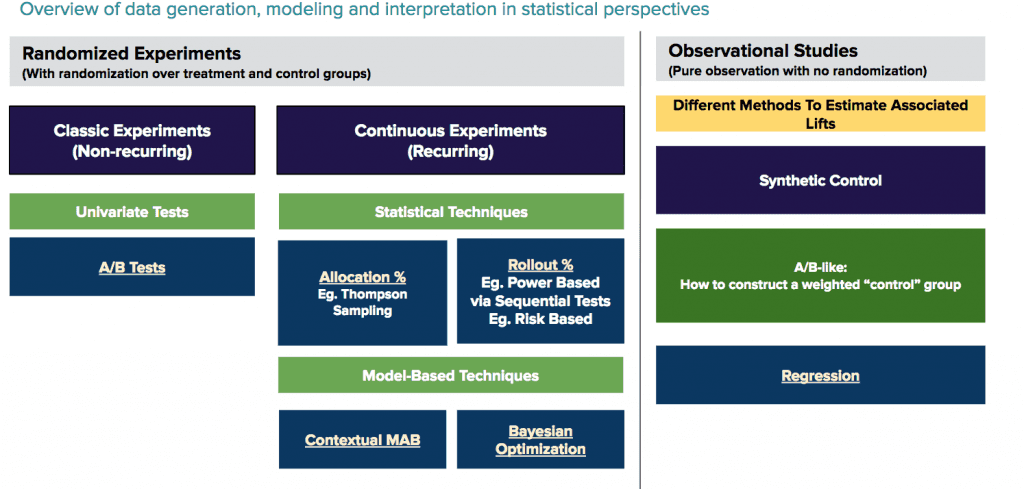
상황에 따라 적용해야 하는 통계적 방법론을 결정하기 위한 수많은 요인들이 존재합니다. 우리는 크게 네 가지의 통계적 방법론들을 사용합니다.
A/B/N 실험(T-test, 카이제곱 검정, 순위합 검정)
Sequential Probability Ratio Tests(SPRT)
인과추론 실험(인위적 통제와 실험-대조군 실험)
Bandit Algorithm들을 활용한 연속적인 A/B/N 실험(톰슨 샘플링, 상위 신뢰구간, 베이지안 최적화, 문맥을 반영한 Multi Armed Bandit Test)
우리는 Block Bootstrap이나 Delta Method 같은 방법들을 사용해 Standard Error들을 측정하고, 1종 오류와 2종 오류의를 계산할 때 Bias에 대한 보정을 측정하기 위해 Regression Based 방법론들을 사용합니다.
Classic A/B Testing
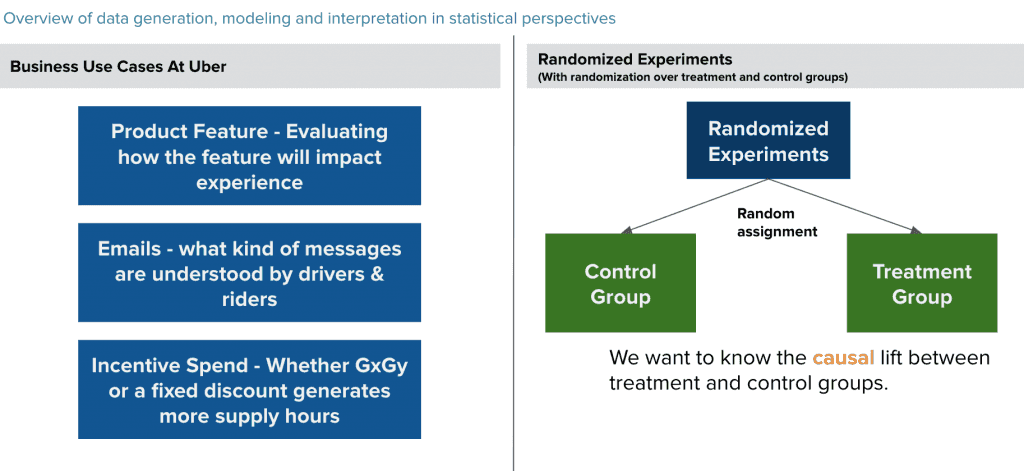
랜덤 A/B나 A/B/N 실험들은 정량적인 과학 분야에서 처치에 대한 효과를 측정하는데 가장 널리 쓰이는 방법입니다. 우버는 이 테크닉을 목적 지향적이고, Data-Driven하며, 과학적으로 정확한 프로덕트와 의사결정을 만드는데 활용합니다. 본질적으로, 전통적인 A/B Testing은 우리가 유저들을 랜덤하게 실험군과 대조군으로 나눠서 두 그룹의 Metric의 차이를 비교하고, 실험의 처치 효과를 정의할 수 있습니다.
fig3. 오버의 실험 플랫폼 팀은 향상도를 측정하기 위한 랜덤화된 A/B/N 실험을 설계합니다.
이 방법론은 일반적으로 기능 출시를 위한 실험에 활용됩니다. Product Manager가 새로운 기능이 우버 플랫폼의 만족도를 증가시키는지 측정하는 것을 가정해봅시다. PM은 우리의 XP를 다음과 같은 지표들을 수집하는데 활용할 수 있습니다. 대조군과 실험군에 대한 Metric의 평균값을 구하고, 처치효과가 명확한지, 그리고 샘플의 크기가 통계적인 검정력을 갖기에 충분한지.
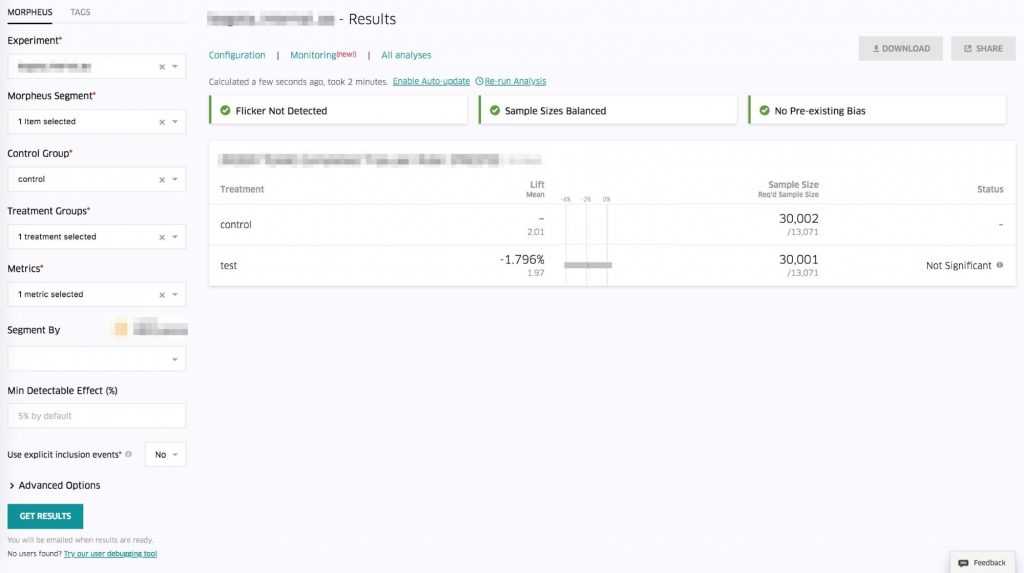
Statistics Engine
팀의 메인 목표 중 하나는 대부분의 가설 검정 과정에 적용되는 방법론들을 제공하는 것입니다. 통계적 엔진의 설계를 위해 다수의 이해관계자들과 함께했습니다.
랜덤화된 실험을 설계할 때, 첫 번째 단계는 Decision Metric을 정하는 것입니다. (라이더의 전체 예약) 이 선택은 검정할 가설과 직결됩니다. 우리의 XP는 실험과정에서 기정의된 Metric을 재사용하거나, 데이터 Handling과 Gathering, Validation을 손쉽게 재사용할 수 있도록 합니다. 통계 엔진은 Metric의 종류에 따른 통계적 가설검정 절차와 그에 따른 리포팅을 제공합니다. 우버에서는 이런 방법론들의 연구나 검증에 많은 투자를 하고, 통계엔진의 견고함과 효율성을 개선해나가고 있습니다.
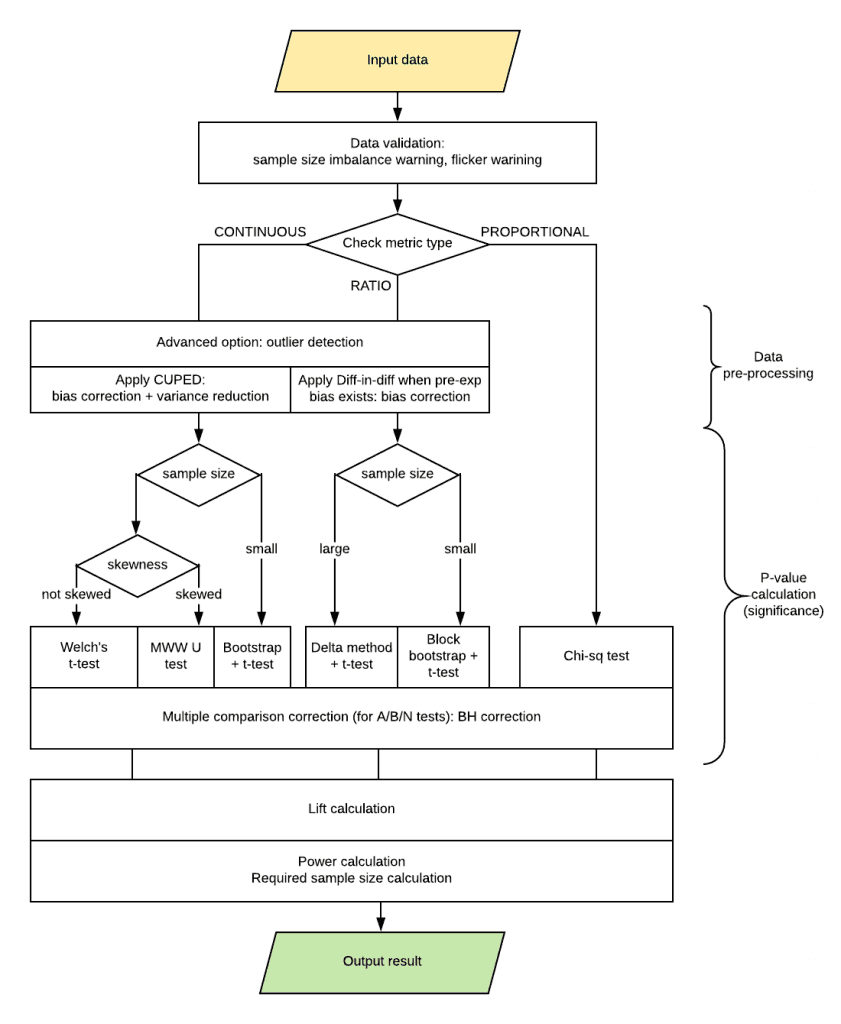
Key Components and Statistical Methodologies
데이터를 모은 뒤, 우리의 XP 분석 플랫폼은 데이터를 검증하고 A/B 테스트를 하는데 있어 중요한 지표 두 가지를 확인합니다.
Sample Size imbalance
실험군과 대조군의 Sample Size 비율이 분명한 차이를 보이는 것을 의미합니다. 이런 경우, 실험 과정 중 랜덤화 매커니즘을 점검할 필요가 있습니다.
Flickers
실험군과 대조군 사이의 이동이 있었던 유저를 의미합니다. 예를 들어, 한 라이더가 오래된 아이폰을 새 안드로이드 핸드폰으로 바꿨다고 합시다. 우리의 실험군은 IOS 유저들로만 이루어져 있었는데, 이 라이더는 핸드폰을 바꾸면서 실험군에서 대조군이 되었습니다. 이러한 유저의 존재는 실험 결과를 손상시킬 수 있기 때문에, 분석에서 제외할 필요가 있습니다.
우리 실험의 대부분은 랜덤화 과정을 거치고, 대부분의 시간에 따라 압축된 데이터는 A/B 테스트를 수행하기 충분합니다. 유저의 관점에서, 크게 세 가지 Metric이 존재합니다.
Continuous Metrics : 하나의 Numeric Column. Ex) 유저 당 예약
Proportion Metrics : 하나의 Binary Column. Ex) 회원가입 한 뒤 서비스를 한번 사용한 사람의 비율
Ratio Metrics : 분자와 분모 두 개의 Numeric Column. Ex) 서비스 사용을 완료한 비율. 여기서 분자는 서비스 사용을 완료한 사람들의 수이고, 분모는 총 서비스 요청한 횟수.
그리고 데이터의 견고함과 효율성을 향상시키기 위해 세 가지의 데이터 전처리 과정이 적용됩니다.
Outlier Detection : 데이터에서 규칙에 어긋나는 것을 제외하고, 분석 결과의 견고함을 향상시킵니다. 우리는 Outlier Detection과 그 제거를 위해 Clustering Based 알고리즘을 사용합니다.
Variance Reduction : 가설 검정의 통계적 검정력을 향상시키는 과정으로, 적은 유저를 대상으로 하거나 실험을 빠르게 끝내야 할 때 특히 효율적입니다. CUPED Method는 우리가 가진 정보를 최대한 활용하면서 분산을 감소시킵니다.
Pre-Experiment Bias : 이는 유저의 다양성 때문에 우버에게는 큰 도전입니다. 정량적 연구에서 Diff-in-Diff는 자주 사용되는 방법이며, 이전의 실험 결과의 편향을 바로잡고 믿을 수 있는 결과를 측정하기 위해 활용됩니다.
P-value를 계산하는 것은 통계적 엔진의 주된 일입니다. P-value는 XP가 이 실험의 결과가 유의미한지를 바로 결정할 수 있도록 합니다. 일반적인 A/B Test에서 P-value와 우리가 원하는 거짓 양성률(Type1 Error, 보통 0.05)을 비교합니다. XP는 P-value 계산 과정에서 여러 가지 절차들을 사용합니다.
Welch’s T-test : 연속형 변수에서 기본적으로 사용되는 Metric. Ex) 완료된 서비스
Mann-Whitney U test : 비모수 순위합 검정으로 데이터의 왜도를 검증하기 위함. T-test에 비해 가정들이 약하고, 비대칭 데이터에서 더 나은 검정력을 보임.
Chi-Squared test : Proportion Metric에서 많이 활용됨 Ex) 유저 리텐션 비율
Delta Method, Bootstrap Method : 적은 샘플 사이즈나 Ratio Metric에서도 견고한 결과를 내는 표준오차 측정 방식.
두 개 혹은 그 이상의 실험군이 있을 때, False Discovery Rate(FDR)을 통제하기 위해 다중 비교를 통한 보완방식을 사용합니다.
검정력 계산은 분석에 얼마나 확신을 가질 수 있는지에 대한 정보를 제공합니다. 실험이 낮은 검정력을 가질 경우 높은 거짓 음성률(Type2 Error)과 높은 FDR을 보일 것입니다. XP가 검정력을 계산하는 과정에서, T-test는 기본적으로 가정됩니�다. 필요한 표본을 계산하는 것은 검정력 계산과 반대되고, 높은 검정력을 갖기 위해 얼마나 많은 유저들이 필요한가를 측정합니다.
Metrics Management
XP에서 사용되는 Metric들의 수가 많아지면서, 실험에 적합한 Metric을 고르는 것이 점점 어려운 일이 되었습니다. 이를 위해 우리는 적합한 Metric을 추천하는 엔진을 설계했습니다.
우버에서, 컨텐츠 추천을 위해 일반적으로 두 가지의 협업 필터링이 활용됩니다. Item Base와 User Base입니다. 실험을 수행하는 사람의 특성이 프로젝트에 큰 영향을 미치지 않기 때문에 우리는 이미 Item-Based 추천을 활용해왔습니다. 예를 들어, 실험 담당자가 우버이츠 팀에서 라이더 팀으로 이동했다고 하면, 이 사람이 우버이츠 팀에서 했던 실험을 알고리즘이 반영할 필요는 없는 것입니다.
Recommendation Engine Methodology
두 Metric이 얼마나 연관되어 있는지를 측정하기 위해, 우리는 Popularity와 Absolute Score를 추가해, 관계를 더 잘 이해할 수 있도록 했습니다.
- Popularity : 실험에서 두 Metric이 많이 선택되었다면, 그 관계에 더 높은 점수가 부여됩니다. 이 때, 자카드 지수를 활용해 한 Metric을 골랐을 때, 그와 함께 빈번하게 활용된 Metric을 볼 수 있도록 합니다. 이 점수는 과거 실험에서 선택된 Metric들을 설명하기 위해 활용됩니다.
- Absolute Score : XP에서, 우리는 유저 샘플을 만들어 Metric에 대한 Pearson 상관계수를 계산할 수 있습니다. 이는 Serendipity를 설명하는데, 실험자는 처음에는 직접 연결된 Metric이 아니기 때문에 연결하지 않는 것을 고려했지만, 이 Metric에 따라 선택을 바꿀 수도 있습니다.
이 두 지표를 계산한 다음, 조합하여 처음 선택한 Metric에 따라 높은 점수를 보이는 Metric들을 추천해줍니다.
Insights Discovery
우버가 계속 성장함에 따라, Metric들을 지식 베이스로 유지하는 것은 점점 어려운 일이 되어가고 있습니다. 추천 엔진은 Global, Local 두 팀이 필요한 정보에 빠르고 쉽게 접근할 수 있도록 합니다.
예를 들어, 실험 담당자가 Driver-Partner의 공급 시간에 대한 처치 효과를 측정하고자 한다면, Metric으로 새로운 고객들의 서비스 이용 횟수를 Metric으로 추가할 필요가 있는지는 명확하지가 않습니다. 이 실험은 Driver에 초점에 맞춰져 있기 때문입니다. 사실 두 Metric은 실험에서 중요합니다. 우리의 추천 엔진은 데이터 사이언티스트들이나 다른 사용자들이 명확하게 보이지 않는 중요한 Metric들을 발굴할 수 있도록 지원합니다.
Sequential Testing
T-test와 같은 전통적인 A/B Testing이 반복된 Sampling에 따라 1종 오류를 부풀리지만, Sequential Testing은 비즈니스에서 중요한 Metric을 지속적으로 모니터링할 수 있는 방법입니다.
우리가 활용하는 Sequential Testing 중 한 가지 예는, 실험에 의해 발생하는 중단을 식별할 때입니다. 전통적인 A/B Testing이 이 중단의 원인을 찾기 충분한 Sample Size를 모을 때 까지 기다릴 수 없기 때문에, 우리는 실험이 Key Metric의 감소를 가져오지 않는다는 것을 확실히 하고자 했습니다. 따라서 실험 기간에 Sequential Testing 알고리즘을 사용해서 Type1 Error를 증가시키지 않으면서 신뢰구간을 조정하는 방법을 구축했습니다.
XP의 실험들에서 실험군과 대조군 사이의 App 충돌률이나 여행 빈도율과 같은 Metric들을 주기적으로 비교해나갔습니다. 유의미한 감소가 없을 때 실험은 계속되고, 그렇지 않으면 알림을 하거나 실험을 중단하도록 했습니다. 모니터링 시스템의 Workflow는 다음과 같습니다.

Methodologies
우리는 Metric을 모니터링하는 Sequential Testing을 하는데 있어 크게 두 가지 방법론을 사용했습니다.
Mixture Sequential Probability Ratio Test
우리가 모니터링에 가장 많이 사용하는 방법은 이 mSPRT라는 것입니다. 이 실험은 Mixing Distribution H를 포함한 우도비 검정을 바탕으로 합니다. 귀무가설을 라고 하면, 검정 통계량은가 됩니다. 우리는 큰 Sample Size를 가지고 있기 때문에, 중심극한정리를 적용할 수 있습니다. 이 혼합분포에 대해 정규분포 를 사용할 수 있는 것이고, 는 닫힌 형태로 사용됩니다. 유용한 것은, 귀무가설에서 nH, 0은 마팅게일()입니다. 따라서, 우리는 라는 신뢰구간을 구성할 수 있습니다.
Variance Estimation with FDR Control
Sequential Testing을 제대로 적용하기 위해, 분산을 가능한 정확하게 추정할 필요가 있습니다. 우리가 일 단위로 실험군과 대조군 사이의 누적차를 비교하기 때문에, 같은 유저의 관측치는 mSPRT의 기본 가정을 위반하는 상관관계를 만들어냅니다. 예를 들어, 클릭한 비율을 보면 한 유저가 몇 일간 클릭한 비율은 상관관계를 갖습니다. 이를 해결하기 위해, Delete-A-Group Jackknife Variance Estimation을 통해 연관된 데이터의 mSPRT를 일반화합니다.
우리의 모니터링 시스템이 현재 진행 중인 실험의 전반적인 상태를 체크하기 때문에, 동시에 많은 Metric들을 확인합니다. 이론적으로, 이런 상황에 Bonferroni or BH Correction가 적용될 수 있습니다. 그러나, 사업의 축소에 따른 잠재적 손실이 있기 때문에, BH Correction과 함께 파라미터를 조정합니다.
Use Cases
한 실험의 Key Metric을 모니터링한다고 해 봅시다.
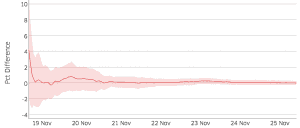
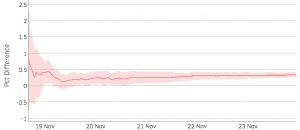
두 Plot의 붉은 선은 실험군과 대조군의 누적 차이를 의미합니다. 선을 중심으로 칠해진 영역은 인 누적차이의 신뢰구간을 의미합니다.
시간이 지남에 따라, 우리는 계속해서 샘플을 쌓고, 신뢰구간은 좁아집니다. 우측 Plot을 보면, 신뢰구간이 11월 21일 이후로는 0을 포함하지 않는 것을 볼 수 있습니다.
Continuous Experiments
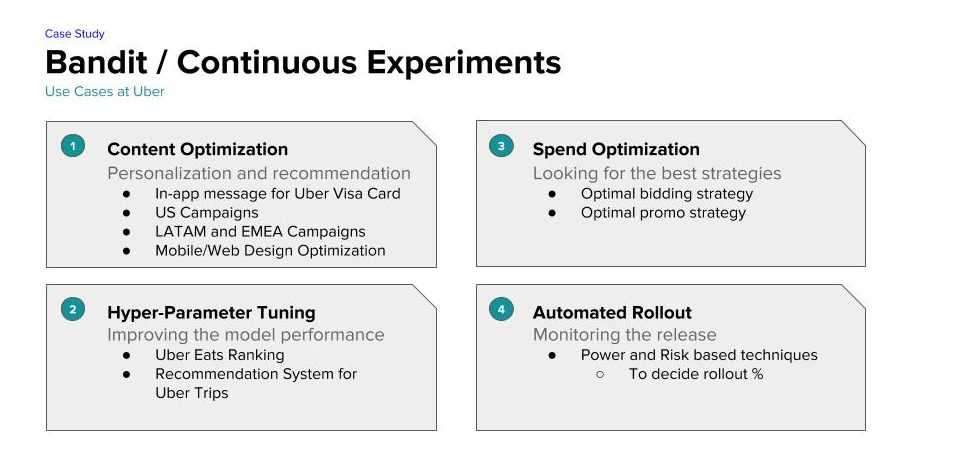
우버의 Data Science Team은 지속적인 실험을 통해 Driver, Rider, Eater, Restaurant, Delivery Partner들의 경험을 최적화하고자 합니다. 우리의 팀은 Bandit과 최적화 중심의 강화학습을 적용하여 Metric의 변화를 계속해서 학습할 수 있도록 했습니다.
최근, 고객 모집을 향상시키기 위한 컨텐츠 최적화 과정에 Bandit Technique을 사용했습니다. 이는 과거 가설검정 방식에 비해 고객 모집을 향상시키는데 좋은 성능을 보였습니다. 하단의 그림에 우버의 실험들을 보면 컨텐츠 최적화, 하이퍼 파라미터 튜닝, 비용 최적화, 배포 자동화가 있습니다.
Case Study 1을 보면, Bandit이 어떻게 Email-Campaign을 최적화하고 우버의 Rider 모집을 증가시켰는지를 볼 수 있습니다. 우버의 유럽, 중동, 아프리카를 담당하는 Uber Eats Customer Relationship Management (CRM)은 Email-Campaign을 통해 고객들의 주문을 증가시키고자 했습니다. 이 실험은 10개의 다른 이메일 제목을 만들어서 메일 확인 비율과 확인한 숫자를 통해 최고의 제목을 찾고자 했습니다.

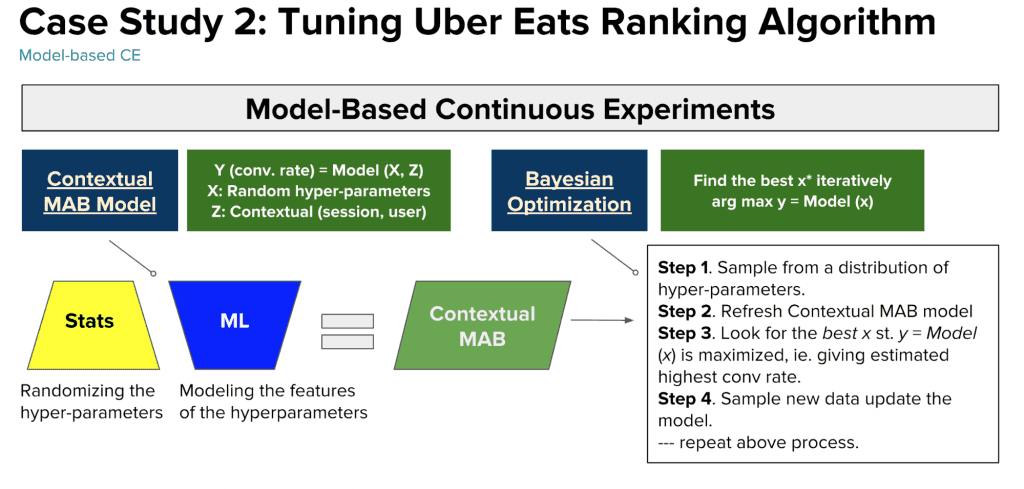
두 번째 예는 파라미터 튜닝입니다. 첫 번째 예시와는 다르게, 두 번째에서는 더 발전한 Bandit 알고리즘을 사용했습니다. 이는 통계적 실험과 머신러닝을 결합한 것입니다. 머신러닝 모델에서는 Contextual MAB를 사용해서 최고의 파라미터를 선택했습니다.
Data Science Team은 MAB를 Linear Programming Model을 만드는데에 사용했습니다. 이를 Multiple-Objective Optimization(MOO)라고 하는데, Uber Eats앱의 메인 페이지에 보일 식당을 정하는데에 활용되었습니다.

MOO의 알고리즘은 세선 전환율, 예약 비용, 유저 리텐션과 같은 여러 Metric들을 포함합니다. 그러나, 수학적인 솔루션은 알고리즘에 입력해야하는 파라미터들을 다 가지고 있습니다.
이 실험은 Ranking Algorithm에 활용되는 파라미터 후보들을 포함합니다. Ranking 결과는 우리가 MOO 모델에 입력한 하이퍼 파라미터에 따라 달라집니다. 따라서 MOO 모델의 성능을 향상시키기 위해서는 MAB 알고리즘을 통해 최고의 하이퍼 파리미터를 찾아야 합니다. 전통적인 A/B Test 프레임워크는 각각의 실험을 다루는데 너무 많은 시간을 필요로 하기 때문에, 우리는 MAB를 사용하기로 했습니다. MAB는 이 파라미터 튜닝에 빠른 성능을 제공합니다.
우리는 Contextual MAB와 Bayesian 최적화를 활용하여 Black Box Function의 Maximizer를 찾고자 했습니다. Bayesian 최적화는 개인화와 Exploration-Explotation 문제에서 잘 작동합니다.
Moving Forward
우리가 문제를 푸는 방법론들이 진화함에 따라, 더 똑똑한 실험 플랫폼을 만들 필요가 있었습니다. 미래에는 이 플랫폼이 현재의 문제 뿐 아니라 과거 혹은 미래를 예측한 Metric들을 바탕으로 인사이트를 제공할 수 있게 될 것입니다.