Table Of Contents
안녕하세요. 데이터 분석과 관련된 글들을 보다가 우버가 데이터를 어떻게 처리하고 다루고 있는지를 다룬 글을 우버 엔지니어링 블로그에서 발견했습니다. 우버에서는 데이터의 수집부터 적재, 활용 과정에서 어떤 방식이나 고려사항들을 가지고 있는지 보면 좋을 것 같습니다.
Introduction
데이터는 우리의 프로덕트에서 아주 중요합니다. 데이터 분석은 사람들이 우리의 서비스를 사용하면서 마찰이 적도록(frictionless), 즉 서비스를 더 효율적으로 사용할 수 있도록 합니다. 이는 우리의 엔지니어, 프로덕트 매니저, 데이터 분석가, 데이터 사이언티스트들이 정보 기반의 의사결정을 할 수 있도록 합니다. 데이터 분석의 영향은 우버 어플리케이션의 모든 화면에서 찾아볼 수 있습니다. 홈 화면에 무엇을 보여줄지, 어떤 상품을 보여줄지, 어떤 메세지를 유저에게 노출할지, 유저들이 왜 차량을 이용하거나 회원가입을 하는 등의 액션 중에 중단을 하는지 등등…
엄청나게 많은 유저와 수많은 피쳐들을 바탕으로 모든 지역을 지원하는 것은 복잡한 문제입니다. 게다가 우리의 어플리케이션은 계속해서 새로운 프로덕트로 확장해나가고 있고, 기저에 있는 기술들은 이를 발전시키고 지원할 필요가 있습니다.
데이터는 이런 것들을 가능하게 하는 중요한 도구입니다. 이 글에서는 특히 Rider Data에 집중해보고자 합니다. 우리가 어떻게 데이터를 수집하고, 처리하며, 라이더 어플리케이션에 어떤 변화들을 가져오는지를 소개하고자 합니다.
Rider Data
Rider Data는 Uber Rider APP과 Rider 사이의 모든 상호작용들을 포함합니다. 이는 매일 Uber의 온라인 시스템에서 발생하는 몇 백만개의 이벤트들에 대한 것인데, Rider APP에 활용하기 위해 몇 백개의 Apache Hive 테이블로 저장되고 있습니다. 우리가 데이터 분석을 통해 풀고자 하는 주요 문제로는, 유입된 유저의 Action을 이끌어내거나, 유저 유입을 증가시키거나, 개인화, 유저 커뮤니케이션 등이 있습니다.
Online Data Collection
Mobile Event Logging
Rider Data는 여러 가지 소스를 가지고 있지만, 메인은 유저가 APP과 어떻게 상호작용하는가를 캐치하는 것입니다. 유저 상호작용은 모바일의 Event Logging에 따라 기록됩니다. Logging Architecture는 몇 가지 원칙을 바탕으로 설계됩니다.
- Standardization of logs (로��그의 표준화)
- Consistency across platforms (iOS, Android, Web) (플랫폼 간의 일관성)
- Respecting user privacy settings (개인정보보호)
- Optimizing network usage (네트워크 최적화)
- Reliable without degrading the user experience (유저의 경험을 해치지 않음)
Standardizing Logs
수 백명의 엔지니어들이 로그를 생성하고 수정하는데에 관여하고 있기 때문에, 표준화된 로그 처리 방식을 구축하고 이를 따르는 것이 중요합니다. 클라이언트에서 기록되는 로그들은 자동화(유저가 UI와 상호작용하거나, 광고에 노출되거나 하는 등의 이미 정의된 이벤트들의 경우)되거나, 개발자들에 의해 수동적으로 추가되기도 합니다.
메타데이터의 기본은 일반적인 페이로드로 규정됩니다. 이는 위치, 앱 버전, 기기, 화면명 등과 같은 모든 이벤트마다 전송되는 데이터로 구성됩니다. 이는 백엔드에서 지표를 구성하는데에 있어 아주 중요합니다.
게다가, 플랫폼에 상관없이 이벤트들이 일관성을 갖고, 표준화된 메타데이터를 갖기 위해서 우리는 이벤트 모델들이 각자의 페이로드를 정의하도록 하는 절약적인 구조를 정의했습니다. 스키마는 각 플랫폼에 따라 다른 Event ID를 갖는 열거 자료형(서로 연관된 상수들의 집합)을 만들고, 이벤트의 발생에 따른 등록 시점에 필요한 페이로드 구조를 정의하고, 이벤트 타입을 정의합니다.
Publising Logs
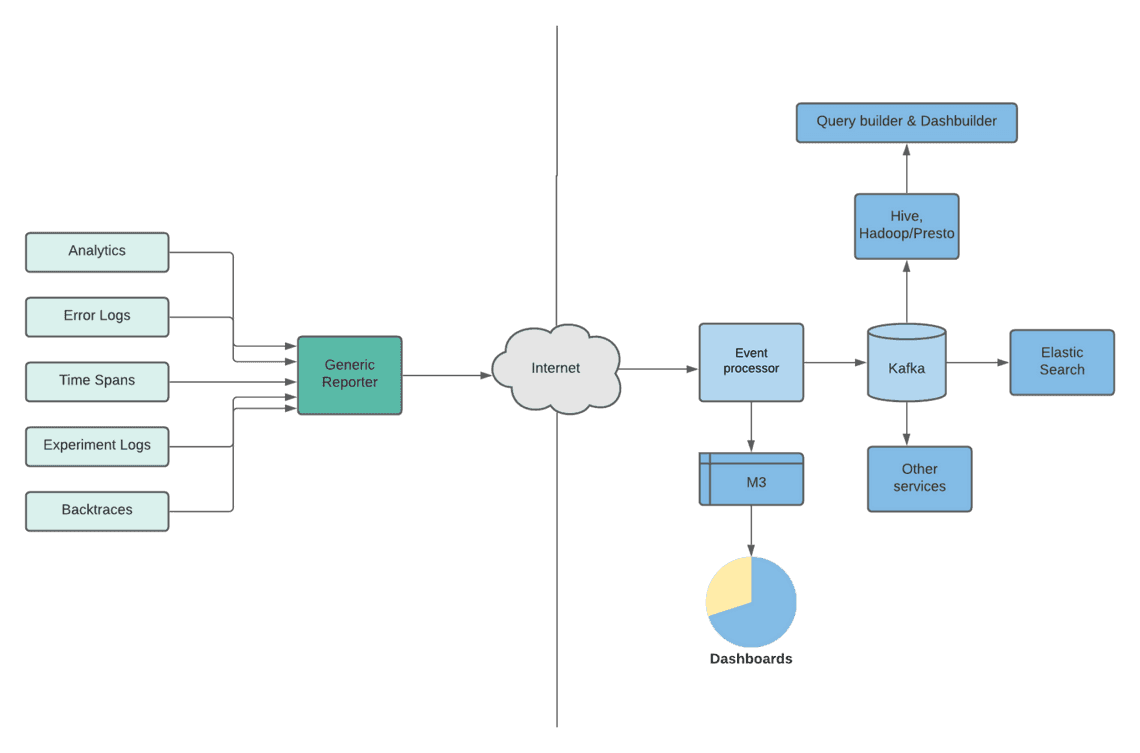
이 로그들은 통합된 수집체계로 수집되는데, 이는 클라이언트에서 만들어지는 모든 메세지를 처리할 수 있는 프레임워크입니다. 이 통합된 수집체계는 메세지를 하나의 큐에 저장하고, 모아서, 몇 초에 한번씩 일괄적인 양식에 따라 백엔드의 이벤트 프로세서로 전송합니다.
이벤트들은 계속해서 규모가 커지거나 변화를 반복합니다. 오늘도 수 백가지 형태의 이벤트들이 처리되고 있습니다. 빠른 성장의 또 다른 문제는 다른 OS 사이에서 로그를 맞춰나가고 필요 수준의 신호 잡음비를 유지해나가는 것입니다.
메타데이터를 기반으로, 이벤트를 수신하는 Event Processor는 이것이 어떻게 처리되고 전파되어야 하는지를 결정합니다. Event Processor는 또 이벤트를 계속해서 공급하고, 메타데이터와 매핑이 사용불가능하지 않는 한 이벤트를 하부구조로 전파하지 않습니다. 이는 신호 잡음비를 향상시키기 위한 노력이기도 합니다.
Backend Event Logging
유저 상호작용과 함께, 유저들에게 무엇을 보여줄지를 결정하는 것도 중요합니다. 이는 백엔드의 Service Layer로부터 데이터를 Logging하는 것으로 이루어집니다. 백엔드의 Logging은 모바일 기기에서 다룰 수 없거나 다루기에는 너무 큰 메타데이터를 처리합니다. 다른 시스템이나 모바일 기기에서 백엔드로의 요청이 이루어질 때 마다, 로그 데이터가 쌓입니다. 매 레코드들은 하나의 모바일 상호작용으로 묶이는 Key를 갖습니다. 이러한 구조는 모바일 대역폭이 효율적으로 사용될 수 있도록 합니다.
Offline Data Processing
Service Layer와 Mobile로 부터 수집된 데이터는 구조화되고 Offline Dataset으로 복제됩니다. Offline Dataset은 문제를 처음 단계부터 접근할 수 있도록 하고, 이를 다루기 위해 개발된 솔루션들의 성공을 측정합니다.
매우 크고, 처리되지 않은 Offline Dataset은 관리하기 어렵습니다. Raw Data는 계층을 가진 테이블 형태로 만들어집니다. 이 과정에서, 각기 다른 데이터셋이 Join 되면서 데이터의 의미를 확장해나갑니다. 구조화된 데이터는 다음과 같은 장점을 갖습니다.
- 리소스 절약(Resources Saving) : 한번 전처리된 후 저장되기 때문에, 다른 사람이 데이터를 활용할 때 크고 복잡한 Raw Data에 쿼리를 날릴 필요가 없다.
- 표준화된 정의(Standardized Definition) : 비즈니스 로직이나 평가지표는 ETL에 남고, 소비자는 그것에 대해 걱정할 필요가 없다. 만약 소비자에게 남겨지면, 모든 팀은 그것들 다르게 처리할 수 있다.
- 데이터 품질(Data Quality) : 모든 로직이 한 곳에 있고, 데이터가 쉽게 인증을 받을 수 있기 때문에 필요한 확인절차자 균형이 유지될 수 있다.
- 소유(Ownership) : 데이터가 발전함에 따라, 데이터의 소유권을 가진 사람이 새로운 Feature들을 추가할 수 있을지 없을지를 결정할 수 있습니다.
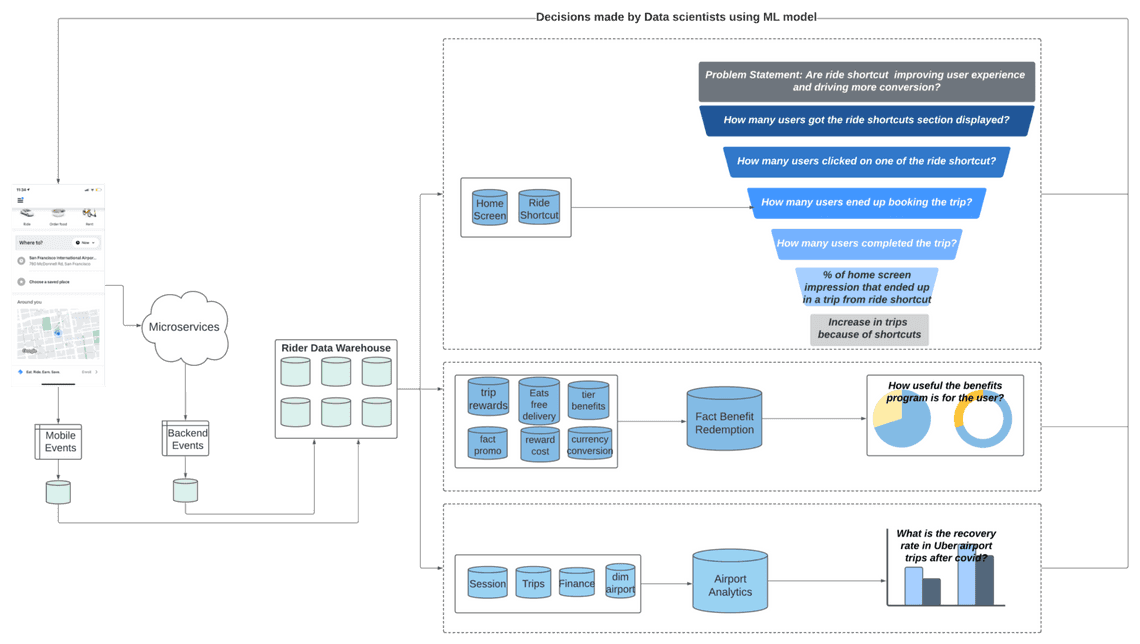
다음 두 가지 문제에 대해 생각해봅시다.
#1. Ride Shortcuts, 지름길이 라이더의 운행을 개선하거나 더 많은 수의 운전을 할 수 있도록 하는가?
유저들의 활동과 홈 화면의 컨텐츠를 기록하는 테이블이 지름길 정보 제공을 위해 사용됩니다. 이는 다른 데이터셋들과 결합하며 Funnel 분석을 할 수 있도록 합니다.
- How many users had the rider shortcut section displayed? (얼마나 많은 유저들이 Rider Shortcut 화면에 노출되었나?)
- How many users clicked on one of the shortcuts? (얼마나 많은 유저들이 지름길들 중 하나를 선택했나?)
- How many users (out of #2) ended up booking the trip? (2번 질문의 유저들을 제외하고, 얼마나 많은 유저들이 우버를 예약했나?)
- How many users (out of #3) completed the trip? (3번 질문의 유저들을 제외하고, 얼마나 많은 유저들이 ��서비스 사용을 완료했나? - 중간에 취소하지 않았는가하는 의미로 이해했습니다.)
- What percentage of home screen impressions that ended up as completed trips in ride shortcut flow vs. usual flow? (일반 길안내와 지름길 안내 사이의 사용 완료 비율은 얼마나 차이가 나는가?)
- What was the overall effect on trip booking from ride shortcuts? (지름길로 예약하는 것의 전반적인 효과는 어떠한가?)
#2. 보상 프로그램이 라이더들에게 얼마나 유용한가?
질문의 답을 찾기 위해, 우리의 데이터는 다음과 같은 구성을 필요로 합니다.
- 선택된/교환된 보상
- 기한이 만료되거나 사용되지 않은 보상
- 라이더들이 보상을 어떻게 얻게 되었나?
추가적으로, 흥미로운 데이터로는
- 보상이 전반적인 앱 사용을 증가시켰는가?
- 이 프로그램에 예산에 맞는 지출이 할당되었는가?
보상은 이츠, 라이드 그리고 다른 우버 어플리케이션들 사이에서 서로 다른 이득으로 전환될 수 있습니다. 유저가 어플리케이션에서 Benefit을 선택하면, 서버의 보상 서비스가 활성화됩니다. 이는 리워드 정보를 처리하고 각 리워드의 선택을 Transaction Data로 기록합니다. 몇몇 선택지는 자동 적용되나, 몇몇은 판촉을 필요로 합니��다. 시스템은 또 운영/프로덕트 팀에서 새로운 보상을 쉽게 추가할 수 있도록 설계되어 있습니다. 우리의 툴은 보상의 메타데이터를 기록하도록 했고, 다른 시스템의 데이터를 일괄적인 시스템으로 처리할 수 있도록 했습니다. ETL작업은 서로 다른 시스템의 데이터들을 읽어서 보상과 관련한 모델을 만드는데 사용합니다. 이 프로덕트에 대해 더 잘 이해하는 것 외에도, 이 데이터는 Finance 팀이 우버가 보상을 제공하는데 있어 얼만큼의 지출을 필요로 하는지 관찰하는 것을 지원합니다.
#3. Covid-19 이후 공항으로 가는 건의 회복 비율
공항에 대한 평가지표들은 몇 개의 테이블을 바탕으로 수집됩니다. 이는 여행, 세션, 재무, 공항과 기타 라이더 관련 테이블들이 포함됩니다. 서로 다른 도메인에서 수집된 데이터들을 바탕으로 평가지표를 계산하고, 테이블에 저장합니다. 수집된 과거의 데이터와 최신 데이터를 비교하여 우리가 풀고자하는 문제의 답을 찾을 수 있습니다.
공항 데이터는 물건 배송 시각화나 Gross Booking(우버 서비스를 이용하면서 우버에게 지불하는 금액) 데이터를 계산하는데 활용됩니다. 이는 우리의 서비스를 발전시켜나가는데 도움이 되는데, 각지의 수요를 충족시킬 수 있도록 하는 것 또한 가능하게 합니다.
Data Quality
데이터는 우리의 비즈니스 의사결정을 주도하는 어떤 신호를 줍니다. 따라서 데이터의 무결성과 품질을 유지해나가는 것은 아주 중요합니다. Rider Architecture에서 데이터의 품질을 체크하기 위한 여러가지 확인 사항과 단계들을 구축했습니다.
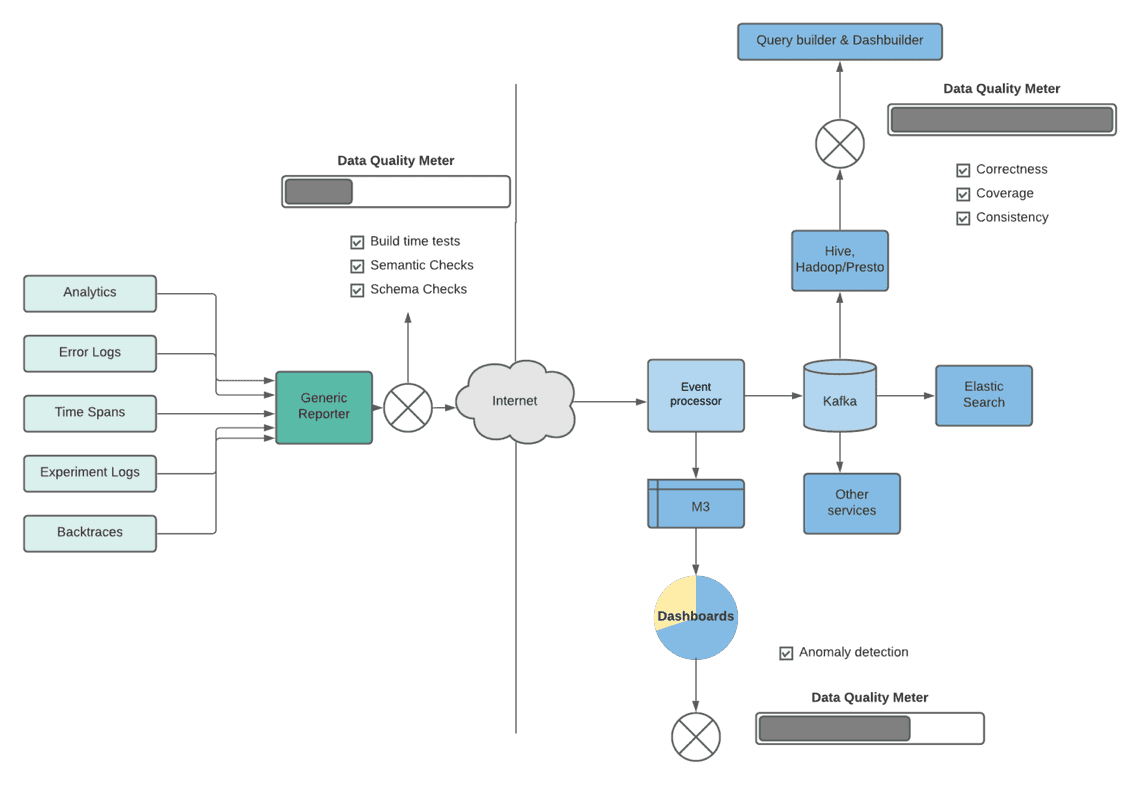
이벤트가 오프라인 저장소나 처리단계에 도달하면, 이상탐지 알고리즘이 정해진 절차에 따라 로깅되고 처리되는지를 감시합니다. 시스템 모니터는 이벤트들의 양을 확인하고, 갑작스러운 이상징후를 책임자에게 알립니다. 오프라인으로 모델링된 테이블의 경우 프레임워크를 통해 데이터의 정확성, 적용 범위, 일관성을 확인합니다. 또한 데이터가 서비스 수준 협약을 준수하는지도 계속해서 확인하는 절차를 거칩니다.
Evolution of the Uber Rider App
지금까지 소개했던 메커니즘을 바탕으로, 라이더 앱에 적용시킨 변화들은 다음과 같습니다.
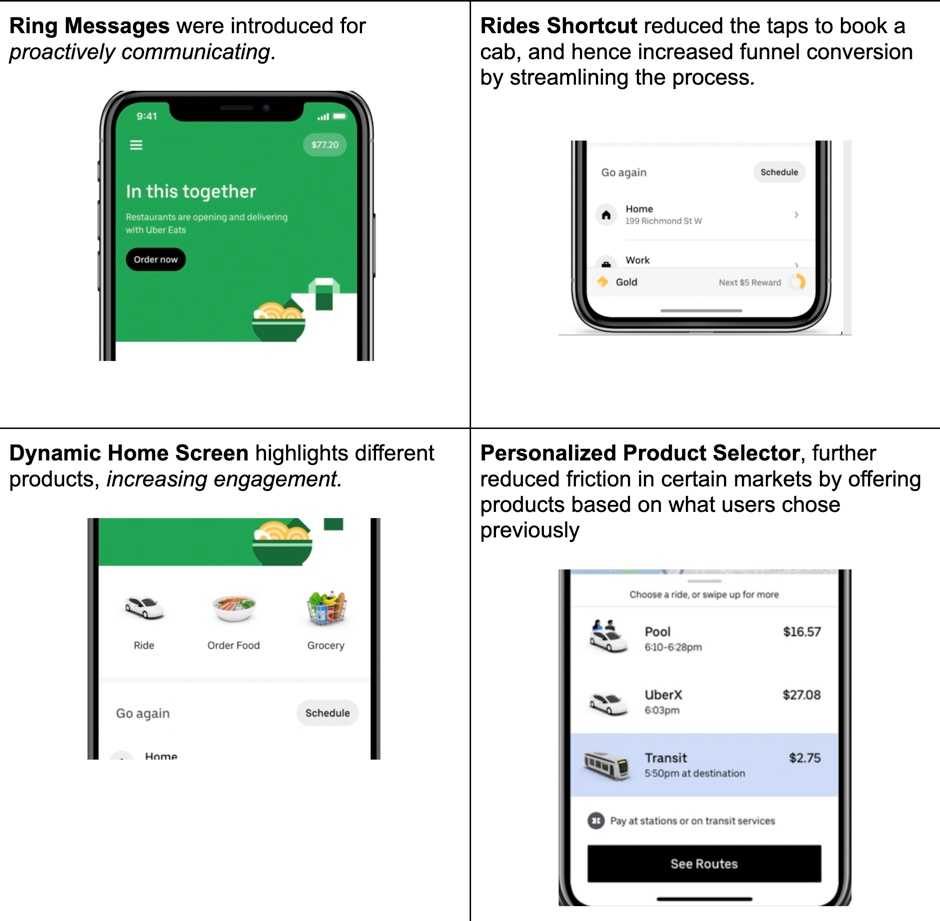
높은 품질의 데이터는 어플리케이션을 개선하는데 아주 중요한 도구입니다. 여러가지 방향이 있지만, User Retention으로 측정될 수 있는 유저들의 경험을 개선하거나, 성장을 하는 것이 중심입니다. 데이터는 또한 기능을 추가하는데 있어 어떤 것이 유저들의 경험을 해치지 않으면서, 가장 좋은 것인지를 이해할 수 잇는 열쇠입니다. 우리는 데이터의 중요성을 이해하고 있고, 우버에 더 나은 데이터 문화를 만들어 나가는 것에 집중하고 있습니다.