Table Of Contents
인과추론의 아이디어
인과추론은 특정한 처치 (treatment)가 결과 (outcome)에 미치는 인과적 효과를 파악하기 위해, 다른 조건들을 비슷하게 만들어주는 일련의 작업을 수행합니다. 핵심적인 아이디어는 “이 사람이 약 A를 먹고 감기가 나았는데, 만약 A를 복용하지 않았다면 어떻게 되었을까?”와 같이 반사실적 (counterfactual) 추론에 있습니다. 하지만 현실에서는 당연히 하나의 처치에 따른 결과만을 확인할 수 있기 때문에, 반사실적 결과를 결정적 (deterministic)으로 확인하는 것은 불가능합니다. 대신에 우리는 “잠재적 결과 체계 (potential outcome framework)”라는 도구를 통해, 관찰연구 상황에서도 몇가지 가정을 도입하면 반사실적 추론을 현실세계 안에서 오류없이 수행하는 것이 가능합니다.
몇가지 표기들을 정의하고 가겠습니다. 여기서 는 번째 개체가 받은 처치를 의미하고, 편의상 는 1 (treated) 혹은 0 (untreated, control)의 값을 지닌다고 하겠습니다. 는 번째 개체의 처치와 결과에 영향을 줄 수 있는 공변량입니다. 는 결과를 표현하는데, 만약 과 같이 표현한다면 이는 번째 개체가 해당 처치를 받았을 때의 잠재적 결과를 의미합니다.
위의 표기들을 바탕으로 잠재적 결과 체계 하에서 인과추론을 위한 가정들을 소개하겠습니다. 먼저 일관성 (consistency) 가정으로, 처치를 받았을 때의 결과는 그것의 잠재적 결과와 일치합니다.
위의 수식에서 이라면 이 되고, 이라면 이 되는 것을 확인할 수 있습니다.
다음으로는 조건부 교환가능성 (conditional exchangeability) 가정입니다. 적절한 공변량을 조건부로 했을 때, 잠재적 결과와 처치는 독립이라는 가정입니다.
이 두 가지 가정을 통해 우리가 관심있는 평균 인과 효과 (average treatment effect; ATE)라는 반사실적 추론의 결과를 현실의 수치들로 표현할 수 있게 됩니다. 표현상 편의를 거치면, 라는 공변량별로 처치를 받은 그룹과 받지 않은 그룹 평균의 차에 대해 가중평균을 구하게 됩니다.
하지만 본질적으로 반사실적 결과는 우리가 알 수 없어 가정을 도입한 것이기 때문에, 특히 조건부 교환가능성 가정이 만족되지 않는 경우 추론에 편향 (bias)가 발생할 수 있습니다. 오늘 글에서는 인과추론에서 발생할 수 있는 많은 편향 중에 세 가지를 확인해보고자 합니다.
교란 편향 (Confounding Bias)
“어떤 사람이 하늘을 보는게, 다른 사람도 하늘을 보게 만들까?” 와 같은 문제를 생각해봅시다. 실험이라면 외부 요인에 관계없이 하늘을 보는 행위를 처치하는 것이 가능합니다. 하지만 관찰연구라면 하늘을 보는 행위는 천둥과 같은 외부요인으로 인해 정해질 수 있고, 이런 외부요인은 단순히 처치에만 영향을 미치는 것이 아니라 다른 사람이 하늘을 보는 결과에도 영향을 미치게 됩니다. 만약 이런 외부요인을 고려한 적절한 보정이 이루어지지 않는다면, 교란에 따른 편향이 발생할 수 있게 됩니다.
이런 교란의 양상을 시각적으로 이해해봅시다.
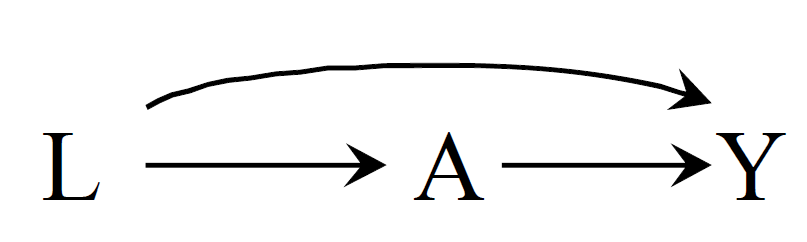
여기서 은 교란변수를 의미하고, 화살표는 변수간의 영향을 주는 방향을 의미합니다. 그래프를 보시면 교란변수 에서 나온 화살표가 처치 와 결과 에 모두 영향을 주고 있습니다. 이런 교란변수 을 보정해주지 않으면 잘못된 추론 결과를 얻게됩니다. 예를 들어 효과가 없는데에도 있다고 하거나, 실제 효과와 추정된 효과의 차이가 많이 나는 등, 정확한 효과 추정이 어렵습니다.
그렇다면 교란변수 은 어떻게 보정할 수 있을까요? 위에서 평균인과효과를 추정하기 위해 가중평균을 계산한다고 했었습니다. 만약 교란변수 이 그룹을 나타내는 변수라면 그룹별로 가중치를 갖는 평균을 계산할 수도 있습니다. 일반적으로는 교란변수 을 처치 와 함께 결과 를 예측하는 모형을 구축해서 효과 추정이 가능합니다. 이런 방식을 “outcome regression” 이라고 말하고, 이때 사용할 수 있는 모형은 간단한 선형회귀분석에서 머신러닝, 딥러닝 모형까지 모두 가능합니다.
교란의 경우 직접적인 교란변수가 아님에도, 특정 변수를 잘 보정하면 교란으로 인한 편향을 제거하는 것이 가능합니다. 다음의 그림처럼 측정되지 않은 교란변수 (unmeasured confounder) 가 있다고 생각해봅시다.
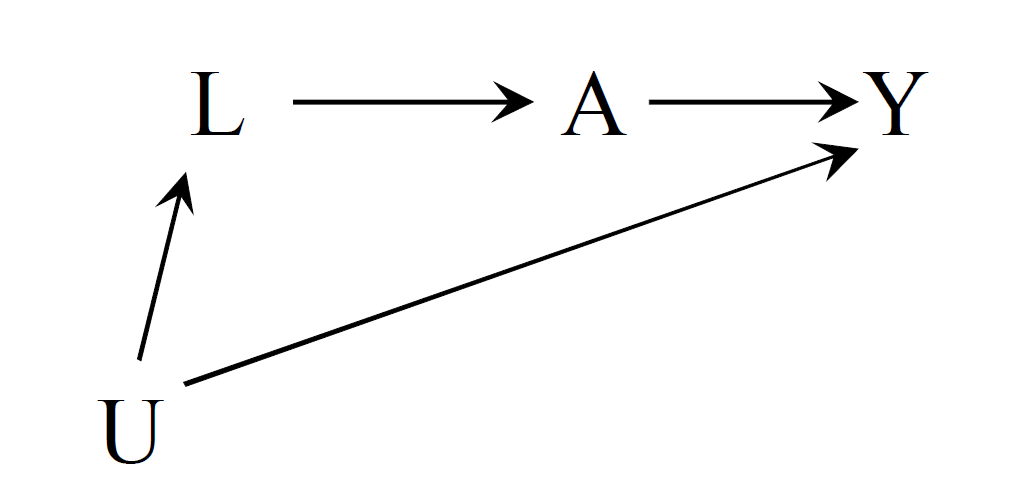
이 경우들에서 은 교란변수의 프록시 (proxy)로써, 교란변수를 설명할 수 있는 변수입니다. 이 변�수를 모형에 넣어서 보정하면 교란으로 인한 편향을 없애는 것이 가능합니다.
선택 편향 (Selection Bias)
이전에 하늘을 보는 예시를 그대로 가져옵니다. 하늘을 보는 행위가 다른 사람도 하늘을 보게 만드는지, 이에 대한 교란은 모두 보정되었다고 가정합시다. 하지만 해당 관찰연구에 참여한 사람들의 동의를 받아야 데이터를 수집할 수 있을 때, 수집과정에서 문제가 발생할 수 있습니다. 하늘을 보는 사람의 바로 앞에서 하늘을 본 사람은, 자신이 속았다는 생각에 데이터 수집에 동의하지 않을 수도 있습니다. 데이터의 이탈이 완전히 무작위로 발생하는 것이 아니라, 처치와 결과 모두에 영향을 받아 발생하는 경우가 존재할 수 있고, 이 경우 최종적으로 수집된 데이터만으로 진행된 추론은 “선택 편향”을 지닙니다.
이런 선택 편향의 예시들을 조금더 살펴봅시다. 금연클리닉이 금연에 미치는 인과효과를 확인하기 위해 흡연자들을 추적관찰했다고 생각해봅시다. 금연클리닉에 효과를 받아 점차 금연에 성공해가고 있는 사람은 꾸준히 연구에 참여할 것입니다. 반대로 금연클리닉에도 불구하고 여전히 흡연을 유지하는 경우, 해당 연구에서 중도이탈할 가능성이 큽니다. 만약 최종적으로 연구에 남은 사람들만을 대상으로 금연클리닉의 효과를 분석하면, 이탈한 사람들이 갖는 정보를 잃어 편향을 만들어냅니다. 이를 구체적으로는 missing data bias 라고 합니다. 다른 예시들로는 healthy worker bias, volunteer bias 등이 있습니다.
이런 선택 편향을 그래프로 표현하면 다음과 같습니다.
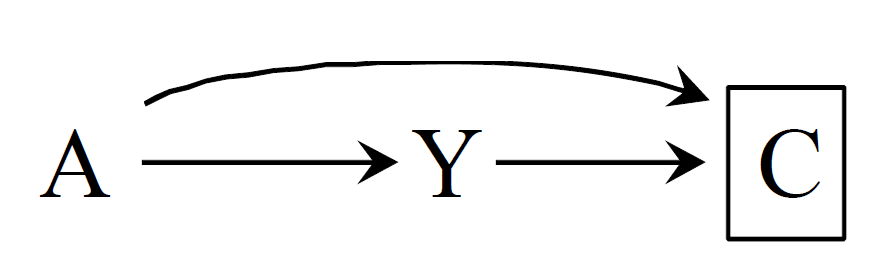
�여기서 는 선택편향을 유발할 수 있는 변수이자 조건입니다. 특정한 조건 (ex. 사망, 생존, 이탈 등)을 만족하는 표본을 통해 얻어진 결과는 편향된 결과일 수 있습니다. 이런 선택편향은 교란편향과 다르게 무작위 배정으로 해결되지 않습니다. 따라서 선택편향은 교란편향처럼 변수보정의 문제를 넘어, 어떤 표본을 얻을 것이냐에 대한 문제입니다.
Z-편향 (Z-Bias)
그렇다면 적절한 표본을 선정해서 교란편향을 유발할 수 있는 처치 이전의 공변량 (pre-treatment covariate)을 보정하면, 편향없는 추론이 가능할까요? 안타깝게도 인과추론에는 Z-편향 (Z-bias)라는 문제도 존재합니다. 다음과 같은 그림을 통해 파악해봅시다.
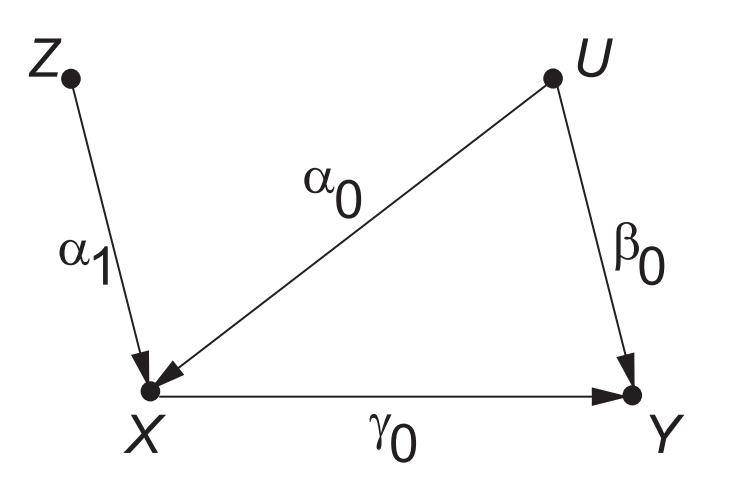
여기서 는 오직 처치 에만 영향을 미치는 변수로, 결과 에는 영향을 미치지 않습니다. 각각의 는 효과의 크기를 의미합니다. 만약 측정되지 않은 교란요인이 존재하는 경우 를 보정하게 되면 추론에 편향이 생기고, 보정하지 않았을 때보다 보정했을 때의 편향이 더 크다는 사실이 알려져 있습니다. 선형적인 효과에 대해 선형모형으로 추론을 진행했을 경우, 다음만큼의 편향이 존재합니다.
이러한 Z-편향은 측정되지 않은 교란변수를 고려하고, 사전지식을 통해 제거하는 것이 가능하기 때문에 실제 예시들은 많지 않습니다. 관련한 예시들은 Wooldridge (2010)에서 확인하는 것이 가능합니다. 따라서 인과를 추론하기 위한 상황에 대해 정확한 이해를 갖고, 보정의 대상이 되는 적절한 변수 집합을 식별하는 과정이 중요합니다.
Toward Less Casual Causal Inference
인과추론에서 존재할 수 있는 다른 편향들 중에 하나로 측정편향 (measurement bias), M-편향 (M-bias) 등이 존재합니다. 측정편향은 특정 도메인에서는 중요한 문제로 다뤄질 수 있는 사항이며, M-편향의 경우는 보정 여부를 식별하는 과정을 어렵게 만들기도 합니다. 더불어 인과추론에서는 피할 수 없는 측정되지 않은 교란요인로 인해 발생할 수 있는 위험이 내재되어 있습니다.
하지만 측정되지 않은 교란요인이 존재한다고 인과추론의 결과를 폄하할 수 있을까요? 측정되지 않은 교란요인의 존재는 관찰연구의 특징이며, 그 존재가 인과추론의 무용함을 말할 수는 없습니다. 중요한 것은 특징에 대한 재서술이 아니라, “특정 변수가 교란변수로써 역할할 수 있음을 추가적으로 고려할 필요가 있다”, “선택편향이 발생할 수 있는 연구설계를 가지고 있다” 와 같은 검증가능한 의견과 그에 대한 확인입니다. 이런 과정을 통해 “less casual causal inference” 를 달성할 수 있지 않을까요?
참고자료
- Hernán MA, Robins JM (2020). Causal Inference: What If. Boca Raton: Chapman & Hall/CRC.
- P. Ding, T.J. Vanderweele, J. M. Robins, Instrumental variables as bias amplifiers with general outcome and confounding, Biometrika, Volume 104, Issue 2, June 2017, Pages 291–302.
- Pearl J. (2011). Invited commentary: understanding bias amplification. American journal of epidemiology, 174(11), 1223–1229.
- Wooldridge, J. (2016). Should instrumental variables be used as matching variables? Res. Econ. 70, 232–7.