Table Of Contents
부제: 이거 쓰려고 신메뉴 한번 더 먹었다
개요
최근 점심을 위해 버거킹의 매장에 갔는데, 같이 주는 오프라인 특유의 종이 쿠폰을 보고 (마찬가지로) 최근에 공부했던 개념이 잠깐 떠올라 관련한 내용의 글을 작성해보려고 합니다.
쿠폰은 기업이 고객과 프로덕트에 대해 생각하는 전략적인 관점이 많이 드러나는 매체라고 생각하는데요. 저는 외식이나 오프라인 쪽 전략 혹은 마케팅 쪽에서 근무를 한 경험은 없기 때문에 제가 생각했던 것이 사실과는 다를 수 있으니 이렇더라가 아닌 이렇게 보는 관점도 있다 정도로 생각하시면 좋을 것 같습니다.
추가로 글에서 그룹과 세그먼트를 혼용해서 사용합니다.
이 글의 원본은 개인 블로그에 게시되어 있어서, 글의 레이아웃이나 이미지 배치가 제가 의도했던 원글과는 살짝 다르게 표현 될 수도 있습니다.
그룹을 나눠야 하는 / 나누지 않아도 되는 경우
우리의 프로덕트는 구매하는 고객이 다양하게 구성되어 있습니다. 프라이빗 컨설팅이나 주문 제작처럼 상대적으로 구매 고객이 정해져 있는 것이 아니라면 말이죠.
그렇기 때문에 모든 고객에게 동일하게 프로덕트를 전달하거나 프라이싱과 같은 전략을 취하는 것보다는, 각각의 고객에게 맞춰서 접근하는 방법이 “할 수 만 있다면” 더 좋은 선택입니다. (초개인화 라고도 하죠)
가령, 버거킹에서 구매를 하는 고객의 경우.
빠른 식사를 목적으로 하는 고객햄버거를 선호하는 고객버거킹이라는
브랜드에 충성하는 고��객버거킹과
가까운 위치에 있는 고객신메뉴가 목적인 고객쿠폰 사용이 목적인 고객가볍게커피 혹은 사이드 메뉴가 목적인 고객
등등 목적에 따라 다양한 그룹으로 나눠볼 수 있습니다.
이렇게 다양한 고객들에게 동일한 와퍼의 할인 쿠폰을 제공한다면, 쿠폰 사용율이 모든 고객에서 높기를 기대하는 것은 살짝 어려울 수도 있습니다.
이는 동시에, 전략 달성을 위한 쿠폰 발행에 들어가는 리소스를 더 효과적으로 쓸 수 있는 방법이 있다는 뜻이죠. 가령 외부 브랜드와 콜라보 중인 신메뉴를 더 많이 판매한다 (이 경우 와퍼가 아닌 신메뉴 쿠폰 발행) 와 같은 전략이 있을 수도 있습니다.
이론상으로 모든 고객 각각에게 ”초맞춤형” 전략을 취하는 것은 이른바 ”추천시스템” 의 목적이기도 한데요. 이번 글에서의 목적은 모든 고객에게 동일하게 하기와 모든 고객에게 맞춤 사이의 정도이기 때문에 이를 다루지는 않겠습니다.
아무튼 세그먼트 전략은 기술의 관점에서도 많은 챌린지가 필요하긴 하지만 할 수 만 있다면 괜찮아 보이는데요. 또 무조건 그렇지만은 않습니다. 세그먼트의 핵심은 그룹별로 다른 전략을 취한다 인데, 만약 다른 전략을 취할 수 없으면 세그먼트는 효과적이지 않고, 이를 위해 들이는 비용 대비 결과가 나오지 않는 거죠.
다른 전략을 취할 수 없다 라는 것의 예시는
- 알고보니 유의미하게 차이가 없는 그룹이었다.
- 그룹은 다르지만, 실제 운영의 차원에서 취할 수 있는 액션이 없다.
- 그룹은 다르지만, 비즈니스적 관점에서의 효과가 너무 작다. (Outlier 처럼 수가 적을 수도)
등이 있을 수 있습니다.
버거킹을 예시로 들어보면
- 40대와 50대를 각각 타겟으로 하는 쿠폰을 발행했지만 알고보니 두 집단에 큰 차이가 없었다.
- 국내 고객과 외국인의 구매 패턴은 다르지만 어플에서는 고객이 어느 집단에 소속하는지 알 수 없다.
- 비건 식사를 선호하는 고객이 그룹으로 나누어 지지만 수가 적어서 비건 와퍼를 만들 수 없다.
같은 예시가 있을 수 있습니다.

(마지막은 실제로 있던 일이기도 합니다)
아무튼 세그먼트
세그먼트 작업에 대해 위의 몇가지 체크리스트를 포함하여 여러방면으로 검토를 거쳤고 충분히 괜찮을 것 같다는 결론이 나왔습니다.
이제 실제로 그룹을 나누어 보려고 하는데요. 그룹을 나누는 데에도 몇가지 방법들이 있습니다. 그리고 당연하게도 각 방법마다 상황에 따른 장단점이 있습니다.
인구통계적 방법
개인적으로는 demographics 라는 표현이 조금 더 익숙한데요, 이 방법은 고객의 행동에 따라 나누는 것보단 고객이 이미 가지고 있는 개인적인 특성을 기준으로 나누는 것에 가깝습니다. 가령 연령이나 성별, 시간, 국가, 채널, 접속 기기의 형태 등 이미 정해져있는 것들을 주로 활용합니다.
장점으로는 행동을 활용하는 비중이 적기 때문에 이러한 데이터가 적은 신규 고객에 대해서도 기존의 그룹으로 바로 활용할 수 있다는 것이 있습니다. 뿐만 아니라 주요 요소들이 이미 정해져있기 때문에 모형을 만드는 것 (어쩌면 해석)도 상대적으로 쉽다고 생각합니다.
그러나 이를 위해서는 우리의 프로덕트의 life cycle에서 이러한 인구통계요소 수집 과정이 들어가 있어야한다는 전제가 붙습니다. (GA 같은 툴이나 회원가입과 같은 방법들로 이를 풀기도 합니다)
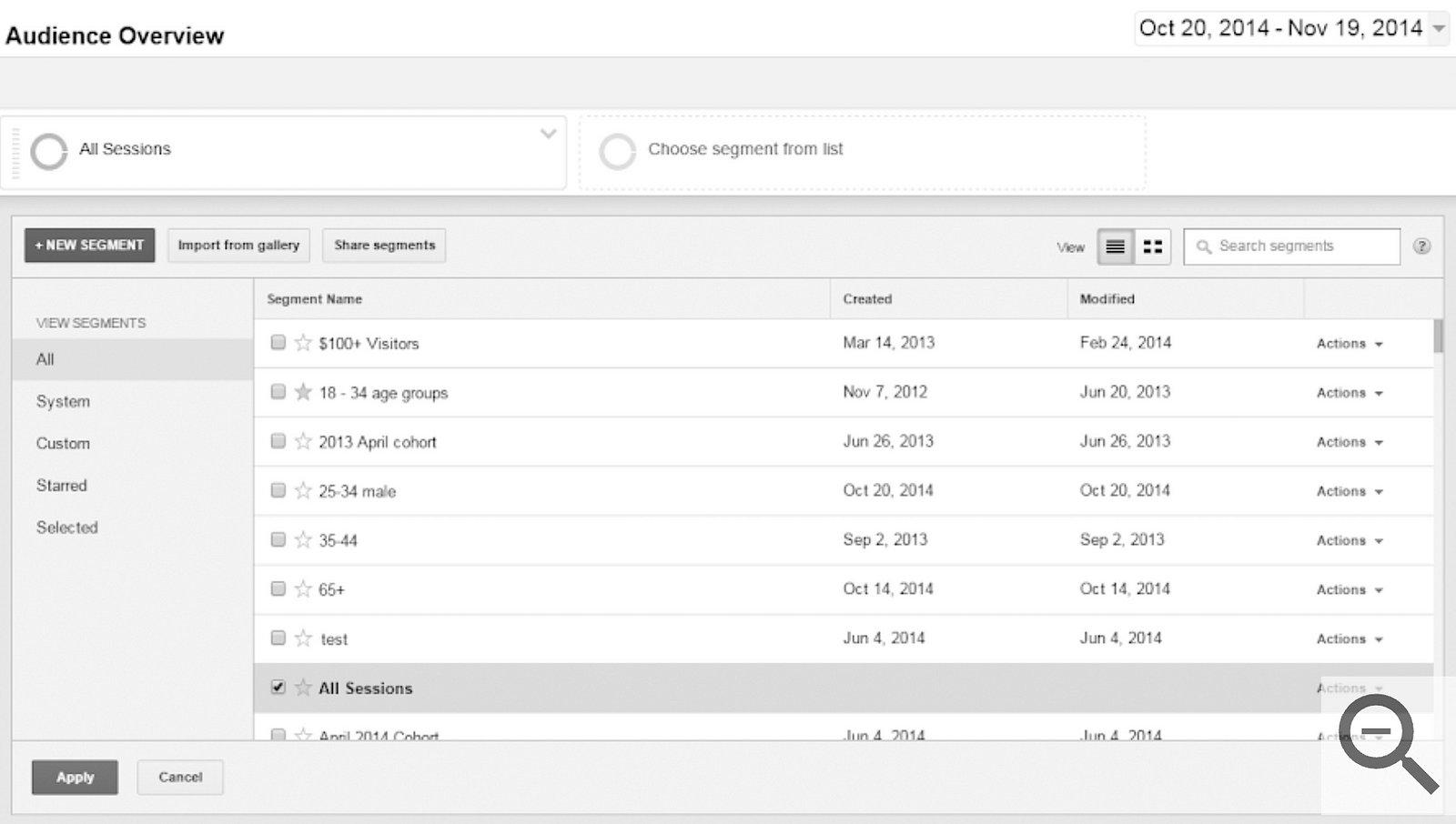
https://support.google.com/analytics/answer/3124493?hl=ko&ref_topic=3123779
기술적 방법
이번 방법은 약간은 이론적인 내용을 다루고 있습니다.
수집되고 있는 데이터가 있지만, 요인이나 행동패턴과 같은 컨텍스트를 활용할 수 없을 때 사용할 수 있는 방법으로 Unsupervised learning 혹은 Clustering 이라고도 많이 설명되고 있습니다.
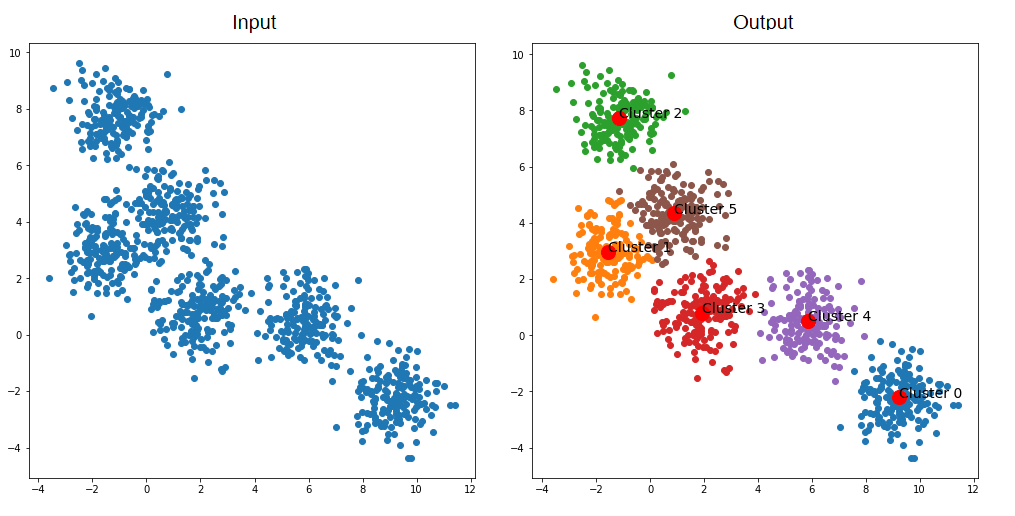
https://github.com/tranleanh/centroid-neural-networks
장점으로는 (어쩌면 단점) 컨텍스트를 활용하지 않기 때문에 그만큼 Bias로 부터 자유로울 수 있다는 특징이 있습니다.
그러나 이를 덮을 수 있을 만한 단점이 몇개 있는데요.
첫번째로는 클러스터링을 통해 그룹을 나누었어도 수치적으로만 나눠지지 실제로는 동일한 그룹일 수도 있습니다. 가령 X 라는 feature가 A와 B일때를 나누었지만, 사실 유의미한 차이가 없었다 와 같은 결론이 나게 됩니다. 그룹을 몇개로 나눌 것인가 라는 문제는 정말 어려운 문제이기도 하죠. 아무튼 이 경우는 2개 그룹을 동일하게 간주하는 것으로 해결 되지만, 더 곤란한 것은 동일한 그룹인데 패턴이 다른 경우입니다. 이 경우는 그룹을 더 세분화 할 수 있는 추가 데이터를 수집하는 것으로 해결할 수 있습니다. (어떤 데이터를 모아��야할 지가 문제입니다)
두번째로는 클러스터링 방법들도 정말 많은 방법이 있고, 각자가 잘 구분할 수 있는 데이터가 다르기 때문에 적합한 방법을 적용해야 더 큰 효과를 낼 수 있습니다. 즉, 많은 클러스터링 방법을 알면 더 좋다 라는 것이죠.
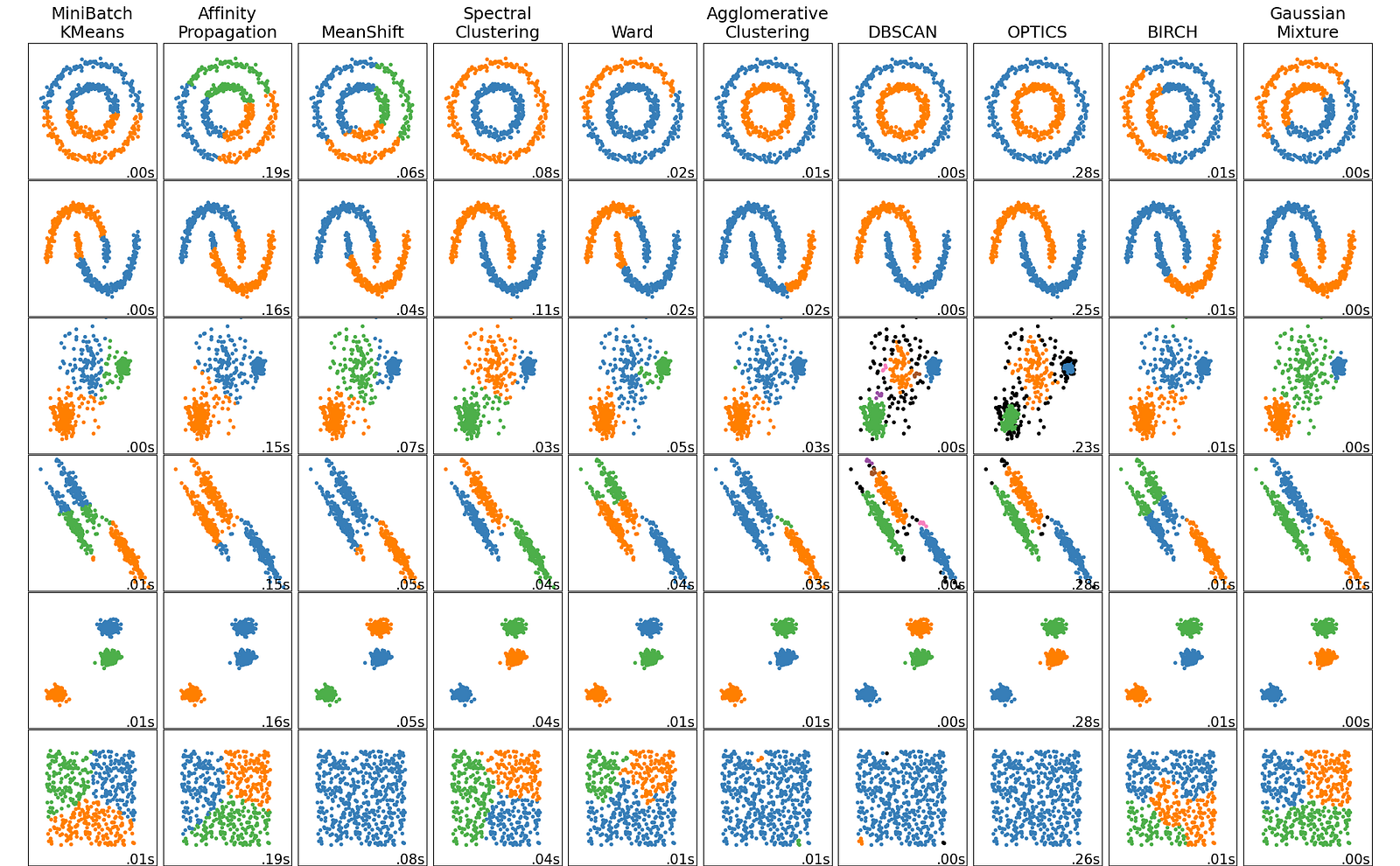
https://scikit-learn.org/stable/modules/clustering.html
어쩌면 가장 체감이 크게 될 수도 있는 세번째 단점입니다. 여러 차원의 데이터를 축소하거나 직접 클러스터링 작업을 할 수 있는 기술이 필요합니다. (아마 엑셀이나 SQL을 넘어서 Python과 같은 프로그래밍을 할 줄 아셔야 할 겁니다.)
뿐만 아니라 기술에 연관되어 있는 이론적 배경과 지식들도 필요하기 때문에, 데이터 분석가보다는 데이터 사이언티스트의 관점에서의 접근이 필요할 수도 있습니다.
행동적 방법
어떠한 항목을 정의하고, 수집해야 할지 고민하는 것과
이론과 기술을 활용하는 것도 괜찮은 방법이지만
(개인적으로는) 비즈니스상에서 나오는 고객의 행동 데이터를 바로 활용 할 수 있는 방법으로 빠르게 실행 해본다 라는 관점에서는 괜찮은 것 같습니다.
- Active / Passive (프로덕트에 대한 참여도) - Actor / Recipient (인터랙션에서의 액션 제공여부) - Positive / Negative (감성)
등의 여러 형태에 따라 구분 지을 수 있는데요. (저도 정확하게 아는 것은 아니지만, 몇몇 예시에서는 이렇게도 구분합니다)
조금 더 나은 이해를 위해 SNS 서비스를 예로 들어보면,
다른 유저에게 메세지를 보내는 것은 Active + Actor,
다른 유저의 글을 보는 것은 Passive + Actor
내 글의 다른 유저가 댓글을 달게 하는 것은 Active + Recipient
다른 사람이 내 포스트를 보게하는 것은 Passive + Recipient
와 같이 구분 할 수 있습니다.
장점은 가설을 기반으로 하기 보단 고객이 이미 해낸 행동을 기반으로 구분하는 것이기 때문에 마찬가지로 bias로 부터 조금 더 자유롭다는 것이 있고, 복잡한 기술이 필요하진 않습니다 (SQL로도 충분할 것 같아요)
물론 이러한 ��행동을 분류하는 방법을 알거나, 정해야 하는데 이는 굳이 사회학적인 접근까지 아니더라도 비즈니스 로직에 따라서 가능하며 이는 장점이 될 수도 있다고 생각합니다.
한편 유저가 프로덕트를 사용하면서 다른 그룹으로 넘어 갈 수도 있긴하지만 궁극적으로는 구매를 하는 고객 그룹으로 바꾸고자 하는 것이 우리의 목표이기 때문에 큰 문제가 되진 않습니다.
실제 예시
완전한 웹기반 서비스 까진 아니지만, 이러한 세그먼트 전략을 짐작할 수 있게하는, 제가 경험 했던 예시를 같이 공유해보려고 합니다.
저는 애용하는 버거킹의 할인 쿠폰을 앱과, 오프라인 종이 쿠폰, 그리고 카카오톡이라는 3개의 채널을 통해서 접했는데요. 알고보니 채널별로 전략이 다른 신기한 경험을 해서 이게 세그먼트별로 다른 전략이 아닐까 라는 생각에 이 글을 쓰기도 했습니다.


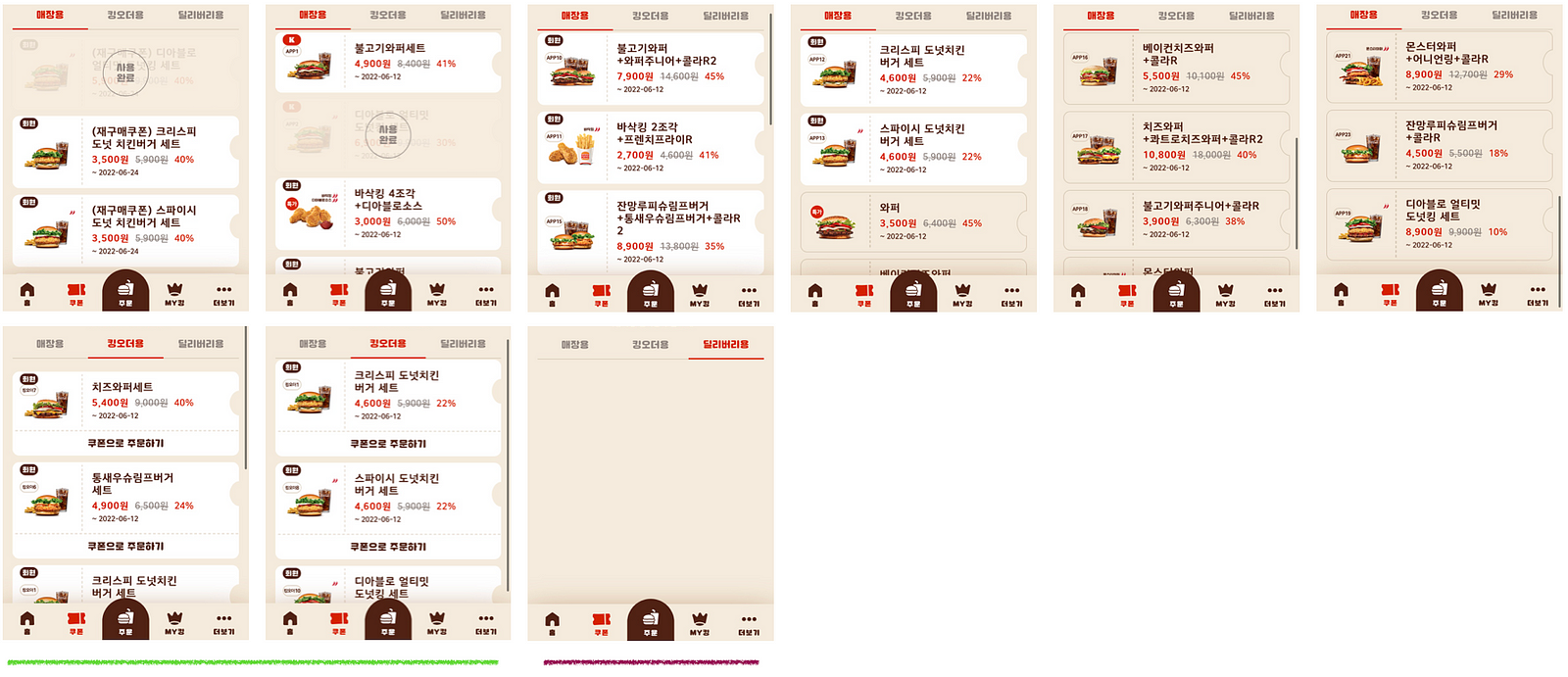
각 채널별 쿠폰 모음
이미지 편집이 오래걸렸지만…🥲 이미지로 보는 것은 의미가 많이 줄어들기 때문에, 정리한 표를 첨부했습니다.
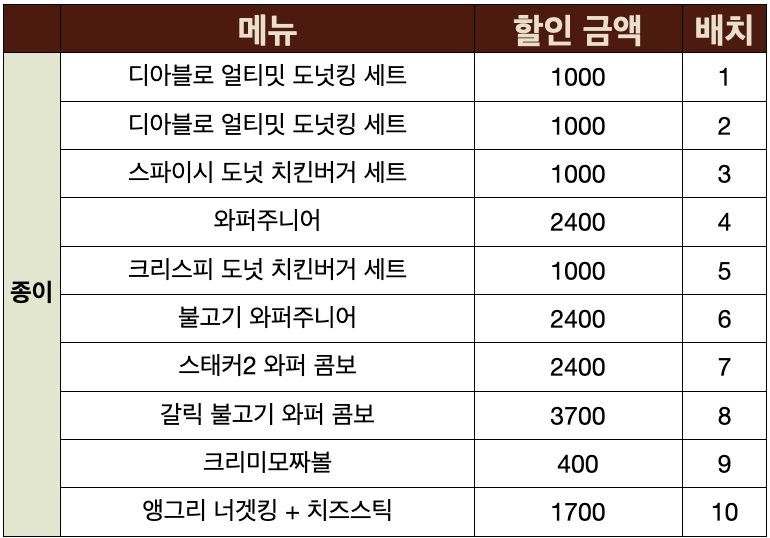
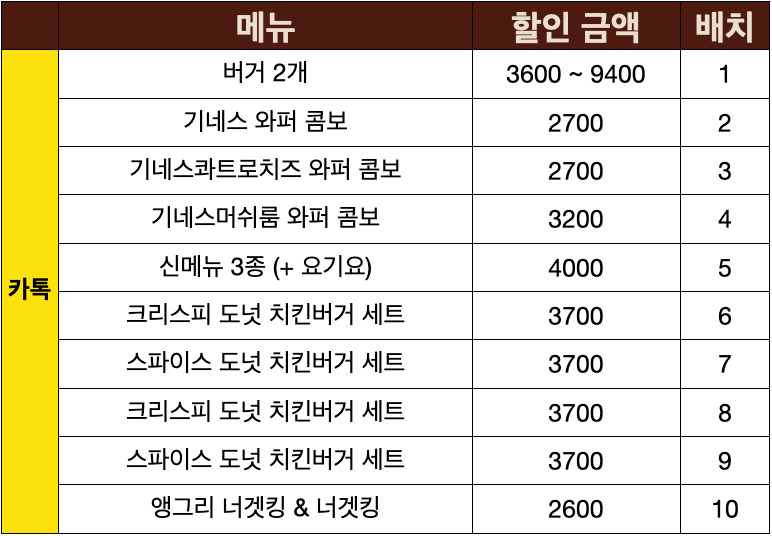
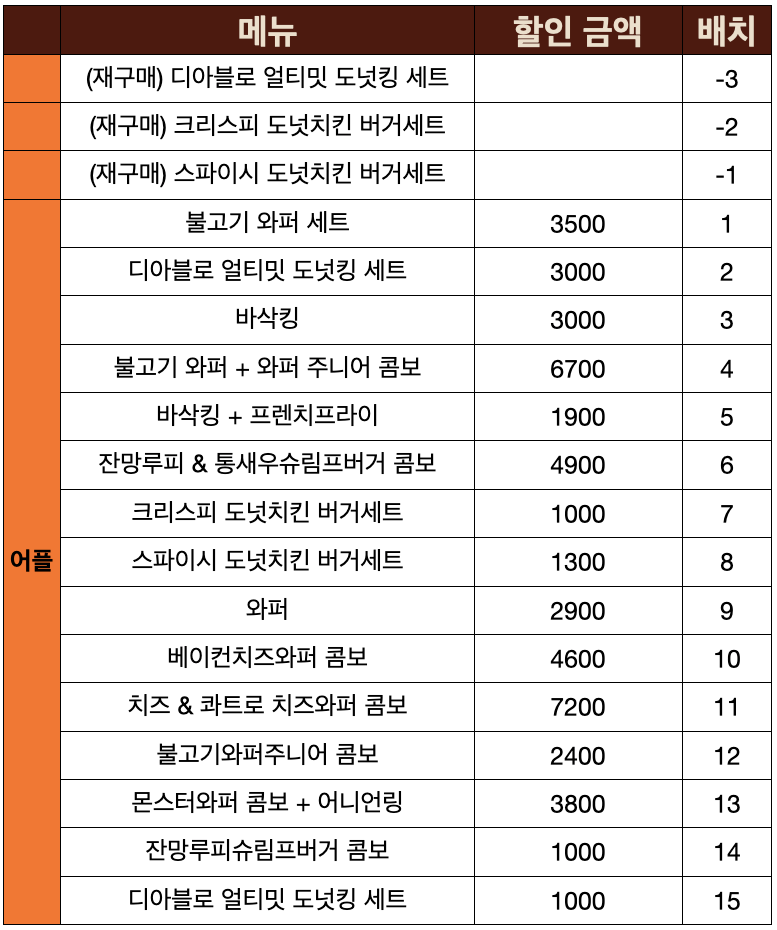
- 기간이나 실제 지불해야하는 금액도 표기하면 더 다양한 인사이트를 얻을 수 있지만 이는 하지 않았습니다.
- 어플에서의
재구매는 특정 쿠폰을 사용했을때 맨 위에 추가되었던 쿠폰입니�다
쿠폰의 특징
- 채널별 평균 할인 가격은 카톡 (3360) > 어플 (3213) > 종이 (1700) 순으로 달랐습니다.
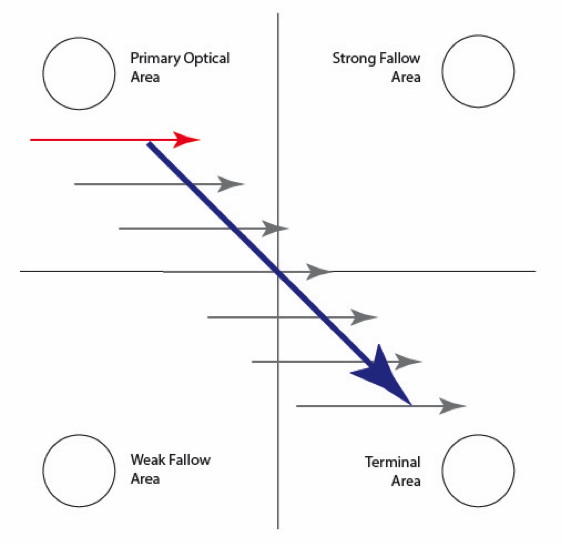
https://www.tales.co.nz/2018/08/15/part-1-reading-gravity-where-to-place-important-information/
채널별로 쿠폰 배치 우선순위 (Reading Gravity)가 달랐습니다 (위 그림 참조)
종이 (신메뉴 > 와퍼 주니어 > 와퍼 콤보 > 사이드)
카톡 (버거 2개 > 와퍼 콤보 > 배달 > 신메뉴 > 사이드)
어플 (베스트셀러 > 사이드 > 신메뉴 > 와퍼 콤보) 여기서 베스트셀러라는 표현은 제 뇌피셜입니다.
채널별 타겟 고객과 목적
종이 쿠폰의 경우 매장에서 구매를 한 모든 (
불특정) 고객들에게 트레이에 같이 나가는 것으로오프라인 재방문을 목적으로 하는 것이고, 어플은 자사 어플을 설치하고회원가입까지 한 로열티가 있는 고객이라는 특수성이 있기 때문입니다. (어쩌면 데이터를 활용 했을 수도 있습니다)한편 카톡의 경우는 신메뉴 외에도 기네스 버거라는
특정 품목에 대한 할인을 제공하고 있는데요. 카톡 유저의 어떤 특성이 이를 만들어냈는지는 모르겠습니다. 추가로대용량 주문에도 활용할 수 있는 쿠폰이 배치되어 있습니다.카톡과 종이의 경우,
쿠폰 발행 비용이 어플에 비해 상대적으로 비싸기때문에 (종이 인쇄 + 카톡 연동) 어플이 훨씬 더 유연한 쿠폰 제공 정책을 가지고 있습니다.종이의 경우. 와퍼 주니어만을 제공하는 쿠폰이 있는데요,
조금만 먹는 것을 목표로 하는 고객을 대상으로 한것이 아닐까 생각합니다.카톡은 모바일의 특성상 (…?)
외부 배달 채널 (요기요)과의 연동할인이 있습니다. 이는 종이(오프라인)는 당연히 배달이 아니기 때문에 해당 없고, 자사 어플을 통해 배달을 하는 경우는 버거킹에서 자체적으로 배달을 진행하기 때문입니다.어플에서도 이전
구매 금액에 따라 추가로 고객 등급이 나뉘어지는데 이에 따라 발행되는 쿠폰이나 할인 금액이 조금씩 다를 수도 있습니다.

버거킹 유저 그룹 (뇌피셜), https://support.apple.com/ko-kr/HT208986
요약 & 정리
- 고객을 그룹으로 나눌 수 있는 상황에서는 나누는 것이 좋습니다.
- 세그먼트를 찾아내는 방법에는 상황에 따라 적용할 수 있는 여러 방법이 있고 각자 장단점이 있다.
- 버거킹이 어떤 방법을 통해서 (인구 / 기술 / 행동) 그룹을 나누었는지는 알 수 없지만 적어도 채널별로는 나누어져 있다는 것을 알 수 있었고, 그 채널 안에서도 여러 그룹의 고객을 대상으로 하는 전략이 있다는 것을 알 수 있었습니다.
- 세그먼트에 대해서 다루고 있는 다른 글을 추가 했습니다.