
이 글은 [소비자 데이터 기반 소비 예측 경진대회 (데이콘)] 에 참여한 저의 경험과 코드를 공유하는 글입니다.
데이터 분석을 공부하시는 분들 모두에게 도움이 되길 바라며 글을 작��성하였습니다.
해당 대회의 난이도는 basic으로 데이터 분석 공부를 시작한 지 얼마 안 된 분들이 가볍게 참고하실 수 있도록 작성하였습니다. EDA 혹은 모델링이 무엇인지 설명하실 수 있으신 분들께 해당 글이 도움이 될 수 있을 것이며, 데이터 분석에 대한 기본 개념을 정리하는 데 도움이 되길 바랍니다.
본 글에서는 글의 길이로 인해 축약된 EDA만 작성하게 되었으며, 데이터 분석에 필요한 최소한의 EDA만 진행 후 모델링을 진행하였음을 알려드립니다. 추가로, 데이터 분석을 실행하기 위해서는 일반적으로 더 많고 다양한 EDA가 이뤄져야 한다는 점을 참고 부탁드립니다.
5월 9일, 13일 이틀 동안 대회에 참가하였으며 다양한 피드백 및 의견은 언제나 환영합니다. :)
feature 설명
train.csv(학습데이터)의 feature(컬럼, 열 데이터)에 대한 설명입니다.
feature를 확인할 때는 데이터가 어떤 정보를 담고 있는지, 수치형 데이터와 범주형 데이터로의 구분, 전처리하기에 복잡한 feature가 있는지 등을 확인해주어야 합니다.
해당 데이터는 22개의 열로 이루어져 있으며, 소비자의 개인 정보와 구매 활동에 대한 정보를 담고 있는 것으로 보입니다.
각 컬럼의 설명을 보니 Year_Birth, Income, Recency와 같은 수치형 데이터와 Education, Marital_status, AcceptedCMP1~5 와 같은 범주형으로 구성된 것을 확인할 수 있습니다.
여기서 AcceptedCMP1~5의 경우 데이터가 0과 1이므로 수치형 데이터라고 생각할 수도 있지만, 0보다 1이 큰 것이 중요하다는 “숫자로서의 의미”는 없기 때문에 해당 데이터를 범주형 데이터로 보아야 합니다.
해당 데이터에서는 “리뷰”와 같은 텍스트 데이터 즉, 각각의 데이터가 모두 값을 가질 수 있는 데이터는 없어 보이므로 전처리가 복잡해지거나, 해당 feature를 삭제해야 하는 경우는 없어 보입니다.(이 문장은 해당 글에서는 이해하지 않아도 됩니다.)

데이터 불러오기
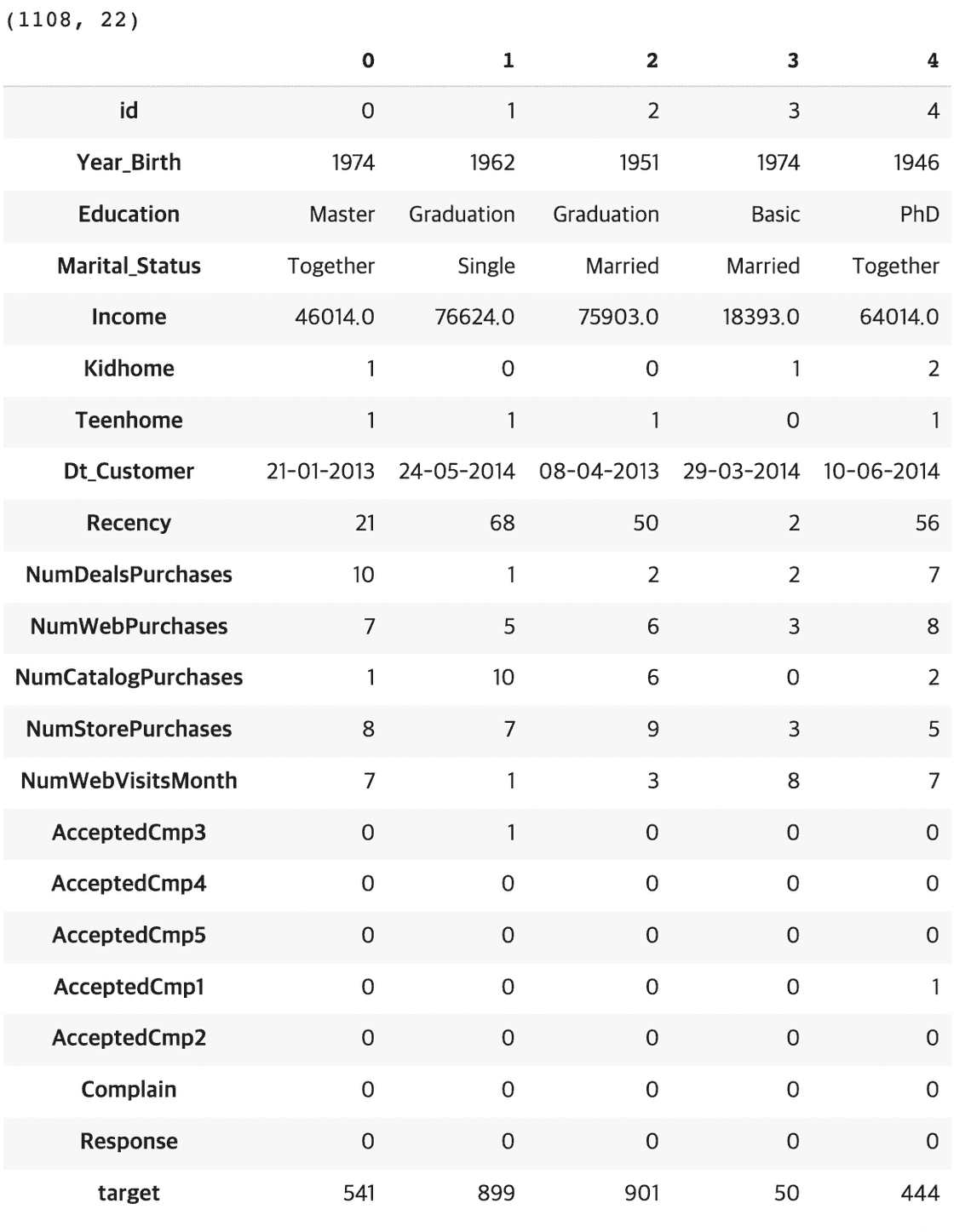
feature를 확인했으니 데이터를 불러옵니다. 데이터가 잘 불러와졌는지 확인함과 동시에 데이터의 행과 열이 몇 개인지도 확인해줍니다. transpose를 이용하여 행과 열의 위치를 바꿔 데이터를 더 직관적으로 확인합니다.
해당 캡처본에는 나오지 않았지만, info()와 describe(include =“all”)을 사용하여 데이터의 이상치를 확인하였습니다. null 값을 포함한 이상치는 없었으나, Dt_customer 값(고객이 회사에 등록한 날짜)이 “date-month-Year”로 표기되어 ”-” 문자 때문에 데이터의 타입이 object로 인식되었습니다. 해당 데이터는 int로 변환해주는 것이 모델링을 할 때 용이할 것으로 판단됩니다.
from matplotlib import pyplot as pltimport pandas as pdimport numpy as npimport seaborn as sns%matplotlib inlineimport warningsfrom pandas.core.common import SettingWithCopyWarningwarnings.simplefilter(action="ignore", category=SettingWithCopyWarning)data_train = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/dacon_contest/train.csv')data_test = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/dacon_contest/test.csv')print(data_train.shape)data_train.head(5).transpose() #행 1108개, 열 22개
target overview
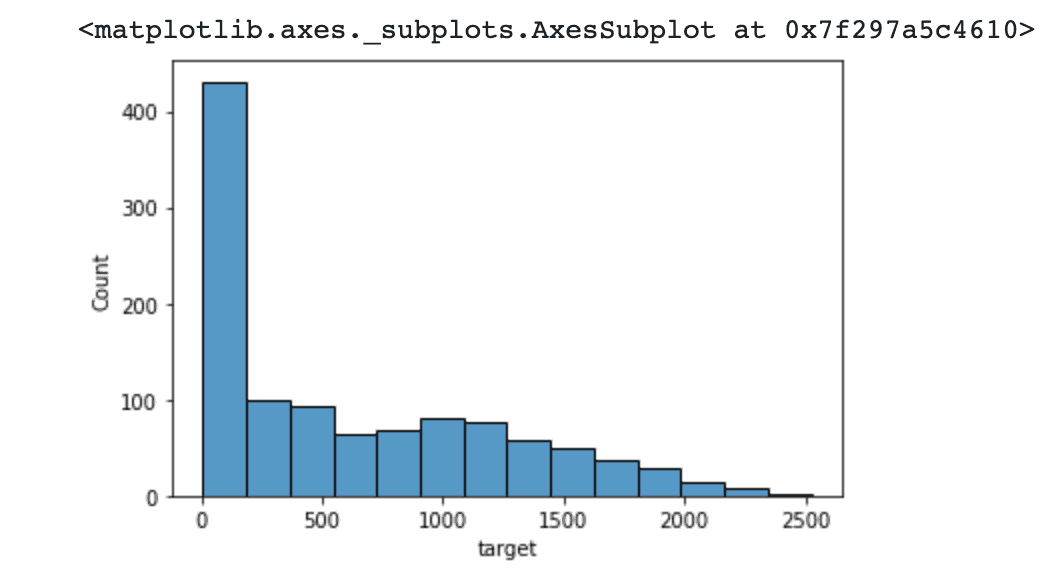
예측해야 하는 target 값(고객의 제품 총 소비량)의 분포를 seaborn histplot을 이용하여 확인합니다.
0~250까지에 target 값이 집중해있는 것을 확인할 수 있고, 2250~2500에 아주 적은 target 값이 분포해있는 것을 확인할 수 있습니다.
target 값이 연속적인 값으로 이루어져 있지만, 특정 구간에 값이 집중해있으므로 타켓값에 범위를 지정하여 카테고리형으로 변경해주기로 합니다.
sns.histplot(data_train['target'])
target 값의 범위는 target 값이 가장 많이 분포되어 있는 범위, 일정하게 분포되어 있는 범위, 감소하기 시작하는 범위, 가장 적게 분포되어 있는 범위로 나누어 줍니다.
- 1 = target 값이 가장 많이 분포되어 있는 범위, 0~250
- 2 = target 값이 일정하게 분포되어 있는 범위, 250 ~ 1000
- 3 = target 값이 감소하기 시작하는 범위, 1000 ~ 2000
- 4 = target 값이 가장 적게 분포되어 있는 범위, 2000~
로 나누어 줍니다.
# 타겟값에 범위를 지정하여 카테고리형으로 나누기data_train_T=data_train['target']target=[]for i in range(len(data_train_T)):if data_train_T.iloc[i] < 250:target.append(1)elif data_train_T.iloc[i] < 1000:target.append(2)elif data_train_T.iloc[i] < 1800:target.append(3)else:target.append(4)data_train["Range"] = target
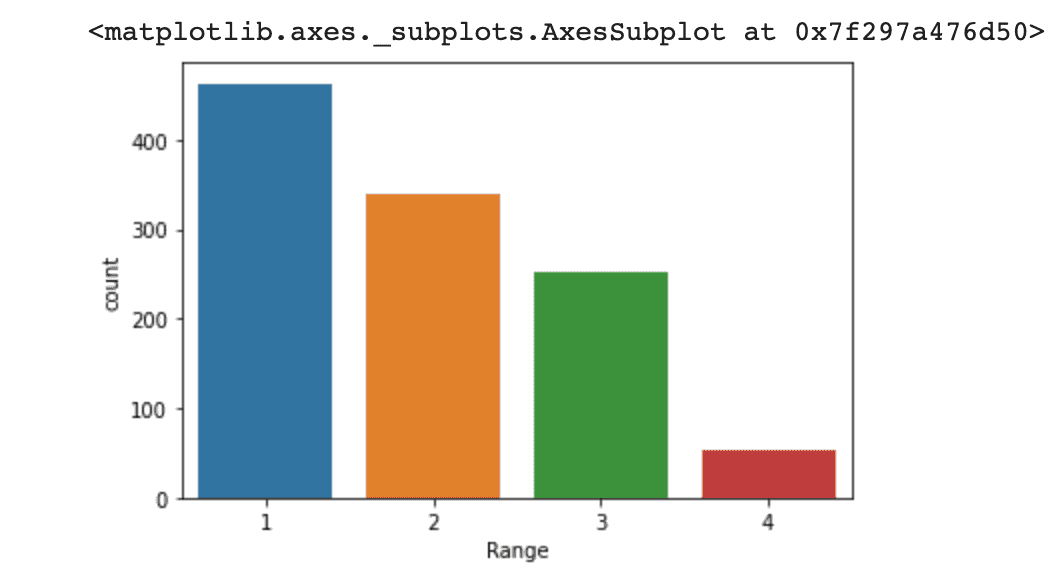
카테고리형으로 나누어진 target 값의 분포를 확인합니다.
target 값이 가장 많이 분포되어 있는 범위, 일정하게 분포되어 있는 범위, 감소하기 시작하는 범위, 가장 적게 분포되어 있는 범위로 잘 나뉜 것을 확인합니다.
sns.countplot(x = data_train["Range"]) # target을 range로 변환
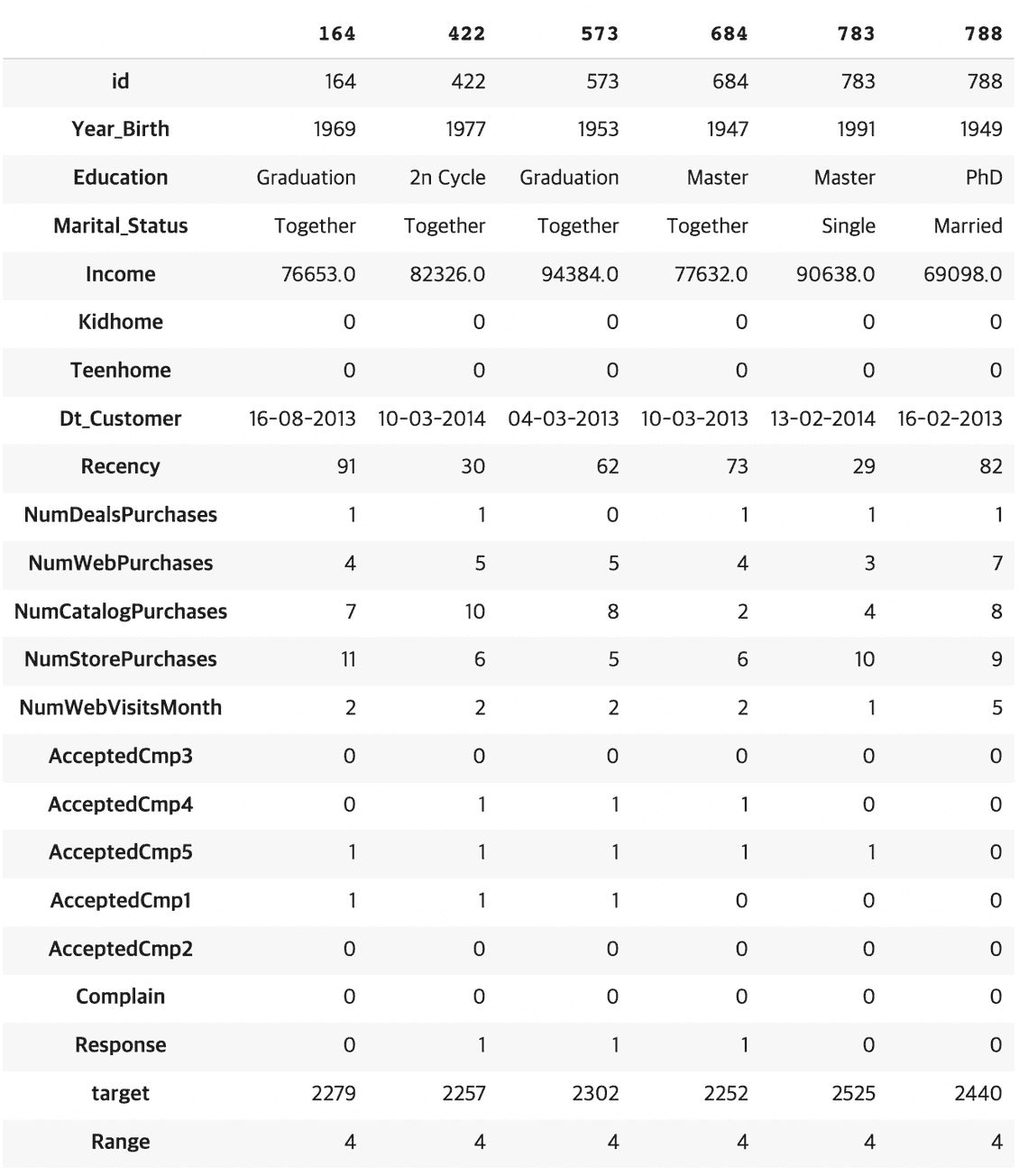
target의 분포를 보니 0~250 사이의 데이터가 많으며, 2000 이후의 샘플에 대한 데이터가 충분하지 않아, high target에 대해서 잘 맞추지 못하는 모습을 보일 것으로 예상됩니다.
data_train[data_train['target']>2250].transpose()#target의 분포를 보니 0~250 사이의 데이터가 ��많으며, 2000 이후의 샘플에 대한 데이터가 충분하지 않아, hight target에 대해서 잘 맞추지 못하는 모습을 보입니다.# 1 : 0~250 / 2 : 250 ~ 1000 / 3 : 1000 ~ 1800 / 4 : 1800 ~
shape를 통해 데이터의 크기를 다시 확인합니다. 데이터가 1100개 정도로 많은 편은 아닙니다. 몇 개 이상의 데이터라면 충분하다는 절대적인 기준이 없습니다만, 예측해야 하는 target 값의 카테고리가 4개인 점과 데이터가 1100개인 점을 고려했을 때, 해당 데이터의 양이 많은 편은 아니라고 판단하게 되었습니다.
(데이터의 양이 많지 않다면 추후 모델링에서 과소적합의 문제가 발생할 수 있기 때문에, 해당 분석에서 모델링을 진행할 때는 과소적합 및 과대적합을 방지해주는 교차검증을 사용하는 것이 긍정적일 것으로 예상됩니다.)
print(data_train.shape, data_test.shape)#Data가 1100개 정도로 많은 편은 아닙니다. K-fold를 통한 학습이 필요해 보입니다.
데이터 전처리
데이터 전처리를 해줍니다. 카테고리컬 데이터이면서 object인 값을 가진 컬럼은 int 타입의 값으로 mapping을 통해 변환해줍니다. mapping은 각 데이터마다 mapping 될 수도 있고, 중복되는 특성을 가진 값을 합치는 방식으로도 mapping 할 수 있습니다. (트리모델을 사용하는 경우 object타입인 카테고리컬 데이터를 변환하지 않아도 모델링이 가능하나, 이번 분석에서 사용하는 catboost, lightgbm, xgboost의 경우 object -> int로의 변환이 필요하여 mapping을 진행해줍니다.)
Education 컬럼은 각 데이터마다 값을 mapping 해주고, Marital_Status는 중복되는 특성을 가진 값들끼리 합치면서 mapping 해줍니다.
mapping 된 두 컬럼은 train 데이터와 test데이터에 각각 적용해줍니다.
#['Master' 'Graduation' 'Basic' 'PhD' '2n Cycle'] = ['석사' '졸업' '학사' '철학박사' '과학박사']#['Together' 'Single' 'Married' 'Widow' 'Divorced' 'Alone' 'YOLO' 'Absurd'] = ['동거' '싱글' '결혼' '과부' '이혼' '혼자' '욜로' '부적절']#성격이 중복되는 feature 동일 feature로 mappingEducation_Subjects = {"Graduation" : 0,"Basic" : 1,"Master" : 2,"PhD" : 3,"2n Cycle" : 4}Marital_Status_Subjects = {"Single" : 0,"Alone" : 0,"YOLO" : 0,"Absurd" : 0,"Widow" : 1,"Divorced" : 2,"Together" : 3,"Married" : 4}data_train["Education"] = data_train["Education"].map(Education_Subjects)data_train["Marital_Status"] = data_train["Marital_Status"].map(Marital_Status_Subjects)data_test["Education"] = data_test["Education"].map(Education_Subjects)data_test["Marital_Status"] = data_test["Marital_Status"].map(Marital_Status_Subjects)data_test.head()data_train.head()
현재 연도에서 Year_Birth를 빼는 방식으로 나이를 계산하여 Age컬럼도 생성하여 train과 test 데이터에 적용해줍니다.
#Year_Birth를 이용해 나이 Age 계산하기data_train['Age'] = 2022 - data_train['Year_Birth']data_test['Age'] = 2022 - data_train['Year_Birth']
mapping 완료 후, 중복된 특성을 가진 값을 합친 Marital_Status의 값의 개수를 확인해봅니다. 값의 개수가 내림차순으로 정렬되어 보입니다. 중복된 특성을 합친 0값이 적절한 데이터를 갖게 되었음을 확인합니다.
data_train['Marital_Status'].value_counts()

타임스탬프 Dt_Customer를 활용하여 회사 가입 개월 수인 Sign_Month로 변환합니다. Sign_Month는 사이트에 가입하고 몇 개월이나 지났는가? 를 뜻하며 높을수록 예전에 가입한 사람임을 의미합니다.
#타임스탬프 Dt_Customer를 회사 가입 개월수인 Sign_Month로 변환#sign_month = 사이트에 가입하고 몇개월이나 지났는가? 높을수록 예전에 가입한사람for data in [data_train, data_test]:for i in range(data.shape[0]):data['Dt_Customer'].iloc[i] = int(data['Dt_Customer'].iloc[i][-1]) * 12 + int(data['Dt_Customer'].iloc[i][3:5])recent_month = max(data_train['Dt_Customer'])for data in [data_train, data_test]:month_arr = []for i in range(data.shape[0]):month_arr.append(recent_month - data['Dt_Customer'].iloc[i])data['Sign_Month'] = month_arr
전처리 완료 후, target 과의 상관관계를 확인합니다.range(target을 범주형으로 바꾼 컬럼)와 NumCatalogPurchases, Income등, NumStorePurchases 컬럼이 높은 상관관계를 보이는 것을 확인할 수 있습니다.
#상��관관계 살펴보기corr_matrix = data_train.corr()corr_matrix["target"].sort_values(ascending=False)
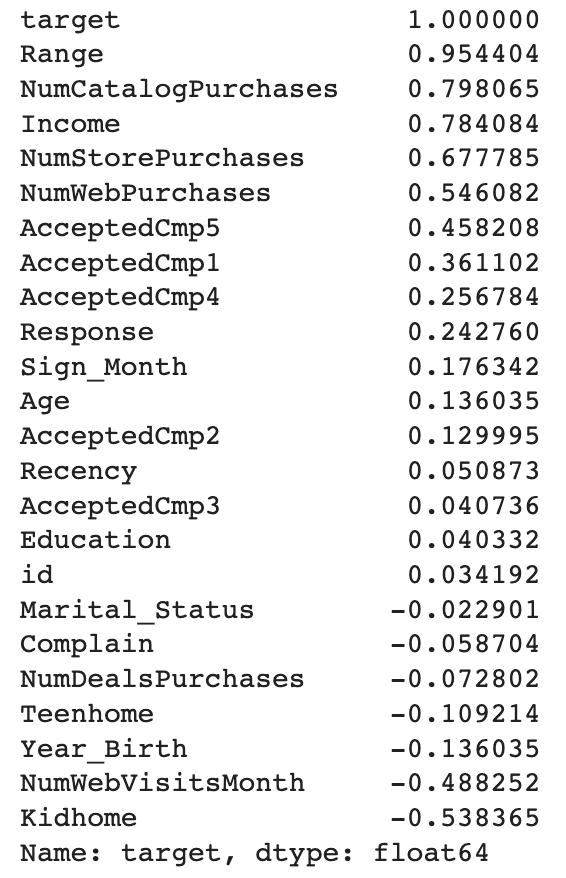
cardinality가 높은 컬럼들은 모델이 예측할 때 불리하게 작용하기 때문에 해당 컬럼들은 삭제해줍니다.
#필요없는 feature 버리기data_train = data_train.drop(["id", "Dt_Customer", "Year_Birth"], axis = 1)data_test = data_test.drop(["id", "Dt_Customer", "Year_Birth"], axis = 1)
전처리가 끝나면 모델링을 위해 데이터셋을 독립변수들의 모임인 데이터 X와, 종속변수 데이터셋 y로 나눠줍니다.
#데이터셋 X, Y 나누기data_train_X = data_train.drop(["target"], axis = 1)data_train_y = data_train["target"]
모델 생성 및 학습
해당 대회의 평가 방법인 NMAE를 정의해줍니다.(대회 자체에 평가 방법 NMAE 코드가 명시되어 있습니다. 복붙하면 됩니다.)
NMAE는 시계열 분석의 평가 방법으로 자주 쓰이는 성능 평가 지표이고, NMAE 의 값이 작을수록 잘 예측한 것 입니다.
#평가방법인 NMAE 정의def NMAE(true, pred):score = np.mean(np.abs(true - pred) / true)return score
catboost, lightgbm, xgboost를 10 k-fold로 soft-voting
여기서 추가적으로 하이퍼파라미터 튜닝 등을 통해 성능을 향상시키거나, ngbr 등 다른 모델을 추가하거나, soft-voting 대신 다른 앙상블 방법을 사용해서 모델의 성능을 향상시킬 수 있습니다.
- 모델 설명
- catboost, lightgbm, xgboost : 머신러닝의 예측모델 (xgboost와 lightgbmdml ‘gb’는 이들이 Gradient Boost 를 기반으로 만들어진 모델임을 뜻한다.)
- xgboost : Gradient boost(xgboost의 기반이 되는 모델) 모델의 단점(학습속도)을 극복하는 모델
- lightgbm : xgboost의 단점(학습속도)을 극복하는 모델
- catboost : lightgbm의 오버피팅 문제를 해결하기 위해 만들어진 모델
- 클래스_설명
- k-fold, stratifiedkfold : sklearn 에서 교차검증을 구현하기 위해 k-fold와 stratifiedkfold 클래스를 제공
- k-fold 교차검증 : k번마다 k개의 학습데이터셋을 나누어 평가를 진행하는 것
- k-fold : 가장 보편적인 k-fold 방법이자, 학습 데이터셋과 검증데이터셋을 나누어 진행하는 방법
- stratifiedkfold : 불균형한 dataset을 위한 k-fold 방법
- Soft voting, Hard voting
- Hard voting : Majority voting이라고도 하며, 각각의 모델들이 결과를 예측하면 단순하게 가장 많은 표를 얻은 결과를 선택하는 것. 즉, 다수결과 같음
- Soft voting : Probability voting이라고도 하며, 각 클래스별로 모델들이 예측한 probability를 합산해서 가장 높은 class를 선택하는 것. 즉, 단순히 수의 많고 적음이 아닌 확률을 모두 더해서 class 를 선택함
정형데이터에서는 트리 기반의 알고리즘의 작동 방식이 긍정적 효과를 내기 때문에 catboost, lightgbm, xgboost를 이용하여 모델링을 진행했습니다. xgboost의 단점을 개선한 모델이 lightgbm, lightgbm의 단점을 개선한 모델이 catboost이고 모두 트리 기반의 알고리즘이기 때문에 문제없이 진행하였습니다. catboost, lightgbm, xgboost를 10 k-fold로 soft-voting 하여 예측 모델을 만들었습니다. 여기서 추가적으로 하이퍼파라미터 튜닝 등을 통해 성능을 향상시키거나, ngbr / 등 다른 모델을 추가하거나, soft-voting 대신 다른 앙상블 방법을 사용해서 모델의 성능을 향상시킬 수 있습니다.
from sklearn.model_selection import StratifiedKFoldfrom sklearn.neural_network import MLPRegressorfrom sklearn.utils import shufflefrom catboost import CatBoostRegressorfrom xgboost import XGBRegressorfrom lightgbm import LGBMRegressorfrom ngboost import NGBRegressorskf = StratifiedKFold(n_splits = 10, random_state = 42, shuffle = True) #총 10번의 fold 진행n = 0 #x번째 fold인지 기록fold_target_pred = []fold_score = []for train_index, valid_index in skf.split(data_train_X, data_train_X['Range']): #range 기준으로 stratified k fold 진행n += 1val_pred_name = [] #validation pred model 이름 저장val_pred = [] #validation set pred 결과 저장target_pred = [] #test set pred 결과 저장train_X = np.array(data_train_X.drop("Range", axis = 1)) #분배된 학습을 위해 생성한 Range feature 제거train_Y = np.array(data_train_y)X_train, X_valid = train_X[train_index], train_X[valid_index]y_train, y_valid = train_Y[train_index], train_Y[valid_index]X_test = np.array(data_test)### Create Model ######모델을 생성하고 집어넣으면 됩니다.### LGBMRegressor ###model = LGBMRegressor(random_state = 42, verbose = 0) #추가적으로 하이퍼파라미터 튜닝 필요model.fit(X_train, y_train) # 모델 학습val_pred_name.append("LGBMRegressor") # 모델 이름 저장val_pred.append(model.predict(X_valid)) # validation set pred 결과 저장target_pred.append(model.predict(X_test)) # test set pred 결과 저장### XGBRegressor ###model = XGBRegressor(random_state = 42) #추가적으로 하이퍼파라미터 튜닝 필요model.fit(X_train, y_train)val_pred_name.append("XGBRegressor") # 모델 이름 저장val_pred.append(model.predict(X_valid)) # validation set pred 결과 저장target_pred.append(model.predict(X_test)) # test set pred 결과 저장### CatBoostRegressor ###model = CatBoostRegressor(random_state = 42) #추가적으로 하이퍼파라미터 튜닝 필요model.fit(X_train, y_train)val_pred_name.append("CatBoostRegressor") # 모델 이름 저장val_pred.append(model.predict(X_valid)) # validation set pred 결과 저장target_pred.append(model.predict(X_test)) # test set pred 결과 저장### voting ###### average validation pred ###preds = np.array(val_pred[0])for i in range(1, len(val_pred)):preds += val_pred[i]preds = preds/len(val_pred)### average target pred ###target_preds = np.array(target_pred[0])for i in range(1, len(target_pred)):target_preds += target_pred[i]target_preds = target_preds/len(target_pred)fold_target_pred.append(target_preds) # append final target predprint("========== fold %d ==========" %(n))for i in range(len(val_pred)):print("%s model NMAE : %0.4f" %(val_pred_name[i], NMAE(y_valid, val_pred[i].astype(int))))print("==============================")print("Average NMAE %0.4f" %(NMAE(y_valid, preds.astype(int))))print("")fold_score.append(NMAE(y_valid, preds.astype(int)))total_score = fold_score[0]for i in range(2, len(fold_score), 1):total_score += fold_score[i]total_score = total_score/(len(fold_score))print("==============================")print("Total Average NMAE %0.4f" %(total_score)) #최종 average score 출력
제출하기
마지막으로 평균 타겟 예측값을 저장하고 제출합니다.
### average target pred ###final_pred = np.array(fold_target_pred[0])for i in range(1, len(fold_target_pred)):final_pred += fold_target_pred[i]final_pred = final_pred/len(fold_target_pred)final_pred = final_pred.astype(int)submission = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/dacon_contest/sample_submission.csv")submission.head()submission['target'] = final_predsubmission.head()submission.to_csv("submission_baseline2.csv",index = False)
소비 예측 경진대회 후기
이번 데이터 분석 경진대회는 정말 한 주 동안 자투리 시간을 모으고 모아 어렵게 완수한 대회였습니다.
시간적 여유가 없는 상황에서 진행했기 때문에 더 깊이 생각해보지 못한 부분에 대해 아쉬움이 많이 남기도 합니다. 하지만 동시에 효율성과 지식 정리를 할 수 있도록 도움을 받기도 하였습니다. 얻은 점도 있지만 아쉬운 점이 더 크게 느껴지는 대회였습니다.
이번 대회를 통해 전처리와 모델링에 대해 더 깊게 공부해야 할 필요성을 느꼈습니다. 코드가 추가된 이유를 정확히 설명하기 어려운 경우가 있었고, 왜 그렇게 해결했는지 설명하기 어려운 경우가 있었습니다. 데이터 분석 공부 초기에 일단 따라 하면서 학습을 진행했는데, 이 방식이 지금은 맞지 않는 것 같습니다. 좀 더 깊은 이해를 해보는 쪽으로의 공부가 필요한 시점으로 보입니다.
이렇게 저의 짧고 굵은 경진대회가 끝이 났습니다. 저의 부족한 글이 누군가에겐 도움이 되길 바라며 글을 마무리합니다. 긴 글 읽어주셔서 감사합니다. :)