Table Of Contents
Regression이 조금 아쉬울 때, Propensity Score
들어가기에 앞서
글 작성에 많은 영감을 주었고, 많은 참조를 한 자료들입니다👍👍
- [R기반 성향점수분석]
- [통계] Propensity Score Matching 업데이트+ 실습용 Shinyapps
- [An intuitive introduction to Propensity Score Matching]
이 글에서 다루고자 하는 것은 인과추론에 대한 한 방법입니다.
- 인과관계 / 상관관계의 차이
- Regression 과 Conditional Probability 정도는 알고 있어야 해요.
개요
이러한 상황을 상상해보겠습니다.
우리는 NGO에 소속된 데이터 분석가로,
최근 몇몇 마을에 이뤄진 구호 활동이 효과가 있었는지.
를 확인해야합니다.
단, 구호활동을 하는 동안 실험을 할 수는 없었습니다.
다시 말해, 데이터가 만들어진 과정은 인과관계 추정에 효과적인 잘 통제된 환경이 아니었습니다. (당연히 데이터가 많지도 않습니다 😭)
아무튼, 그 결과는 이러합니다.
인과관계를 위한 조건
이전에 작성했던, Hill’s Criteria 를 참고 해도 좋습니다.
- 상관관계 (상관관계는 인과관계에 포함됨)
- 시간적 선후 관계 (A 이후 B가 발생해야함)
- 비허위성 (다른 변수는 배제)
이 필요한데요.
이를 위해서 RCT (완전 랜덤하게 배치하여 실험)를 해야 하지만, 앞에서 말한 것처럼 현실적으로 RCT를 하지는 못했습니다.
그렇기 때문에, 초보 데이터 분석가인 우리는. 👶
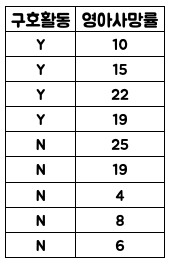
그룹별로 영아사망률에 대한 평균을 계산하여, 효과를 추정했고, 그 결과는 아래와 같습니다. (그룹에 대해 색상을 추가했습니다)
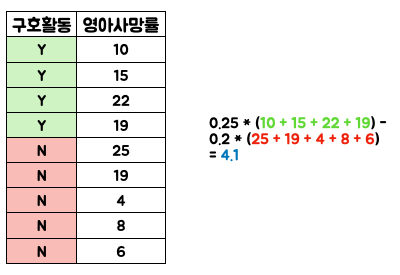
무언가 이상하다 라는 생각을 하면서 사후 조사를 통해 데이터를 추가 했습니다. (단, Row 가 아닌 Column 입니다. Row 면 너무 치트키죠 ㅎㅎ)
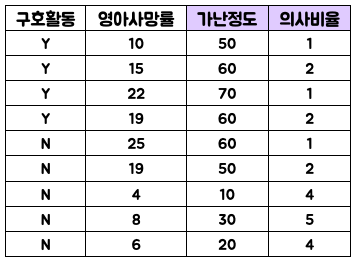
여전히 데이터가 작아서 아쉽긴 하��지만, 나와라 만능도구! Regression 을 활용하기로 합니다.
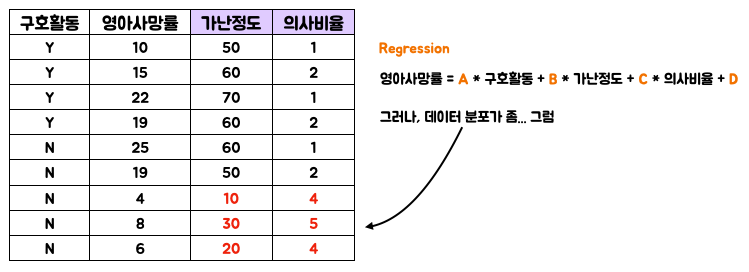
그러나 현실이 늘 그렇듯, 깔끔한 데이터는 없었고… Regression을 활용 해도 되는가 까지도 고민하기 시작합니다.
Propensity Scores (성향점수)
루빈인과모형 을 활용하여, RCT 를 하지 못한 경우 이를 “보정” 하는 작업이라고 생각하면 됩니다.
루빈인과모형이 어떤 것인지 자세히 몰라도 괜찮고, ITAA ( Ignorable treatment assignment assumption ) 라는 것을 사용하는데
다른 요인변수들이 주어졌을때 Treat가 이뤄질 확률은 독립이라 가정한다
정도만 기억하면 됩니다 (사실 이 말도 되게 애매하긴 해요)
그래서 우리는 이를 응용해서 결과변수 (영아사망률)가 아닌 Treat에 대해 Regression을 하여 Score를 계산하고. 이는 PS, 특정 개체가 Treat group에 배치될 확률로 사용합니다. (아래 그림을 참조하면 이해에 조금 더 도움이 될거에요)
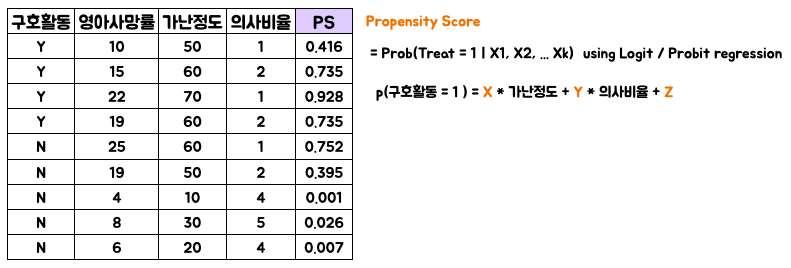
PS의 활용
자 그럼 이렇게 계산한 PS를 실제로 활용할 시간인데요. 많은 방법중 (아래 간단히 기술) Matching을 사용할 겁니다.
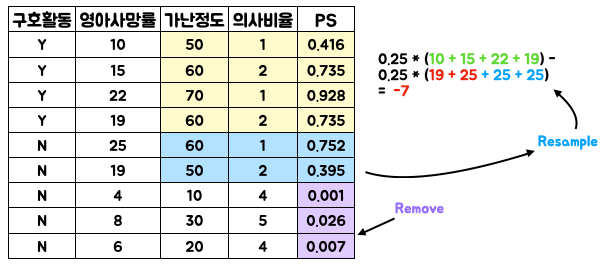
PS를 기반으로, PS가 “차이를 많이 보이는” 데이터를 제거하여, 다른 변수들의 영향을 줄인 뒤, 차이를 다시 구해보았습니다. (Resample 과정에서 25가 2번 나오는 것보다는 19, 25 한번씩 나오는게 더 효과적일 수도 있어요.)
이제, 구호활동을 한 마을 그룹이 영아 사망률이 훨씬 더 줄었다는 결론을 낼 수 있게 됩니다.
PS vs Regression
이쯤 되서 궁금해 지는 Propensity Score와, Regression 의 차이. 를 그림과 글로 잠깐 훑어보겠습니다.

데이터를 분석함에 있어서 여러 방법론들이 있기 때문에 “무조건 절대적으로 좋은” 데우스 엑스 마키나 방법은 없습니다. 그렇기 때문에 상황에 따라서 여러 방법들을 활용해야하고, 그러기 위해서 다양한 방법들을 인지 하고 있는게 좋지 않을까..? 정도로 생각해요.
다시 본론으로 돌아와서.
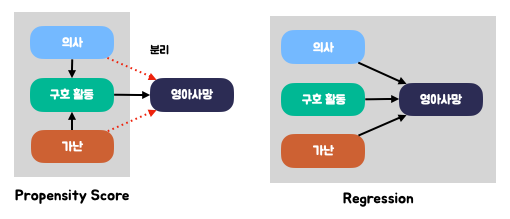
가장 핵심 차이는 결과를 모델링할 때
“여러 요인”들을 고려하느냐, 아니면
비슷한 요인들로 맞춰주고 “가장 보고 싶은 요인”에 집중해서 보느냐
정도의 차이인 것 같아요.
물론 Regression 이 인과추론이냐 는 아예 다른 이야기긴 합니다 ㅎㅎ.
번외
1. PS, 성향점수의 활용
Regression 을 통해 계산되는 PS의 활용은 크게 3가지 방법이 있습니다.
- 가중: Treat와 Control Group간의 PS가 같아지도록 가중치를 부여.
- 매칭: Treat와 비슷한 PS를 가진 Control Group data들을 매칭 (이번 케이스 🔥)
- 층화: Treat group과 Control group data들을 PS가 비슷한 K개 집단으로 Clustering
사실 다른 부분에 대해서는 응용통계 하시는 분들이 아니면.. (초보 데이터 분석가에겐 Over tech…!)
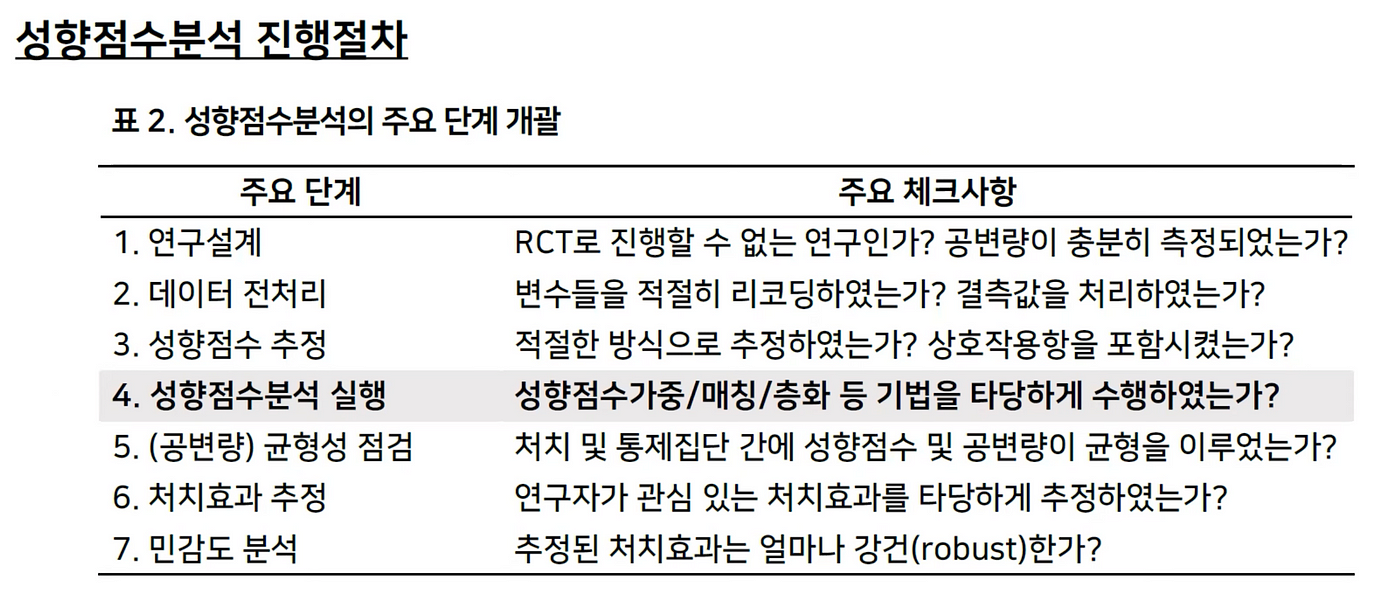
2. PS, 성향점수분석 진행절차
이 부분은 성향점수분석을 할때 참고 하면 좋은 가이드라인입니다. (설명은 맨 위, 유튜브 링크를 통해 직접 듣는게 더 좋을 것 같아요)
결론
모두가 잘 알고 있고, 인정하겠지만 데이터가 좋으면 복잡한 모델 사용하지 않아도 결과가 잘 나와요. (Garbage in Garbage Out, Occam’s Razor 가 괜히 있는 말이 아닙니다)
아니면. 수치로 상황을 해석하는 모델링을 넘어서서
손, 발품을 팔아 직접 유저인터뷰를 하는 것이 프로덕트를 해석하거나, 인과관계를 만들어 내는 것에 더 효과적일 수도 있어요.
데이터 수집, 로깅 잘합시다… ! (유저 인터뷰는 좋은 자료 찾으면…)
이를 위해 몰래 주워온 아래, 변성윤 선생님의 세션을 참조하는 것도 슈퍼 강추 👍👍👍👍👍

https://www.youtube.com/watch?v=cE38iV4KczQ
(힙데비에서 불펌)