Table Of Contents
A/B 테스트와 같은 제품 실험을 자주 실행하는 조직일수록, 실험 분석 결과에 따라 다음 액션이 빠르게 결정됩니다. 실험 분석에서 가장 중요한 것은 무엇일까요? Microsoft Research 에서는 신뢰할 수 있는 실험 분석을 위해서는 데이터 퀄리티가 기본적으로 갖춰줘야 한다고 이야기합니다.
이 글은 Microsoft Experimentation Platform 팀에서 소개하는 “Data Quality: Fundamental Building Blocks for Trustworthy A/B testing Analysis” 를 바탕으로 작성되었습니다.
Introduction
데이터는 기술 산업의 모든 제품 라이프사이클에서 중요한 역할을 합니다. 데이터를 통해 우리는 제품을 개선하고 더 나은 사용자 경험을 제공할 수 있는 인사이트를 얻을 수 있습니다. 하지만 이러한 인사이트는 신뢰할 수 있는 데이터에서 도출되어야만 실행이 가능합니다. 예를 들어 내비게이션 앱의 경우 정확한 위치 탐지 데이터에 의존해 사용자에게 방향을 제시합니다.
데이터 퀄리티는 A/B 테스트에서 특히 중요한데요, A/B 테스트를 통해 다양한 관점에서 새로운 feature 를 평가하고 데이터에 기반한 결정을 내릴 수 있습니다. 그러나 신뢰할 수 없는 데이터는 사용자 경험이나 주요 지표를 악화시키는, 잘못된 분석과 의사결정으로 이어질 수 있습니다.
이번 글에서는 신뢰할 수 있는 A/B 테스트 분석을 위해 데이터 퀄리티를 확인할 수 있는 도구와 방법론을 아래와 같은 순서로 살펴보겠습니다.
1. 데이터 퀄리티는 A/B 테스트에 어떤 영향을 끼칠까?2. 데이터 퀄리티를 위해 가장 중요한 체크리스트는?3. 데이터 퀄리티를 꾸준히 모니터링할 수 있는 방법은?
데이터 퀄리티는 A/B 테스트에 어떤 영향을 끼칠까?
A/B 테스트 결과는 완전하고 정확한 데이터를 기반으로 하는 경우에만 신뢰할 수 있고 실행 가능합니다. 하지만 어떻게 우리가 사용하고 있는 데이터를 신뢰할 수 있다고 판단할 수 있을까요? 다음은 A/B 테스트에서 주의해야 할 몇 가지 데이터 퀄리티 이슈에 대한 징후입니다.
Sample Ratio Mismatch (SRM, 샘플 비율 불일치)
SRM 은 실험군과 대조군에 할당된 트래픽이 구성했던 방식과 다른 경우로, Selection bias (선택 편향)으로 이어질 수 있습니다. 일반적으로 SRM 이 발생한 분석은 신뢰할 수 없는 것으로 보기 때문에 어떠한 결정을 내리는 데 사용해서는 안됩니다. 데이터 퀄리티 이슈로 인해 SRM 이 발생할 수 있는 시나리오는 여러가지가 있습니다. 예를 들어 원격에서 실험군/대조군 할당 정보의 불완전한 기록이나 불균형한 손실 등이 있겠습니다.
STEDI of metrics
A/B 테스트에서 측정하는 지표는 Treatment effect (처치 효과)를 이해하고 관찰된 지표 변화를 해석하는 데 도움이 되도록 Sensitive(민감), Trustworthy(신뢰), Efficient(효율), Debuggable(디버깅 가능), Interpretable(해석 가능) 해야 합니다. 낮은 데이터 퀄리티는 특히 지표의 Sensitivity(민감도)와 Trustworthiness(신뢰도)에 부정적인 영향을 미칠 수 있습니다.
Sensitivity (민감도)
데이터 필드의 결측률이 매우 높으면 이 데이터 필드를 기반으로 하는 조건부 계산 메트릭은 샘플 크기가 매우 작습니다. 이러한 지표에 대한 가설 검정은 검정력이 부족할 것입니다.
이상치는 민감도에 부정적인 영향을 미칠 수 있는 또 다른 흔한 문제입니다. 이상치는 분산을 증가시키고 지표를 변화시키는 큰 노이즈를 만들 수도 있습니다.
Trustworthiness (신뢰도)
결측 데이터를 활용하는 지표는 잘못된 통계량과 신뢰할 수 없는 가설 검정 결과를 가져올 수 있습니다. 실험군과 대조군 사이에 누락된 데이터 비율이 불균형할 때에는 상황이 더 심각한데요, 리텐션 분석에서 데이터 누락은 실제 사용자가 이탈을 하지 않았음에도 불구하고 리텐션 지표를 낮출 수도 있습니다.
다양한 세그먼트에 대한 심층 분석이 필요한 상황 혹은 세그먼트에 사용되는 필드가 부정확하거나 결측률이 높을 경우 이러한 세그먼트에 기반한 결과도 오해의 소지가 있을 수 있습니다.
분석 결과 전달 지연 → 의사 결정 지연
통계 분석은 완전한 데이터에 의존합니다. 소프트웨어 제품에서는 일반적으로 데이터 생성과, 분석을 위한 데이터 준비 사이의 지연이 발생합니다. 예를 들어 가설 검증을 위해 여러 데이터 소스가 필요한 경우 모든 데이터를 사용 가능할 때까지 기다리는 시간은 상당히 길 수 있습니다. 분석이 늦어지면 의사결정 또한 늦어질 수 있습니다. 결과적으로 제품 경험에서 예상치 못한 regression 을 바로 감지하거나 고칠 수가 없습니다. 이러한 상황을 방지하려면 Service Level Agreements 를 충족하는, 잘 설계된 데이터 파이프라인이 매우 중요합니다.
데이터 퀄리티를 위해 가장 중요한 체크리스트는?
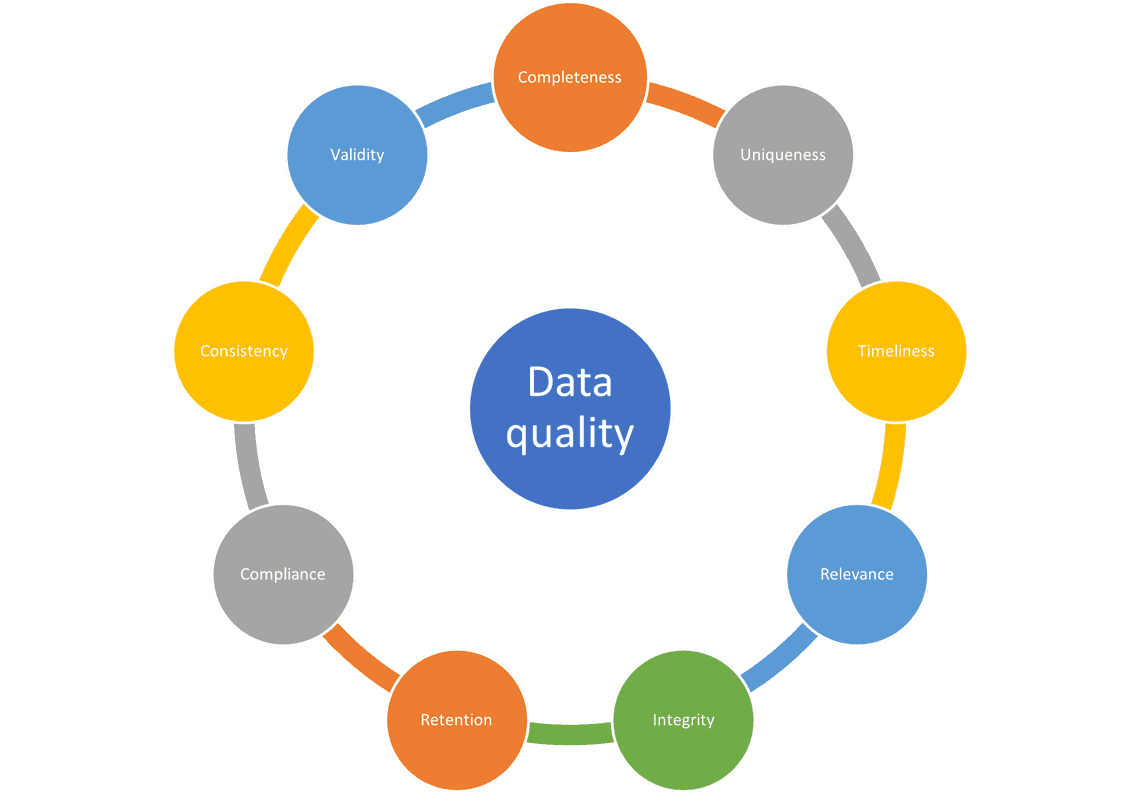
일반적인 데이터 퀄리티에는 Completeness(완전성), Uniqueness(고유성), Timeliness(적시성), Validity(유효성), Integrity(무결성), Consistency(일관성), Relevance(관련성), Compliance(규정 준수) 및 Retention(보존)이 포함됩니다.
A/B 테스트 시나리오에 따라 데이터 퀄리티가 달라지는 사례를 많이 볼 수 있습니다. 잘못된 값을 증가시키는 새 feature 의 버그 같은 사례의 경우 A/B 테스트 과정에서 데이터 퀄리티를 측정하는 지표가 필요함을 알려줍니다.
다음 체크리스트를 사용해 분석에서 데이터 퀄리티를 측정하기 위한 추가 메트릭을 설정할 수 있습니다.
1. Missing rates (결측률)
각 컬럼에서 누락된 값은 얼마나 있는지? dummy value 로 결측치를 나타내는 특정 패턴이 있는지?
2. Invalid values (부적절한 값)
값이 적절한 형식을 따르고 있는지? 해당 컬럼에 맞는 값인지?
3. Join rates (조인 선택도)
다른 데이터 소스에서 데이터를 가져와 합칠 경우 join rate 이 충분히 높은지?
4. Uniqueness (고유성)
중복 항목이 있는지? 동일한 signal 에 대한 열이 두 개 이상 있는지?
5. Data delays (데이터 지연)
계산 시 사용할 수 있는 데이터의 비율이 어떻게 되는지?이벤트가 기록된 시점과 데이터를 분석에 사용할 수 있는 시점 사이에 시간이 얼마나 걸리는지?
이외에도 데이터 보존 기간 및 개인 정보 보호 요구 사항을 포함한 데이터 정책을 준수하고 있는지 확인해야 합니다.
그럼 A/B 테스트 결과를 분석하기 전에 주의해야 할 몇 가지 데이터 필드를 살펴보겠습니다.
Randomization unit
Randomization unit 은 우리가 실험군과 대조군을 임의로 할당하는 unit 을 의미합니다. 일반적인 radomization unit 은 사용자, 세션, 페이지, impression, 디바이스, 쿠키, 문서 등이 포함됩니다. 데이터 퀄리티 검사는 동일한 radomization unit 에 속한 데이터가 정확하고 준수된 방식으로 연결되도록 하는 데 도움이 되어야 합니다.
Randomization unit 으로 간주되는 컬럼의 결측률과 패턴을 항상 확인해야 합니다. (결측 데이터는 null, 빈 문자열, 0, 무한대 또는 기본값으로 표시될 수 있습니다.) 누락된 데이터는 로깅 문제로 인해 특정 데이터 소스에서 발생하거나 데이터 쿠킹 파이프라인에서 유발될 수 있습니다. 예를 들어 특정 빌드 버전 또는 부분 지연이 있는 데이터 소스에서 누락된 데이터를 탐지할 수 있습니다. 경우에 따라 세션 및 사용자와 같은 여러 집계 수준에서 A/B 테스트 데이터를 분석할 수 있는데, 이때에도 필요한 집계 수준 열이 모두 있는지 확인해야 합니다.
Treatment assignment
실험한 feature 의 효과를 비교하기 위해 실험군과 대조군 사이의 데이터를 구별하기 위해서는 Treatment assignment (할당) 정보가 필요합니다. 분석에 사용되는 데이터에는 항상 treatment 할당 정보가 들어 있는 컬럼이 있어야 합니다. 또한 이 정보가 동일한 데이터 소스 내에서, 그리고 데이터를 합칠 수도 있는 상황에서는 여러 데이터 소스 간에 일관된 형식을 따르도록 하는 것이 좋습니다.
또한 treatment assignment 는 분석을 통해 randomization unit (즉, 사용자)에 대해 일관성이 있어야 합니다. 예를 들어 사용자를 실험군에 할당하면 해당 사용자가 대조군에는 나타나지 않아야 합니다.
Timestamp
A/B 테스트 진행 시 관심 이벤트 발생 시간을 추적해야 합니다. 따라서 이벤트의 타임스탬프를 나타내는 열은 항상 있어야 합니다. 타임스탬프는 분석에 포함된 이벤트를 필터링하고 트리거된 분석에 대한 이벤트 순서를 결정하는 데 중요한 역할을 합니다. 또한 결측률을 확인하고 기본 datetime 1900-01-01 및 향후 datetime 과 같은 값을 필터링해야 합니다.
적절한 타임스탬프를 가급적 제품 맥락에서 선택하는 것이 중요합니다. 일반적으로 선택할 수 있는 타임스탬프는 두 개 이상으로, 활동이 발생한 시간과 해당 로그가 수신된 시간이 포함됩니다. 웹 기반 서버 측 A/B 테스트의 경우 시간 차이가 크지 않을 수 있으며 활동 순서는 변경되지 않습니다.
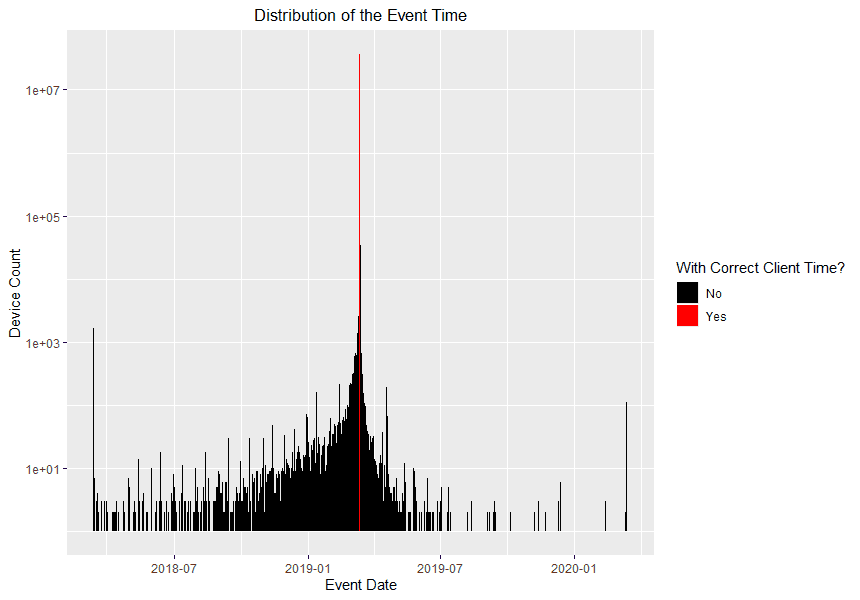
그러나 클라이언트 측 A/B 테스트의 경우 이 두 타임스탬프는 상당히 다를 수 있습니다. 어떤 것을 사용할지 결정하는 것은 제품 팀이 주관적으로 절충하지만, 이전 경험으로 볼 때 클라이언트가 반환한 타임스탬프는 종종 노이즈가 심합니다. 클라이언트 로그 타임스탬프보다는 로그를 받을 때 타임스탬프를 사용하는 것이 좋습니다. 아래는 디바이스에서 기록한 이벤트 시간(클라이언트 시간)과 정확한 이벤트 시간이 어떻게 크게 다를 수 있는지를 보여 주는 예시입니다.
Segments
분석을 위해 종종 데이터를 하위 그룹으로 나눕니다. 이러한 하위 그룹을 Segment (세그먼트) 라고 부르고 다양한 수준의 집합으로 정의합니다. 세그먼트는 행 레벨일 수도 있고 적용 가능한 경우 임의 추출 단위 레벨일 수도 있습니다. 예를 들어 A/B 테스트가 사용자 수준에서 랜덤 추출된 경우 날짜 세그먼트를 행 레벨에, 사용자 레벨에서 사용자 연령 그룹 세그먼트를 가질 수 있습니다. 일부 일반적인 세그먼트에는 날짜, 시장, 브라우저, 앱 버전 등이 포함됩니다.
세그먼트로 사용되는 열은 올바른 형식이어야 하며 허용 가능한 결측률 및 합리적인 Cardinality (카디널리티)를 가져야 합니다. 경험적으로 합리적인 카디널리티 범위는 2부터 10까지입니다. 수백 개의 고유한 값을 갖는 것은 느린 계산, 낮은 통계 검정력과 시각화 관련 로드 또는 응답 문제와 같은 광범위한 문제를 야기할 수 있습니다. 이러한 세그먼트는 더 많은 수의 하위 그룹을 생성할 수 있습니다. 세그먼트 열이 자연스럽게 높은 카디널리티를 갖는 경우 (예를 들어 언어), 일반적으로 채택되는 방법은 가장 높은 빈도를 기준으로 Top N 으로 자르고 나머지를 ‘기타’로 변환하는 것입니다.
데이터 퀄리티를 꾸준히 모니터링할 수 있는 방법은?
데이터 퀄리티는 시간이 지남에 따라, 제품과 데이터 소스가 진화함에 따라 변합니다. 데이터 거버넌스에 대한 새로운 요구사항에 따라 새로운 로그를 추가하고, 새로운 데이터 소스를 가져오면 데이터 퀄리티에 영향을 미칠 수 있습니다. 데이터 퀄리티 측정을 추적하는 데 사용할 수 있는 도구는 다음과 같이 여러가지가 있습니다.
1. Dashboard for data quality metrics
주기적으로 데이터를 수집해야 합니다. 수집 빈도는 시간별, 일별, 주별 또는 사용자 지정 빈도일 수 있습니다. 데이터 퀄리티의 변화 빈도와, 계산 및 스토리지 비용 예산에 따라 달라집니다.
2. Alerting on anomalies
이상 징후에 대한 경고를 설정하면 데이터 퀄리티를 측정하는 메트릭의 비정상적인 변화를 탐지하는 데 도움이 될 수 있습니다. 소스 데이터 또는 처리 파이프라인의 비정상적인 작업을 나타낼 수 있습니다.
3. Segment data quality metrics
데이터 퀄리티를 측정하는 메트릭은 일반적인 메트릭과 마찬가지로 동일한 세그먼트를 기준으로 계산해야 합니다. 때로는 세그먼트 내에서 데이터 퀄리티가 크게 저하될 수 있지만 전체적으로는 차이가 거의 없을 수 있습니다.
4. A/A test
A/A 테스트는 실험군과 대조군에서 동일한 경험을 갖는 A/B 테스트입니다. A/A 테스트 실행은 A/B 테스트 시스템의 end-to-end 테스트에 권장되는 접근 방식이며 데이터 퀄리티 문제를 파악하는 데 도움이 될 수 있습니다.
A/A 테스트는 통계적으로 유의한 메트릭 변경 없이 variants 간 트래픽 분할을 균형 있게 수행할 것입니다. SRM 또는 예기치 않은 메트릭 이동이 있는 경우는 원격 측정 또는 데이터 파이프라인 구현 관련 문제 때문일 수 있습니다.
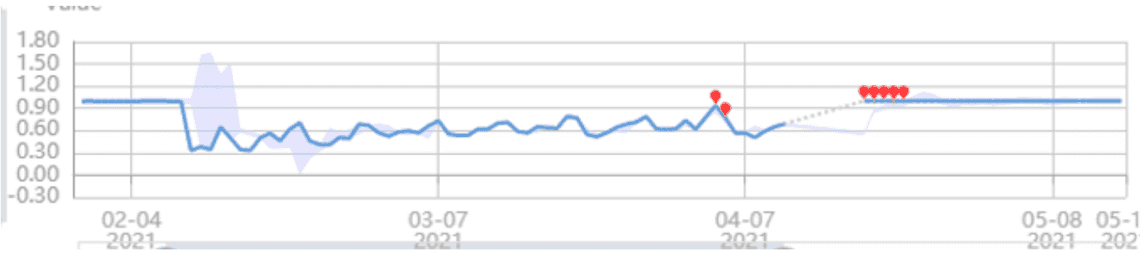
아래는 Microsoft 팀이 모니터링을 위해 위의 처음 3가지 도구를 실제 사용하는 방법을 보여주는 예시입니다. 대시보드(파란색 선)는 시간 경과에 따른 데이터 퀄리티 메트릭의 값 변화를 보여 줍니다. 빨간색 지점은 제품 팀에게 경고할 이상 징후를 강조합니다. 하위 그룹의 데이터 퀄리티를 보장하기 위해, 시장 및 OS 버전과 같은 부분에 대해서도 동일한 대시보드를 설정합니다.
마치며
데이터 퀄리티는 신뢰할 수 있는 A/B 테스트 결과를 위한 기본 구성 요소입니다. 데이터 퀄리티 문제로 인해 신뢰할 수 없는 A/B 테스트 결과는 의사결정에 부정적인 영향을 미칠 수 있습니다.
Microsoft 에서는 데이터 퀄리티 확인을 위해 항상 위의 4가지 도구를 활용해 모니터링을 지속합니다. 이번 글에서 소개한 데이터 퀄리티 체크리스트 및 중요 데이터 필드 요구사항을 활용해, 각자의 조직에서 A/B 테스트 데이터에 대한 점검을 해봐도 좋을 것 같습니다.
References
[1] A. Fabijan et al., “Diagnosing Sample Ratio Mismatch in A/B Testing.” https://www.microsoft.com/en-us/research/group/experimentation-platform-exp/articles/diagnosing-sample-ratio-mismatch-in-a-b-testing/
[2] R. Kohavi, D. Tang, and Y. Xu, Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing. Cambridge University Press, 2020.
[3] W. Machmouchi, S. Gupta, and R. Zhang, “Patterns of Trustworthy Experimentation: During-Experiment Stage.” https://www.microsoft.com/en-us/research/group/experimentation-platform-exp/articles/patterns-of-trustworthy-experimentation-during-experiment-stage/
[4] Janhavie, “Data Quality.” https://medium.com/datacrat/data-quality-dc4018fc443
[5] Lean-Data, “Here is how to start with data quality.” https://www.lean-data.nl/data-quality/here-is-how-to-start-with-data-quality/
[6] T. Crook, B. Frasca, R. Kohavi, and R. Longbotham, “Seven pitfalls to avoid when running controlled experiments on the web,” in Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining – KDD ’09, Paris, France, 2009, p. 1105. doi: 10.1145/1557019.1557139.