Table Of Contents
오늘의 글은 “분석 조직이 조금 더 빠르고 유연하게 움직일 수 있는 환경은?”이라는 질문으로부터 시작되었으며, James Densmore의 Data Pipelines Pocket Reference를 읽고 ELT 패턴에 대한 내용을 담았습니다.

데이터 파이프라인을 설계하는 것은 여러 목표가 있을 수 있고 각자의 목표와 제약사항을 가지게 됩니다.
- 데이터를 실시간으로 처리할 것인가?
- 데이터가 매일 또는 매주 업데이트될 수 있는가?
- 분석된 데이터를 어떻게 활용할 것인가? (오늘 다룰 주제의 Key Point)
ETL과 ELT
데이터 파이프라인을 설계할 때 Batch Processing Pattern, Stream Processing Pattern, Lambda Architecture Pattern, ETL Pattern, ELT Pattern, Microservices Pattern 등과 같은 패턴들을 참고할 수 있을 것입니다. 이런 패턴들 중 ETL Pattern 과 ELT Pattern에 대해서 조금 더 살펴보고자 합니다. 먼저 ETL과 ELT의 주요 단계에 대해서 살펴보겠습니다.
추출(Extract)
데이터 추출은 ETL과 ELT에서 모두 시작되는 단계이며 다양한 데이터 소스에서 필요한 데이터를 선택하여 가져오는 과정입니다.
변환(Transform)
데이터 변환은 각 소스 시스템의 원본 데이터를 정제하고 필요한 형태로 가공하는 단계입니다. 필드의 추가, 제거, 병합, 분할과 같은 작업이 포함될 수 있고 품질 검증 과정도 수행될 수 있습니다. (EtLT 패턴에서 품질 검증 과정을 t로 정의할 수 있습니다.)
로드(Load)
데이터 웨어하우스나 데이터 레이크 또는 최종 목적지에 데이터를 로드합니다. ETL의 경우 변환된 데이터를, ELT의 경우 원본 데이터를 대상으로 작업됩니다.
ELT의 등장 배경은 무엇일까?
데이터 파이프라인의 표준 패턴인 ETL이 사용되고 있는데 왜 ELT라는 패턴이 등장했을까요?
In the Past
- 데이터 팀이 대량의 원본 데이터를 로드하고 이를 사용 가능한 데이터로 변환하는 데 사용되는 스토리자나 컴퓨팅 자원이 있는 데이터 웨어하우스에 액세스할 수 없었습니다.
- OLTP에서 잘 작동하는 행 기반(Row Store) 데이터베이스였으며 분석에서 사용되는 복잡한 대용량 쿼리에 적합하지 않았습니다.
Currently
- 대부분의 데이터 웨어하우스는 대규모 데이터세트에 대해 대량 변환을 저장하고 실행할 수 있는 열 기반(Column Store) 데이터베이스를 기반으로 합니다.
- 열 기반 데이터베이스는 I/O 효율성이 높으며, 동일한 값이 많은 열에 대해 데이터를 압축하는 기술을 적용할 수 있습니다. 또한, 병렬 노드 사용으로 데이터 및 쿼리를 분산시켜 처리 속도가 향상됩니다.
Row Store vs Column Store
행 기반 데이터베이스와 열 기반 데이터베이스 간의 차이가 주는 실질적인 영향은 매우 큽니다.
Row Store
| OrderId | CustomerId | OrderAmount |
|---|---|---|
| 1 | 6874 | 23.41 |
| 2 | 32181 | 30.67 |
| 3 | 2135 | 49.27 |
| Block 1 | 1,6874,23.41 |
| Block 2 | 2,32181,30.67 |
| Block 3 | 3,2135,49.27 |
행 기반(Row Store) 데이터베이스에서 각 행은 각 레코드의 크기에 따라 하나 이상의 블록으로 디스크에 함께 저장됩니다. OLTP 사용 사례를 살펴보면 필요로 하는 데이터가 디스크에 가깝게 저장되고 한 번에 쿼리되는 데이터양이 적기 때문에 행 기반 저장소가 최적일 수 있습니다.
Column Store
| OrderId | CustomerId | OrderAmount |
|---|---|---|
| 1 | 6874 | 23.41 |
| 2 | 32181 | 30.67 |
| 3 | 2135 | 49.27 |
| Block 1 | 1,2,3 |
| Block 2 | 6874,32181,2135 |
| Block 3 | 23.41,30.67,49.27 |
열 기반(Column Store) 데이터베이스에서는 각 디스크 블록에 동일한 열의 데이터가 저장됩니다. 분석 쿼리의 경우 많은 양의 데이터를 드물게 읽고 쓰는 경우가 많으며 분석 쿼리가 테이블에 있는 특정 열의 대부분 또는 전부보다는 단일 열을 필요로 할 가능성이 더 클 것입니다.
정리해보면
- 열 기반 데이터베이스의 출현으로, 데이터를 효율적으로 저장하고 변환하여 쿼리 하는 것이 가능해지면서
- 데이터 추출과 웨어하우스 로드를 통한 데이터 파이프라인을 구성하여 활용할 수 있게 되었고
- ELT는 데이터 파이프라인을 구축하는 이상적인 패턴으로 자리 잡게 되었습니다.
- Analytics 조직은 이러한 기술과 패턴을 활용하여 데이터 처리와 분석을 보다 효율적으로 수행할 수 있게 됩니다.
이럴 때는 ELT 패턴을 어떻게 써야 되나요?
- 테이블에 중복된 레코드들이 있어요!
- 보안상 모든 데이터를 웨어하우스에 로드할 수 없어요!
와 같이 Transform이 파이프라인 초기에 필요한 경우에는 EtLT 패턴을 사용하여 기본적인 변환을 수행할 수 있습니다. 중복 제거나 민감한 데이터를 마스킹하는 작업들과 같이 비즈니스 컨텍스트가 없는 데이터 변환이 포함될 수 있으며 Load 이전에 t를 수행하는 이유는 가능한 한 파이프라인 초기에 데이터 품질을 해결하는 것이 가장 이상적이기 때문입니다.
그럼 ETL 패턴을 쓰면 되지 않나요?
ETL 패턴에서는 데이터 웨어하우스나 데이터 마트에 적재하기 전에 데이터가 원활하게 변환되어야 하기 때문에 데이터 파이프라인을 구성할 때 데이터 변환 작업을 사전에 정확히 예측하여야 합니다.
반면에 ELT 패턴에서는 데이터를 적재한 후, 변환 작업을 나중에 수행하기 때문에 데이터 변환 작업에 대한 예측이 덜 필요합니다. 이는 데이터를 변환하는 과정에서 생길 수 있는 문제를 더욱 빠르게 해결할 수 있도록 도와주며 데이터 분석가가 데이터를 활용하는 데 더 많은 옵션과 유연성을 제공하게 됩니다. 기본적으로 데이터 분석가는 적재된 데이터를 직접 조작하여 변환을 수행할 수 있게 되고 더 다양한 분석 작업을 수행할 수 있게 됩니다.
ETL과 ELT 패턴은 데이터 파이프라인을 구성하는 방법론이지만, 각 방법론은 데이터 변환 작업에 대한 예측과 데이터 분석가가 데이터를 활용하는 데 필요한 옵션과 유연성에 차이가 있습니다.
아하! 분석 조직이 조금 더 빠르고 유연하게 움직일 수 있는 환경!
마치며
데이터 파이프라인은 상황과 목적에 따라서 다양한 방식으로 설계될 수 있지만, 오늘 다뤄 본 ELT 패턴은 데이터 분석가가 데이터를 통해 가치를 제공할 수 있는 “자율성”과 “권한 측면” 그리고 “분석 조직이 유연하게 움직일 수 있는 환경이다”라는 측면에서 장점을 가지고 있다고 생각합니다.
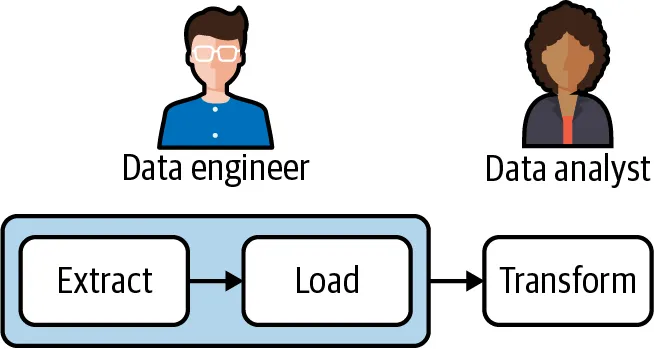
출처 : James Densmore의 Data Pipelines Pocket Reference
또한 데이터 엔지니어는 데이터 분석가가 개발한 변환 코드를 자동으로 배포할 수 있는 데이터 인프라를 구축하여 변환 작업을 지원할 수 있으며 데이터 수집과 적재에 집중할 수 있습니다. 데이터 분석가는 수집된 데이터에서 필요한 데이터를 직접 변환하여 분석에 활용할 수 있게 됩니다.
ELT 패턴은 조직 문화 측면에서도 데이터 팀 구성원들 간의 상호 의존성을 낮추고, 업무 책임과 권한을 분리함으로써 보다 효율적으로 일할 수 있는 구조를 제공할 수 있을 것입니다. 이를 통해 데이터 팀은 업무에 더욱 집중할 수 있으며, 데이터 분석 작업에 필요한 시간과 비용을 절감할 수 있게 될 것입니다.
위에서 언급하였지만, 데이터 파이프라인은 상황과 목적에 따라서 다양한 방식으로 설계될 수 있기 때문에 해당 글을 통해서 ELT 패턴에 대한 메커니즘이 잘 전달될 수 있기를 기대��하며, “나는 현재 어떤 환경에서 분석을 수행하고 있지?”라는 질문을 통해서 일하고 있는 환경에 대해서 한번 생각해 볼 수 있는 계기가 되었으면 좋겠습니다.
추후에는 ELT 패턴에서 데이터 수집과 적재, 변환 과정이 분리되면서 나타나게 된 Analytics Engineering이라는 주제를 한번 다루어 보려고 합니다.