Table Of Contents
지난 11월, 실무에서 인과관계에 대답하기 위해 노력했던 과정에 초점을 맞추어 Causal Inference KR에서 스타트업에서의 인과추론 발표를 진행했습니다. 오늘은 슬라이드의 주요 내용들과, 추가적으로 담지 못했던 이야기들을 글로 풀어내려고 합니다.
- 원 글은 작성자 블로그에서 보실 수 있습니다.
- 발표 자료는 Slideshare에서 보실 수 있습니다.
인과추론에 빠져드는 이유
데이터 분석가는 왜 인과추론에 빠져드는가?
- 대 그로스 시대 : 2018년부터
대 그로스 시대로, 그로스 해킹이 트렌드화, 제품화되어 모든 직군이 이전보다 수월하게 데이터를 보기 시작했습니다. 이에 사내에서도 실험에 대한 인기가 뜨겁습니다. - 실험을 설계할 때, 복잡도가 올라가는 경우 : 빠른 시간 동안 여러 조합을 실험하고 싶어 실험군과 변인의 개수를 증가시킬 경우 설계가 복잡해집니다. 저는 2021 Summer Session 강의들과 연구 및 해외 블로그 글을 보며 어떻게 세팅했는지 참고하기 시작했습니다.
- 실무에서 실험이 불가능한 상황 : 실험을 하지 않았지만, 그래도 이벤트의 효과가 어떠하냐는 질문에 대답해야 하는 경우들이 있습니다.
기업에서 인과추론이 가지는 의미
기업에서 인과추론이 가지는 의미는, 데이터 분석 방법론을 활용하는 것 그 이상이라고 생각합니다. 기업의 의사결정이 데이터, 논리, 인과관계를 기반으로 이루어질 수 있는 문화를 만드는 것이 궁극적인 그 목표일 것 같습니다.

궁극적인 목표로 가기 전, 일상적인 논의에서부터 데이터, 인과관계라는 키워드가 많이 언급되는 것이 변화의 첫 시작으로 보고 있습니다.
실제 매스프레소에서의 대화 예시영희 : (상관 관계를 그리는 차트를 보며) 무료 체험 의지를 가진 유저가 동영상을 더 많이 보는 것 같습니다.철수 : 이게 인과냐 상관이냐 문제에 있어서.. 동영상에 대한 니즈가 많은 유저가 무료 체험을 많이 한다일 수 있어보입니다.
기업에서 인과추론 활용에 대한 인식
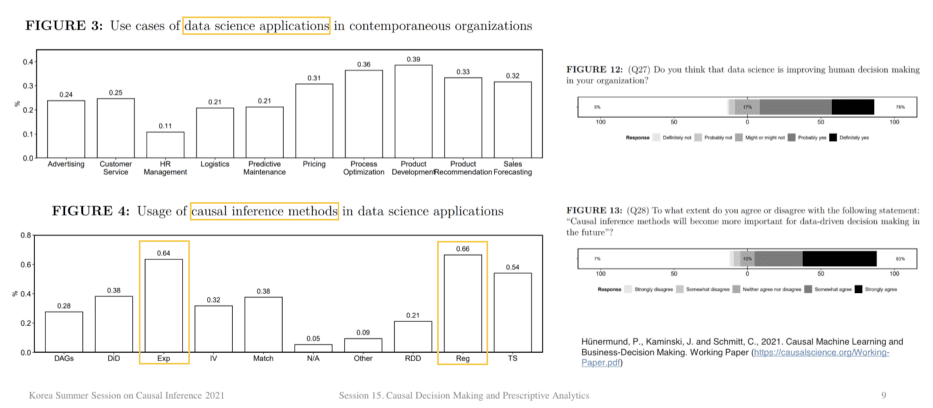
Data Science 를 기업에서 활용하는 사례와, 그 중요성은 비교적 다양하게 널리 알려져 있는데요. Causal Inference 는 ‘실험’의 형태로 활용되고, ‘실험’은 모바일 앱의 성장을 위해 중요하다고 인식되고 있는 것 같습니다. 대신 실험이 아닌 다른 대안 방법론들은 난이도가 높아서 널리 알려지지 않은 것 같아요.
- 기업에서의 Data Science 활용 중, 어떤 Causal Inference Method가 더 많이 사용되는가? : Regression > Experiment > Time Series > DID
- 미래 Data-driven 의사 결정을 위해, Causal Inference Method가 더 중요해질 것인가? 에 Strongly Agree하는 응답자의 비중이 높습니다.
슈퍼앱 트렌드, 기능을 늘리는 게 MAU 성장에 도움이 될까?
MAU : Monthly Active User (월간 활성 이용자 수)
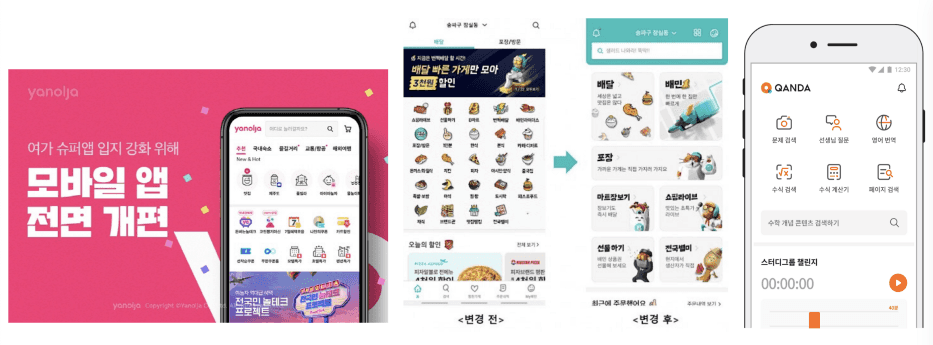
슈퍼앱이란
여러 서비스 및 기능을 하나의 앱에 담은 형태를 의미합니다. 슈퍼앱은 본래의 트래픽을 키울 수 있었던 기능의 도메인을 기반으로 서비스를 확장하는데요. 아래와 같은 예시가 있습니다.
| 서비스 | 분야 | 어떤 기능으로 확장했을까? |
|---|---|---|
| 야놀자 | 여가 슈퍼앱 | 숙박 → 교통, 해외 여행, 원데이 클래스 등 |
| 배달의 민족 | 푸드 슈퍼앱 | 음식 배달 → 장보기, 쇼핑라이브, 선물하기, 맛집 배달 등 |
| 콴다 | 교육 슈퍼앱 | 문제 검색 → 타이머, 문제집, 퀴즈 이벤트, 학생 커뮤니티 등 |
| 토스 | 금융 슈퍼앱 | 간편송금, 간편결제 → 보험, 증권, 인터넷 은행 서비스 등 |
실무에서 이런 질문이 들어왔다
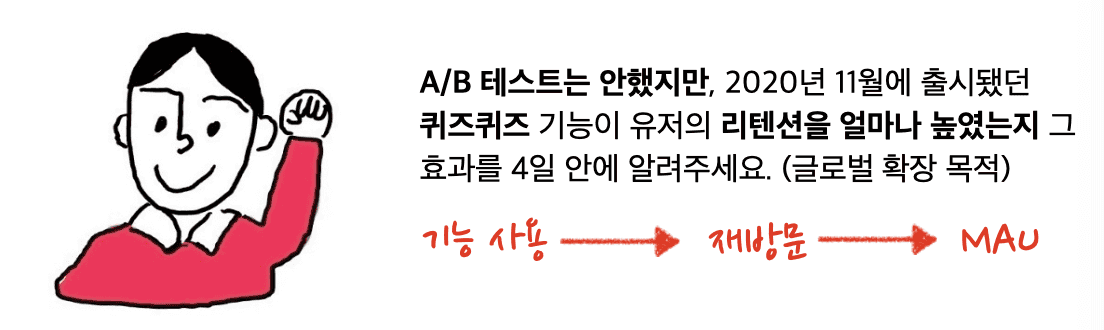
어느 평화로운 날, 꽤나 막막한 질문이 들어왔습니다. 테스트를 진행하지 않은 기능에 대해서 리텐션에 준 인과 효과를 묻는 질문이었어요. 콴다도 교육 슈퍼앱으로서 여러 기능들을 확장했고, 그 중 일부 기능이 MAU라는 전사 지표에 어떤 영향을 주는지 알고 싶은 것으로 보였습니다.
교육 슈퍼앱에게 퀴즈퀴즈 기능이란
퀴즈퀴즈 기능은, 콴다 한국 앱에서 추가된지 1년 가량 지난 기능으로 매주 2 ~ 3회 열리는 수학 퀴즈 대회입니다.
대회에서 1등으로 우승하면 ‘코인’을 제공하고, 이 ‘코인’ 은 앱 내에서 선생님들에게 질문할 때 사용할 수 있는 화폐 단위이며 유료 충전도 가능합니다. 유저들이 스스로 되찾는, 인기가 좋은 기능 중 하나였습니다.

고민의 과정
| 고민 💡 | 결론 |
|---|---|
| 통제 집단으로 사용할 수 있는 샘플이 있을까? (예: 다른 국가, 출시 시기가늦어졌던 OS, 기능이 없는 앱 버전을 사용하는 유저, 기능이 배포되지 않은 학년 등) | 없다 😭 |
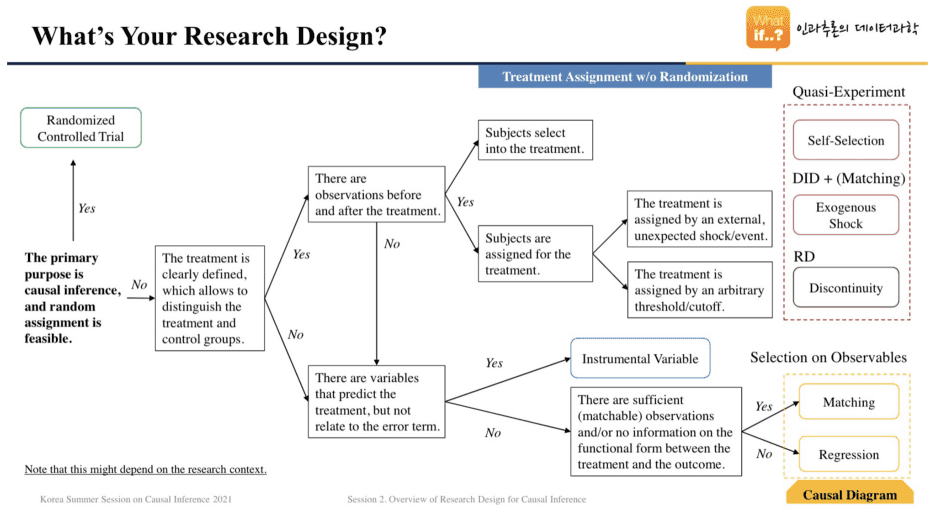
| 아래 Summer Session 의 Flow Chart를 따라가면 어떤 방법을 쓸 수 있을까? | 이해가 조금 어려우나, 적합해보이고 강의에서 배우고 이해했던 Difference-in-Differences를 사용하자. |
Matching & DID
대조군 없이 100% 배포가 되었던 상황이므로, 대조군처럼 사용할 수 있는 집단을 찾아서 통제 집단으로 가정했습니다. 통제 집단 대비 실험군에서 발생한 지표의 증분 상승을 통해서 인과 효과를 추정하는 Difference-in-Differences 방식을 사용했습니다.
특히 이 통제 집단을 찾기 위해서 Look-forward Matching 을 사용했습니다. 어떤 방식으로 사용했는지 설명을 위해, 아래 슬라이드를 첨부합니다.
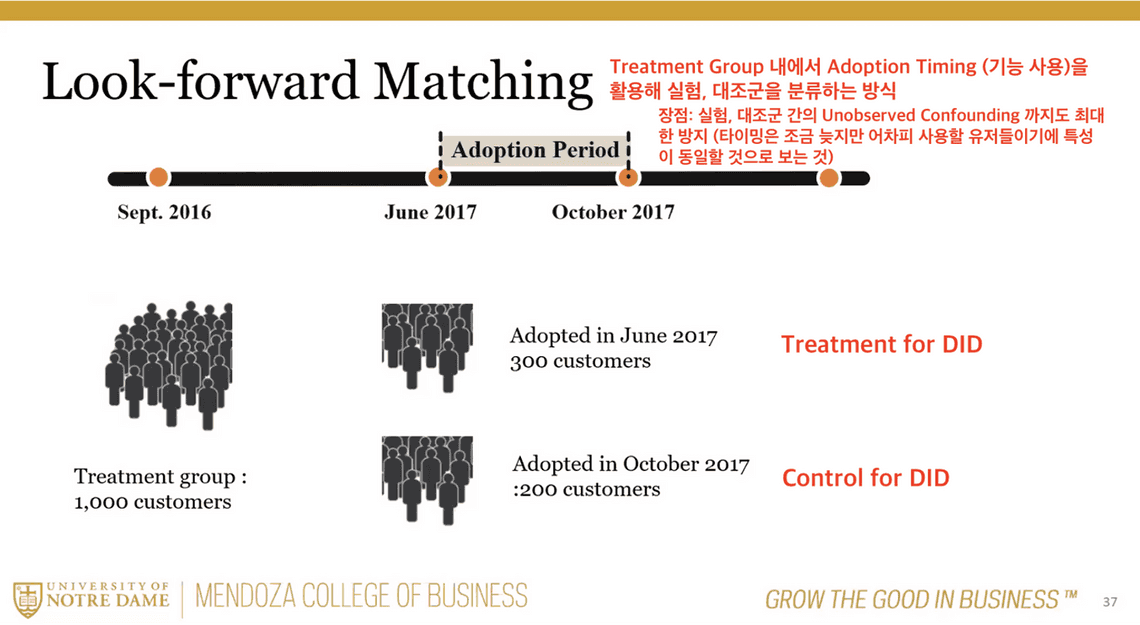
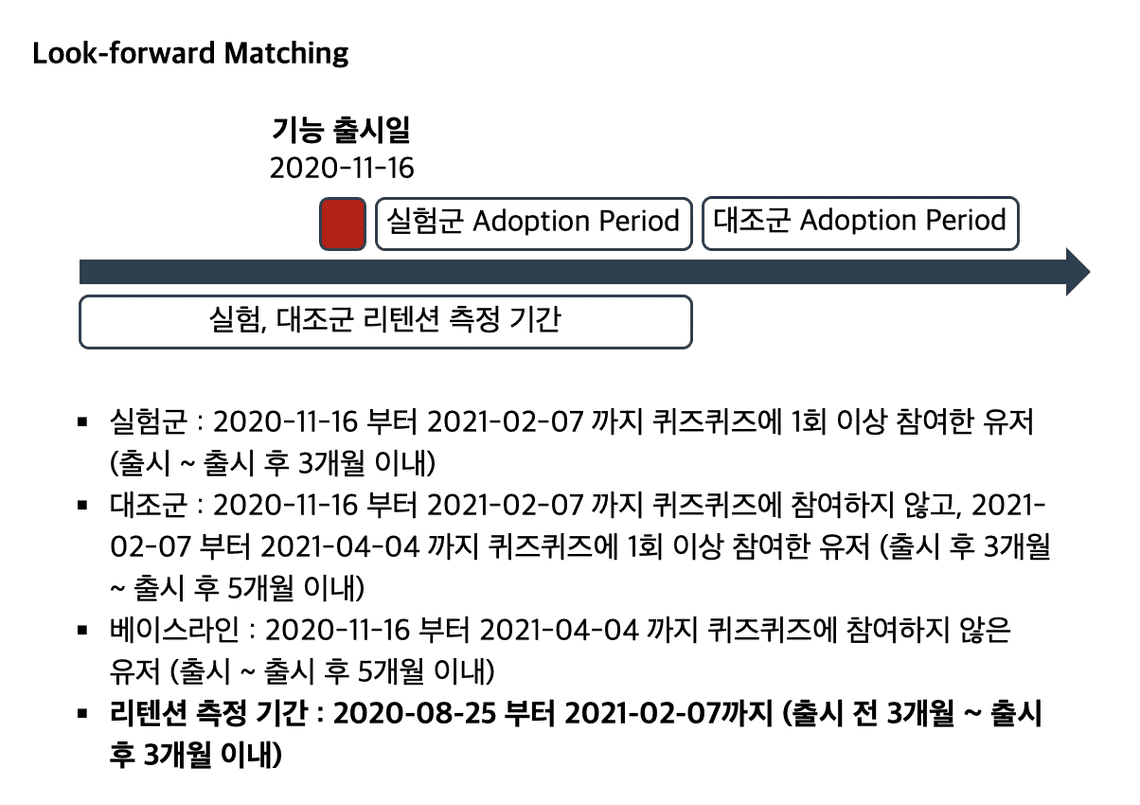
분석 결과는 다음과 같았습니다. 퀴즈퀴즈 기능 출시 직후, 퀴즈퀴즈 기능을 사용하는 행동이 주별 방문 리텐션을 4%p 가량 증가시키는 효과를 보였습니다.
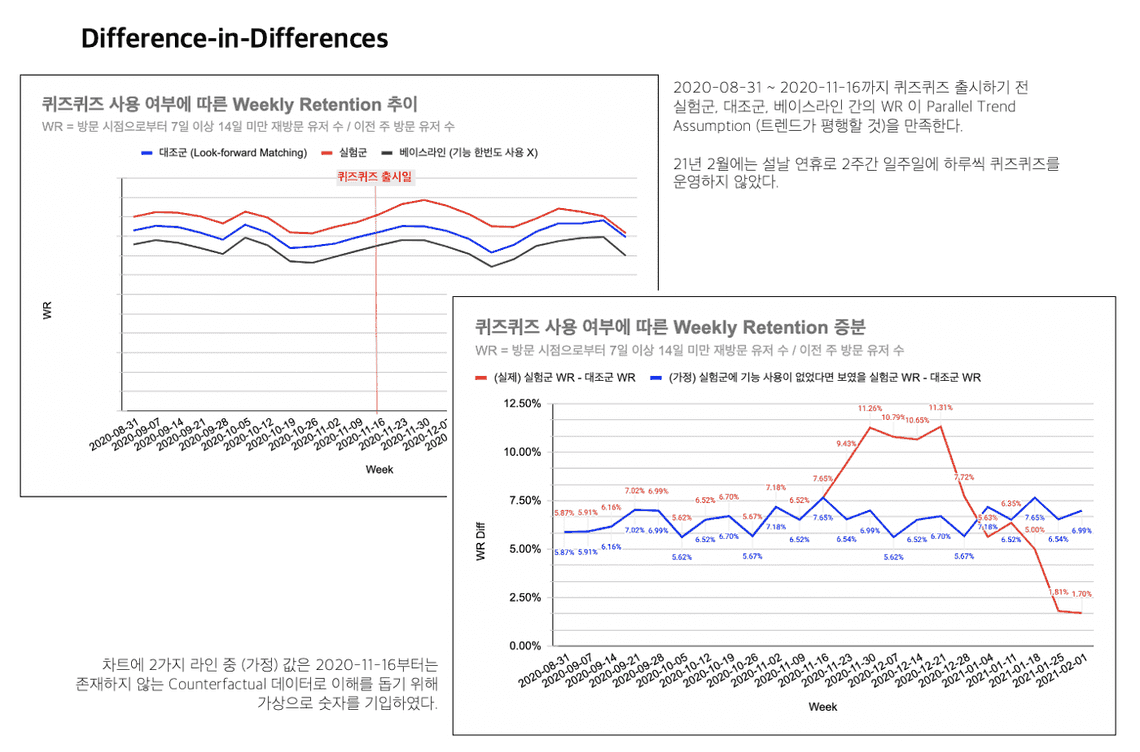
Matching & DID Limitations
- Look-forward matching 에서 실험군과 통제 집단 사이에 차이를 줄 수 있는 변수를 생각해봤을 때 가입일 분포가 다를 수 있을 것으로 판단했습니다. 간단하게 확인한 결과,
기능 출시일 — 가입일의 평균을 두 그룹간 비교할 경우 7일 정도 차이를 보였습니다. (평균 500 ~ 600일대) - 프로젝트에 주어진 시간의 한계로 Robustness check를 위해 어떤 걸 해보면 좋았을까? 에 대한 고민과 실행이 모자랐다는 점입니다.
- 1월에 실험군의 WR이 감소하는 경향을 퀴즈퀴즈 운영 플랜 변경 외로, 다른 설명할 수 있는 원인을 찾기 어려웠던 점입니다.
CausalImpact
앞서 진행한 분석 결과의 신뢰도를 높이기 위해서 추가적인 Method를 활용해서 인과 효과에 대한 결과를 함께 보았는데요. 예측을 통해 가상의 데이터를 생성하여 Synthetic Control로 사용하는 CausalImpact 패키지를 활용했습니다.
주로 CausalImpact 를 사용하게 되는 상황은 다음과 같습니다.
- 대조군으로 유추할 수 있는 데이터가 1개도 없는 상황입니다.
- 이벤트 이전의 데이터들을 기반으로, 이벤트 이후 기간에 ‘이벤트’가 없었을 경우의 y의 흐름을 예측합니다.
- 예측된 그 y의 흐름이 곧 Synthetic Control로, 가상의 대조군으로 사용합니다.
실제 데이터(실험군) — 가상의 대조군 = 이벤트를 통한 인과 효과와 같이 추정합니다.
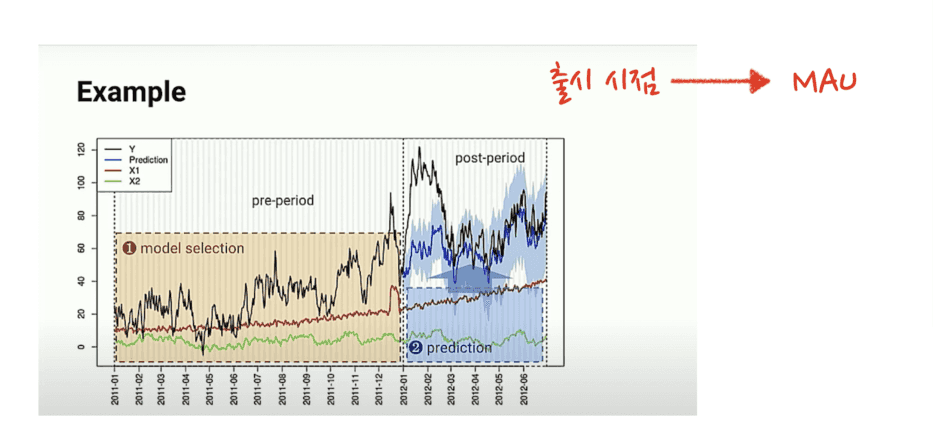
분석 중 주요하게 신경 썼던 부분은 아래 2가지 입니다.
- 이벤트 이후 y의 예측에 있어서, 이벤트 이전의 y와 상관이 높은 공변량 변수들을 찾고, 검증하는 과정
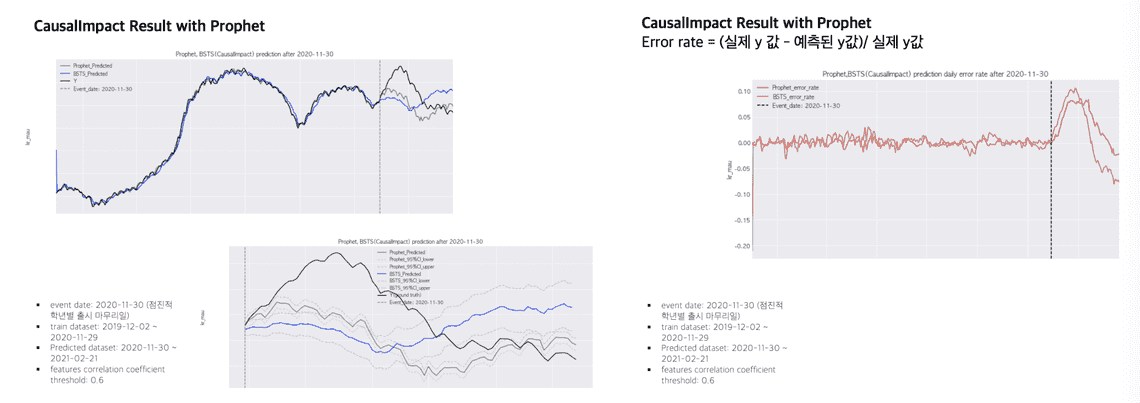
(y: daily MAU) - Google CausalImpact의 기본이 되는 인과 효과 추정에 사용되는 예측 모델은 텐서플로우의 Bayesian Structured Time Series (BSTS)입니다. Time-series forecasting and causal analysis in R with Facebook Prophet and Google CausalImpact (2020.09)를 참고하여,시즈널리티 반영 및 튜닝할 수 있는 여지가 많아 성능이 좋기로 유명한 시계열 예측 패키지 Facebook의 Prophet과의 오차 비율을 함께 보았습니다. BSTS와 Prophet의 y값이 유사해지도록, 또한 각 모델이 이벤트 이전 y 데이터에 오버피팅이 되지 않도록 파라미터들을 조정했습니다.

공변량 변수(Covariates) 는 아래와 같이 사용했습니다. y인 한국의 Daily MAU와 상관 계수 0.6 이상인 변수만 사용했습니다.
- 동 시기에 특정 이벤트(퀴즈퀴즈 출시)가 없��었던 국가의 Daily MAU (Daily Sliding Window)
- 경쟁사 DAU (Sensortower 활용)
- 검색어 트래픽 (Google Trends)
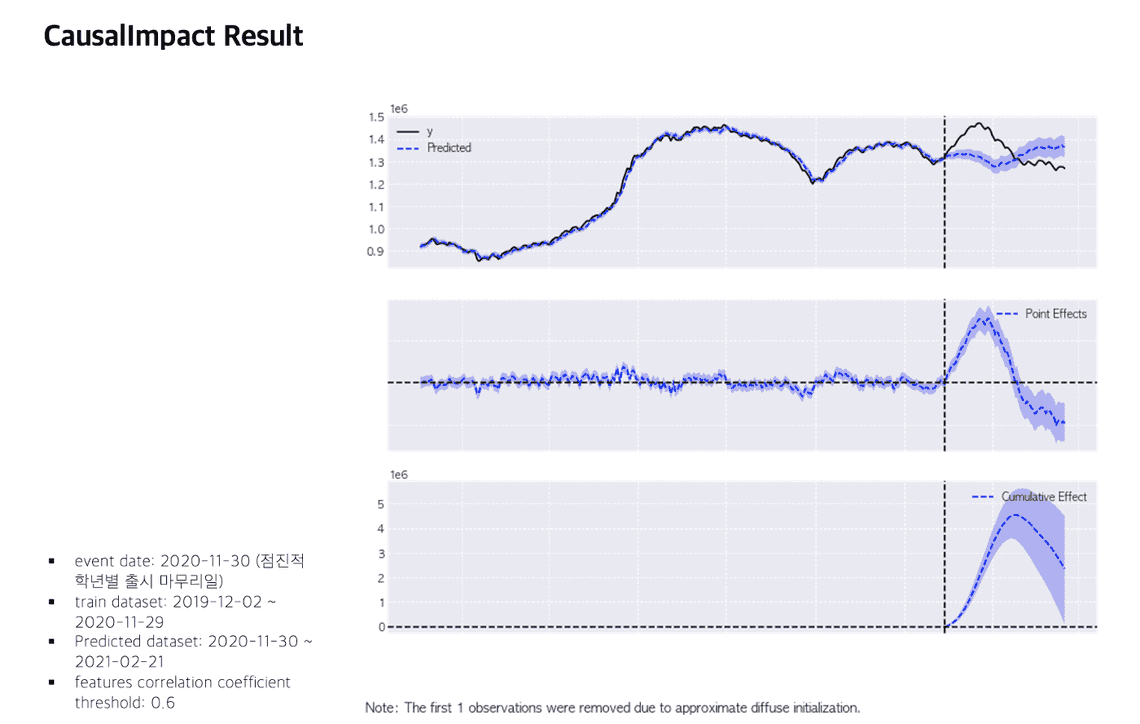
분석 결과 는 다음과 같았습니다. BSTS 기준 퀴즈퀴즈 출시일 이후 평균적인 Daily MAU 증가는 +2.13% 였습니다.
BSTS 기준 95% Interval : [0.08%, 4.08%]BSTS p-value : 0.02
CausalImpact Limitations
1. Quasi-experiments 및 Counterfactuals의 한계점
- 특정 시기를 기점으로 이벤트 전후의 인과 효과를 측정하므로,
기능 출시뿐 아니라 이 시점의여러 가지 이벤트 및 다른 roll out, A/B 실험의 효과는 배제할 수 없습니다. - 급 성장하는 스타트업의 경우, 데이터의 주기성이 없어 시계열 예측이 어렵습니다.
- y에 영향을 미치기 어려울 정도로 작은 효과는 감지하기 어렵습니다.
- 모든 것을 큰 단위로 묶어서 보기 때문에, 유저 단위의 효과로는 파고들 수 없습니다.
2. CausalImpact를 사용함에 있어서의 한계점
- 성능이 좋은 Prophet 패키지와 추세를 유사하게 그리도록 파라미터를 바꿔보지만, 결과의 신뢰성을 높여줄 validation으로는 충분하지 않다고 생각합니다. CausalImpact 활용에 있어서 sensitivity analysis를 어떻게 연결할 수 있을지 해답을 찾지 못했다는 점이 한계입니다.
- (참고) PyData New York 2019에서 HelloFresh(밀키트 배달 서비스)에서 지역별 실험이 어려워 Google Causal Impact를 사용한 발표를 보여줬는데요. 특별한 Validation 절차는 명시하지 않고 CausalImpact를 돌려보고 리포트 결과를 해석하며 발표를 마무리합니다. 자세한 분석 내용이 설명되지 않은 걸 수도 있지만, 다들 겪고 있는 Painpoint 인가? 하는 생각이 들었습니다.
느낀 점
역시나 더 많은 공부를 해야겠습니다. 특히 Robustness Check / Sensitivity Analysis 부분을 더 공부해서 향후 더 신뢰할 수 있는 분석 결과를 만들고 싶습니다.
그리고 발표 현장에서 참석자 분들께서 실무 인과추론 활용 사례와 느꼈던 한계점을 나눠주셨는데요. 덕분에 재미난 썰들이 오가며 즐거운 자리가 되었습니다.
전체 발표 자료가 궁금하신 분들은 Slideshare 에서 확인하실 수 있습니다! 😁