Table Of Contents
- 부제: 실험 결과 데이터 분석: ATE, CATE, HTE
- 원 글은 작성자 블로그에서 보실 수 있습니다.
프로덕트에서 다수의 A/B 테스트를 진행하는 동시에 인과 추론 공부를 하면서 했던 생각이 있는데요. ‘작은 실험도 하나의 연구인데, 이렇게 빠르게 결과만 보고 지나가도 되나?’ 라는 생각이었어요.
속도가 강조되는 스타트업의 페이스를 맞춰��주는 것도 중요하지만, 데이터를 보는 사람의 입장에서 현상을 더 깊게 파고 들어가고 싶은 마음이 드는 것은 도저히 거부할 수가 없는데요.
그래서 오늘은 실험 결과를 조금 더 깊게 분석할 때 알아두면 시야가 넓어지는 기본 개념들을 소개하려고 합니다.
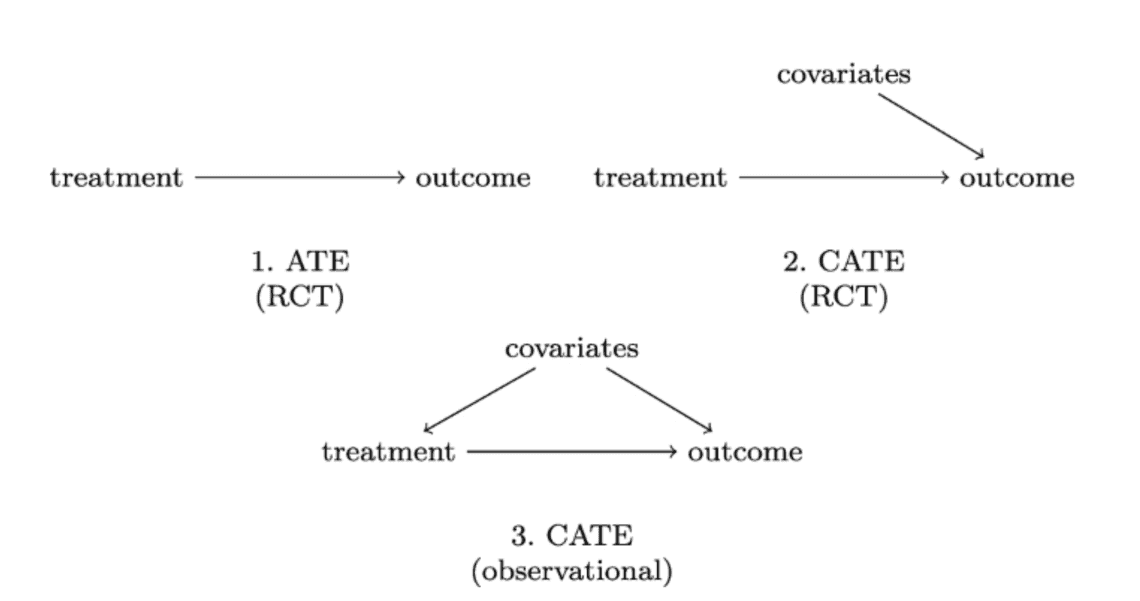
ATE (Average Treatment Effect)
일반적으로 사용되는 A/B 테스트 분석 방법을 ATE (Average Treatment Effect)라고 칭하며, 이 방법은 개입의 인과 효과를 전체 집단의 레벨에서 설명합니다.

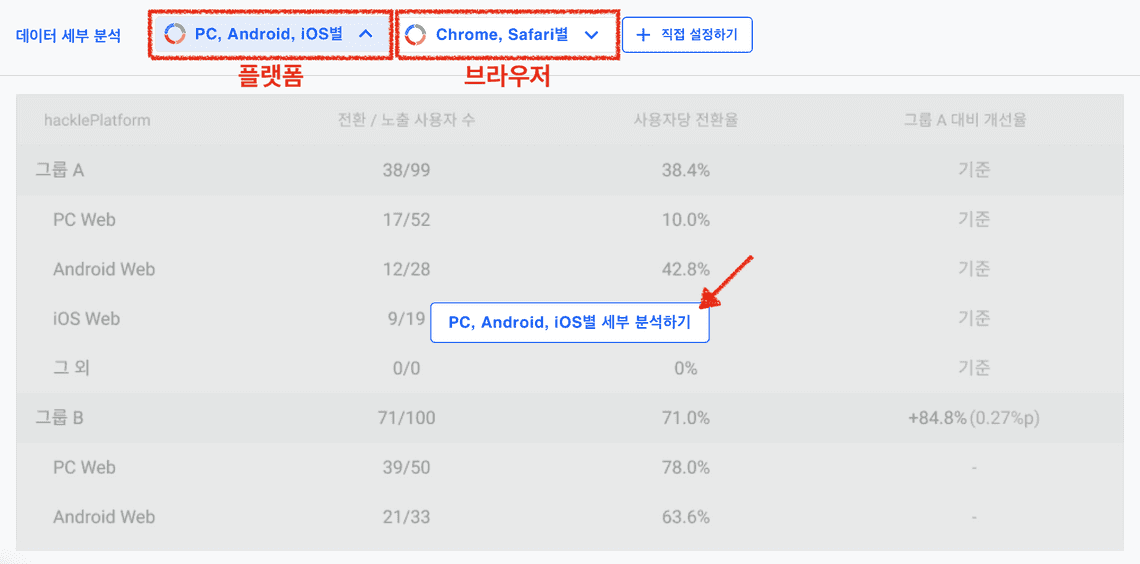
A/B 테스트의 결과는 주로 간단하게 위와 같이 배너 광고 A, B를 보여준 각 집단에서 반응한 유저의 비율을 집계합니다. 이를 보고 배너 광고 B 집단의 반응률이 25% 더 높으니 B를 선택하며 전체에 Rollout 하는 의사 결정을 내릴 수 있습니다.
CATE (Conditional Average Treatment Effect)
CATE(Conditional Average Treatment Effect) 는 유저의 특성(공변량 변수, Covariates)에 따라 한정되는, 국지적인 인과 효과를 의미합니다. 여기서의 공변량 변수는 예로, 성별, 나이, 소득 수준과 같은 유저의 특성이 있겠습니다.

ATE로 확인했다면 성공적이지 못한 실험 결과를, CATE로 공변량 변수를 어떻게 정의하고 쪼개보느냐에 따라 확인해볼 수 있는 인사이트가 달라집니다.
다만 실험군에서의 증분이 보일 때 까지 쪼개는 �방식으로 분석을 진행할 수 있다는 점을 경계해야 합니다. 분석을 진행할 때 쪼개진 후 그룹간의 증분의 통계적 유의성이 보장되도록 한다-와 같은 규칙을 마련하는 것이 좋을 것 같습니다.
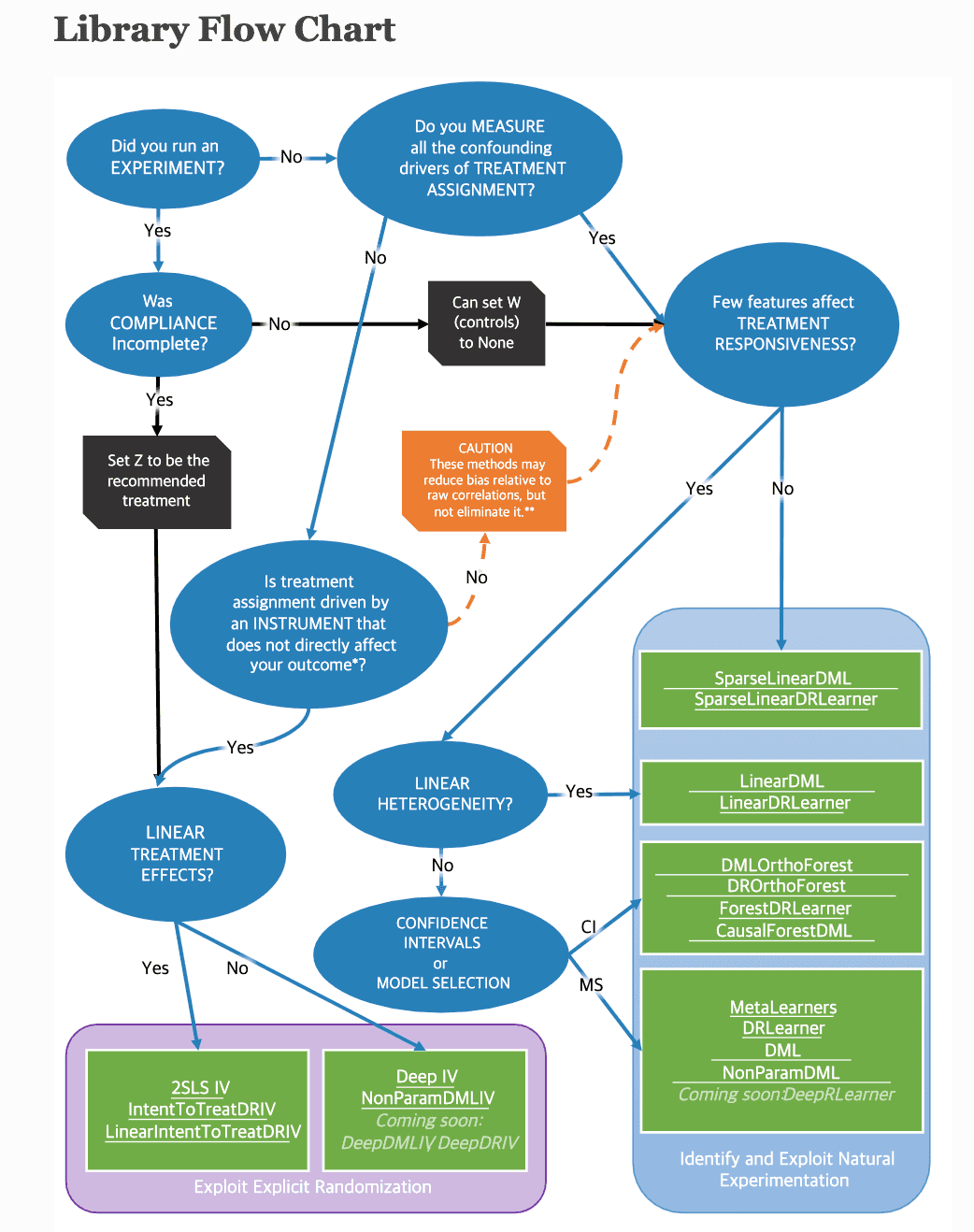
특히 2019년에 Microsoft의 ALICE Team에서 CATE 추정에 특화된 Python Package EconML 를 개발했는데요. EconML은 단순한 실험 데이터에 Machine Learning 과 Deep Learning 을 도입하여 어떤 특성을 가진 유저에게 실험의 처치 효과가 극대화될 수 있는지 비즈니스 기회를 탐색할 수 있게 해주는 장점이 있습니다.
HTE (Heterogenous Treatment Effect)
Heterogenous Treatment Effect (HTE)란 CATE간의 차이를 의미합니다. 데이터를 계층화(stratify)하고, 각 계층(strata) 내에서 ATE를 추정하여 계층 간의 차이를 비교(subgroup analysis)합니다.
이 CATE를 추정하는 모델은 다양한 종류가 있고, 그 중 하나가 Uplift modeling이며 머신 러닝을 통해 인과 효과를 추론하는 방법입니다. 좀 더 자세히는, Meta-learner를 활용해 CATE를 예측하는 방법입니다.
Meta-learner란 일반적인 Supervised learning model(i.e. Base-learner)을 인과 효과를 추정하기 위해 다양하게 활용하는 알고리즘을 의미합니다.
인과 효과 모델링에서는 근본적으로 Ground Truth가 없기 때문에, 일반적인 Supervised learning에서의 가정을 만족하지 못합니다. 실제 인과 효과는 알 수 없는 신의 영역이기 때문에, 보통 가능한 모든 Meta-learner를 사용해보고 가장 정확한 인과 효과 추정치를 내는 모델을 선택한다고 합니다.
Meta-learner 각 알고리즘의 장단점을 인지하고, Uplift modeling을 사용하는 상황과 데이터셋의 크기에 맞게 선택해야 합니다. Meta-learner 알고리즘의 종류에는 S, T, X 가 있는데요. 즐겨보는 블로그에서 인과 관계 분석 시리즈 (4): 머신러닝을 이용한 인과관계 추론 (feat. Metalearners) 에 상세한 설명이 있어서 참고하면 좋을 것 같습니다.

다양한 레퍼런스를 찾아보며 용어가 헷갈렸는데요. 실제로 다양한 분야에서 연구되면서 HTE, CATE, Subgroup analysis, Uplift modeling 등 용어가 통일되지 않은 문제가 있다고 합니다. (Rolling, 2014)
The lack of a common framework and language for this problem may contribute to the disconnect; phrases used for conditional treatment effect estimation include heterogeneous treatment effect estimation, subgroup analysis, incremental response modeling, uplift modeling, and true lift modeling.
DoorDash 예시로 HTE 이해하기
DoorDash Engineering Blog 의 Leveraging Causal Modeling to Get More Value from Flat Experiment Results을 참고했습니다.
Doordash는 유저 대상으로 프로모션 캠페인의 성과를 높이기 위해 HTE Model을 사용했다고 합니다.
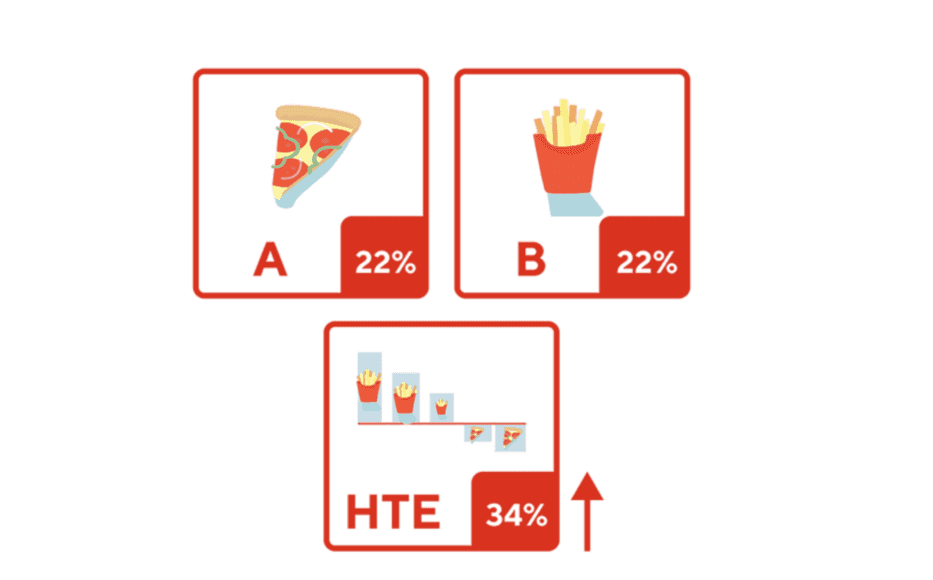
- 이해를 돕기 위해, Doordash에서 실험군 A에게
피자를 리뷰 이벤트로 제공하고, B에게감자 튀김을 리뷰 이벤트로 제공했다고 합시다. 실험의 Target Metric은재 주문율이라고 합시다. - ATE 관점 (Classic A/B Testing)을 사용한다면?
- 실험군 A, B가 모두 재 주문율 22%를 보였습니다. 따라서 리뷰 이벤트로 준 메뉴에 따라 평균적으로 유저들이 차이를 보이지 않았습니다. 즉, 실패한 A/B 테스트인거죠.
- HTE 를 사용한다면?
- 먼저 5가지 subpopulation을 구분합니다. 실험의 결과를 구분한 5가지 세그먼트별로 측정한 후, 실험에서 상승 효과가 있었던 3개의 세그먼트에
감자 튀김 리뷰 이벤트를 Rollout합니다.
- 먼저 5가지 subpopulation을 구분합니다. 실험의 결과를 구분한 5가지 세그먼트별로 측정한 후, 실험에서 상승 효과가 있었던 3개의 세그먼트에
DoorDash 블로그 글에서는 HTE Model 의 장점을 이렇게 이야기합니다.
- Subpopulation 에게 선택적으로 Rollout 함으로써 향상된 개인화
- Flat 한 실험 결과에서 가치를 극대화하는 것을 도울 수 있는 방법론
“Improved personalization — i.e. by rolling out the new variant selectively to the subpopulations that had a positive reaction.”
In this way, such causal modeling approaches — also known as Heterogeneous Treatment Effect (HTE) models — can help to substantially increase the value of flat experimental results.
개념이 헷갈릴 때 들여다보면 좋은 레퍼런스


