Table Of Contents
- 원 글은 작성자 블로그에서 보실 수 있습니다.
A/B 테스트를 진행하기 앞서 늘 고민되는 것은 “적절한 샘플 사이즈는 얼마일까?”일 것입니다. 그리고 이 고민을 해결해주기 위해 웹에는 상당히 많은 수의 A/B 테스트 샘플 사이즈 계산기가 공개되어 있습니다. 숫자를 입력하면 샘플 사이즈가 출력되는데, 도대체 어떻게 샘플 사이즈가 구해지는 것인지 궁금했던 분들이 있을 것입니다. 아쉽게도 이번 글은 샘플 사이즈가 구해지는 공식과 원리를 낱낱이 파헤치는 글은 아닙니다. 하지만 A/B 테스트 샘플 사이즈 계산기에 숨어있는 통계적인 개념들을 살펴봄으로써 실험에서 어떤 부분을 주의해야할지 정리해보고자 합니다.
1. p-hacking
통계적 가설 검정을 수행할 때는 P값(p-value)을 이용하여 관습적으로 P값이 0.05보다 작은 경우 통계적으로 유의미한 것으로 간주합니다. p-hacking은 통계적으로 유의미한 결과를 얻기 위해 유의수준(P < 0.05)보다 낮은 P값을 얻기 위해 데이터를 선별하거나 데이터를 가공하는 등의 작업을 하는 것을 말합니다.
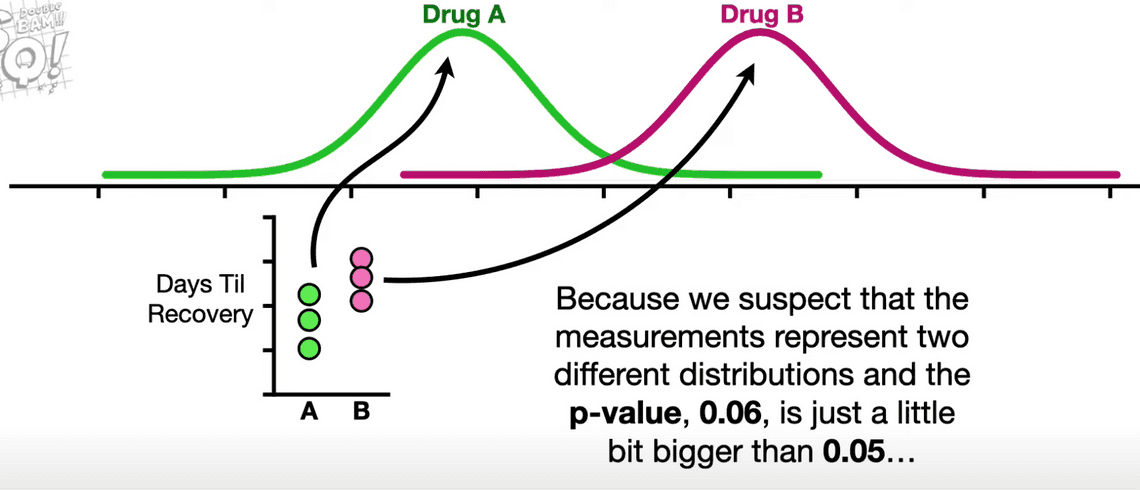
데이터를 가공하지 않더라도 데이터를 추가하는 방식으로 p-value 값에 영향을 줄 수 있습니다. 예를 들어 위와 같이 두 통계적 분포에서 추출한 데이터 포인트(data point)들이 있다고 가정해봅시다. 그리고 이를 통해 구한 p-value가 0.05보다 약간 큰 0.06이라고 해봅시다. 이 때 아래와 같이, 각 그룹에 데이터 포인트를 하나씩 추가한 다음 평균을 다시 구하고, p-value를 다시 구합니다.
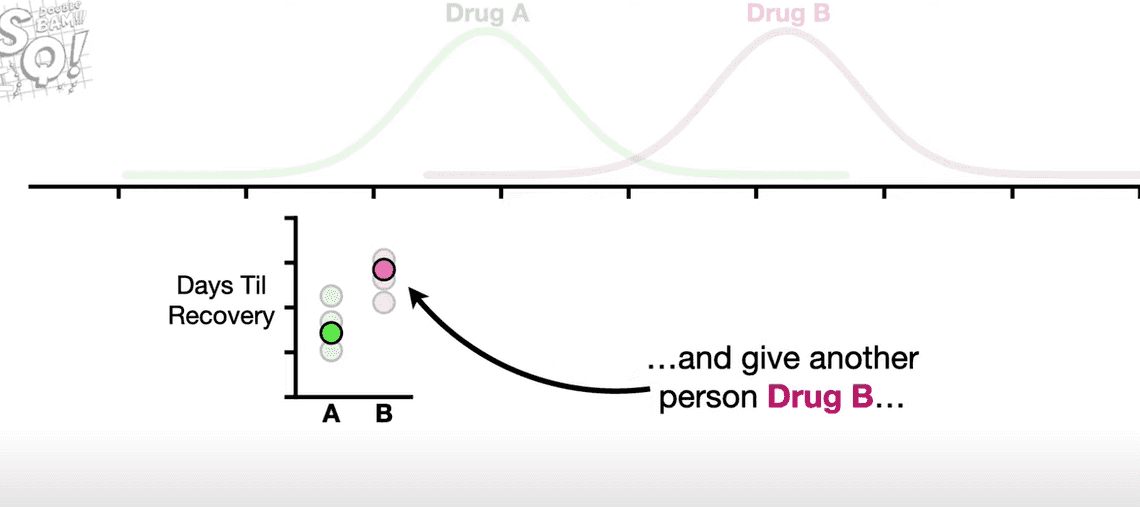
이 경우 기존보다 더 낮은 p-value를 구하고, 통계적으로 유의미한 결과를 얻어낼 수 있습니다. 하지만 정말로 유의미한 결과를 얻은 것이 아니라 p-hacking에 해당합니다.
실험�을 진행할 때도 이와 유사한 상황이 발생할 수 있습니다. 바로 통계적으로 유의하지 않은 결과를 확인하고도 실험을 지속하는 경우입니다. 예를 들어 실험을 진행하여 얻은 p-value 값이 0.06이라고 가정해봅시다. 사전에 설정한 유의수준이 0.05라고 할 때, 통계적으로 유의하지 않습니다. 하지만 실험을 중단하는 대신 실험을 더 지속하기로 합니다. 결국 실험 결과를 다시 확인한 결과, p-value 값으로 0.04를 얻습니다.
이 경우 통계적으로 유의한 결과를 얻었다고 마냥 좋아해서는 안 됩니다. P값은 표본 수에 영향을 받기 때문입니다. 표본평균 차이가 동일하다고 할 때 데이터의 크기가 커질수록 p-value는 작아집니다.
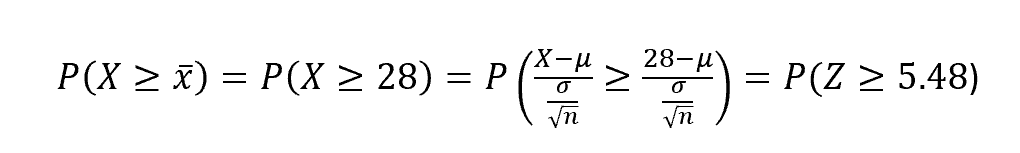
그러므로 낮은 p-value 값이 항상 의미 있다고 생각해서는 안 됩니다. 위 경우 불순한 의도를 가지고 p-value를 조작한 것은 아니지만 의도치 않게 p-value에 영향을 준 것입니다. 이렇게 표본 수에 따라 실험의 통계적 유의성을 오판할 수 있으므로 적절한 샘플 사이즈를 실험에 앞서 결정하는 것이 중요합니다. 그리고 이를 위해 필요한 것이 검정력 분석(power analysis)입니다.
2. power analysis
검정력 분석은 4가지 인자(factor)에 영향을 받습니다. 그리고 아래 4가지 인자 중 3가지 인자가 결정되었을 때 나머지 하나의 변수 값을 구하는 분석입니다.
- 통계적 검정력(statistical power): 대립가설(alternative hypothesis)이 사실일 때 귀무가설(null hypothesis)을 기각(reject)할 확률
- 샘플 사이즈(sample size): 주어진 검정력(power)을 보장하기 위해 필요한 최소한의 관측치 수
- 유의 수준(Significance level): 귀무가설(null hypothesis)이 사실임에도 이를 기각(reject)할 확률
- 효과 크기(effect size): 비교하려는 집단 사이에 얼마나 차이가 있는지를 나타내주는 지표
통계적 검정력(statistical power)이란 “대립가설(alternative hypothesis)이 사실일 때 귀무가설(null hypothesis)을 기각(reject)할 확률”을 말합니다. 대개 0.8로 설정합니다.
A/B 테스트에서의 검정력은 “A/B 테스트를 진행할 때, 실제로 A그룹과 B그룹이 유의미한 차이가 있을 경우 두 그룹이 차이를 보인다는 것을 알아낼 확률” 정도로 볼 수 있을 것입니다. 예를 들어 “’SIGN UP’ 버튼의 문구를 ‘SIGN UP NOW’ 문구로 바꾸면 가입율이 증가할 것이다.”이라는 가설을 바탕으로 A/B 테스트를 진행한다고 가정해보겠습니다.
출처: Optimizely “Obama’s $60 million dollar experiment”
이 때, 검정력이 80%(0.8)이라는 말은 “100번의 실험을 했을 때 80번은 ‘A그룹(SIGN UP 문구가 노출된 그룹)과 B그룹(SIGN UP NOW 문구가 노출된 그룹)의 가입율이 유의미한 차이를 보일 경우, B안을 채택할 수 있다”는 말입니다.
유의수준은 “귀무가설(null hypothesis)이 사실임에도 이를 기각(reject)할 확률”을 말합니다. 대개 0.05로 설정합니다. 유의수준이 0.05라는 말은 “실제 A그룹(SIGN UP 문구가 노출된 그룹)과 B그룹(SIGN UP NOW 문구가 노출된 그룹)의 가입율이 유의미하게 차이가 나지 않더라도 100번 중 5번은 차이가 나는 것으로 보아 B안을 채택할 수 있다”는 말입니다.
마지막은 효과 크기(effect size)입니다. 효과 크기는 “두 집단 간의 차이”를 말합니다. A/B 테스트 샘플 사이즈 계산기의 입력란 중 하나인 “Minimum Detectable Effect”의 “Effect”가 이에 해당합니다. 비즈니스적으�로 효과가 있는 것으로 간주하려면 두 집단이 최소 어느 정도 차이가 나야 하는지를 샘플 사이즈 계산기에 입력하는 것입니다.
4가지 인자 중 특히 주목해야 할 것이 효과 크기입니다. 그 이유는 실험의 통계적 유의성도 중요하지만, 비즈니스에서의 효과 크기도 중요하기 때문입니다. 예를 들어 아래와 같은 실험 결과가 나왔을 때는 통계적으로 유의하더라도, 실제 비즈니스에서의 효과 크기 즉 구매전환율에서의 차이는 크지 않습니다.
| 그룹 | 사용자수 | 구매전환수 | 구매전환율 |
|---|---|---|---|
| 그룹A | 199,978 | 19,965 | 0.099 |
| 그룹B | 200,007 | 19,987 | 0.100 |
실험을 진행하는 담당자에게는 통계적 유의성만큼이나 비즈니스에서의 효과 크기가 중요합니다. 0.001%의 구매전환율 상승이 비즈니스 관점에서 크게 유의미하지 않다면, 0.001%의 효과에 대해 통계적 유의성을 확보하려고 노력하는 것 역시 무의미할 수 있기 때문입니다.

그리고 비즈니스에서 의미 있는 효과 크기는 웹사이트를 방문하는 사용자의 수, 구매전환율 등 서비스의 상황에 따라 달라질 수 있습니다. 예를 들어 하루 100만명이 방문하는 웹사이트의 경우, 구매전환율이 1% 상승하면 고객당 매출이 10000원이라는 가정하에 하루 1억의 매출 상승으로 이어집니다. 하지만 하루 1000명이 방문하는 웹사이트의 경우, 구매전환율이 1% 상승하면 고객당 매출이 10000원이라는 가정하에 하루 10만원의 매출 상승으로 이어집니다. 많은 트래픽이 발생하는 서비스의 경우 작은 비율의 상승으로도 큰 비즈니스 효과로 이어질 수 있지만, 트래픽이 그렇게 크지 않은 서비스의 경우 더욱 큰 비율의 상승이 있어야 의미 있는 비즈니스 효과로 이어질 수 있습니다. 그러므로 각자 비즈니스 상황과 실험의 목표를 고려하여 A/B 테스트 샘플 사이즈 계산기의 “Minimum Detectable Effect”를 설정해야겠습니다.

나가며
p-hacking을 통해 샘플 사이즈에 따라 p-value가 영향을 받을 수 있으며, 이로 인해 실험 결과를 잘못 해석할 수 있다는 점을 살펴봤습니다. 그리고 p-value에 관계 없이 실험에서 오판하지 않기 위해 적절한 샘플 사이즈를 결정하는 것이 중요한데, 이를 검정력 분석(power analysis)를 통해 할 수 있다는 것도 살펴봤습니다.
A/B 테스트 샘플 사이즈 계산기는 검정력 분석 부분에서 언급한 효과 크기(effect size)를 활용하여 샘플 사이즈를 계산합니다. 또한, A/B 테스트 샘플 사이즈 계산기를 활용하면 샘플 사이즈를 충분히 구할 수 있기 때문에 위 개념들을 몰라도 무리가 없을지도 모릅니다. 하지만 이 개념들을 통해 2가지를 짚고 가면 좋겠습니다.
첫번째, 통계적 유의성은 중요하지만, p-value에만 집착한다면 잘못된 해석을 할 수 있다는 것입니다. 예를 들어 통계적으로 유의하지 않은 결과를 확인한 다음 실험을 중단하지 않고 지속 관찰하는 경우, 유의한 p-value값이 나와 조기에 실험을 마치는 경우 모두 잘못된 의사결정으로 이어질 수 있습니다. 이 경우들 모두 p-value에만 집착했기 때문에 발생할 수 있는 상황입니다. 오히려 유의수준에 가까운 p-value 값을 보일 때 더욱 신중하게 결과에 접근해야겠습니다.
두번째, 통계적 유의성도 중요하지만 비즈니스에서의 효과 크기도 중요하다는 것입니다. 물론 실무적으로 미리 효과 크기를 가늠하는 것은 쉽지 않습니다. 그리고 고정된 값으로 보기 힘든, 불확실한 값입니다. 하지만 그럼에도 서비스의 상황과 실험의 목표를 고려하여 적절한 “Minimum Detectable Effect”을 설정해야 하는 이유는 시간과 비용을 투입할 가�치가 있는 실험을 하기 위해서입니다.
긴 글 읽어주셔서 감사합니다. 도움이 되었으면 좋겠습니다.
참고자료
StatQuest with Josh Starmer 채널의 “p-hacking: What it is and how to avoid it!”
https://www.youtube.com/watch?v=HDCOUXE3HMM
StatQuest with Josh Starmer 채널의 “Power Analysis, Clearly Explained!!!”
https://www.youtube.com/watch?v=VX_M3tIyiYk
A/B 테스트에서 p-value에 휘둘리지 않기
https://boxnwhis.kr/2016/04/15/dont_be_overwhelmed_by_pvalue.html
Understanding Power Analysis in AB Testing
https://towardsdatascience.com/understanding-power-analysis-in-ab-testing-14808e8a1554
A/B 테스트 결과 해석에서 자주 발생하는 12가지 함정들
https://medium.com/bondata/a-b-테스트-결과-해석에서-자주-발생하는-12가지-함정들-2fe273b76a2d