Table Of Contents
아침에 커피 한잔을 뽑고 자리에 앉는다. 회사에서 주는 조식을 먹으면서 어제 정리한 서비스 전략 논리를 점검한다. 내가 만든 전략은 내가 봐도 너무 논리적이고 획기적이다. 디자이너와 엔지니어분들에게 프레젠테이션해서 개선 일정 정하고, DA/DS 분들과 변화를 어떻게 측정할지 논의해봐야지.
이게 보통 꿈꾸는 PM,PO의 모습일것 같은데 실상은 이렇다.
키워드 1만개 봐야하는데, 리더가 오늘안에 마무리해달라고 하네… 이거 끝나면 크롤러가 이미지 수집 잘 했는지 체크해봐야하는데, 노출량이 많은 호스트 위주로 봐야하나… 수집대상이 10만개 넘던데, 다 봐야하나….. 왜 사람은 안뽑고 일만 늘어나지… 배고프고 졸립다.
기획자라는 이름으로 시작해서 PM이라는 이름까지 9년 넘게 일을하고 있는데, 뭔가 드라마에 나올거같은 멋있는 장면은 9년동안 손, 발가락 수보다 적었다. 하지만 두번째와 같이 현실적인 상황은 내 머리털 수 만큼 셀 수 없이 많았다. 물론 필자는 탈모가 와서 머리털 수가 줄어들고 있다. 아마도 이런 노가다를 같이할 팀원들이 늘어나고, 아웃소싱을 활용할 수 있는 리소스를 건의할 수 있는 상황이 되다보니, 내가 해야할 노가다 업무량이 줄어든 만큼 같이 빠지나보다…
서비스가 단조로운 경우, 특히 도구성 앱을 담당하는 경우 노가다할 일은 적을지도 모른다. 하지만 검색서비스나 챗봇처럼 유저들이 보는 화면이 유저 수보다 다양한 경우에는 노가다 업무가 생각보다 많은 비중을 차지한다. 검색기획자로 시작해서 검색에 기반을 두는 광고 PM으로 일을 해오다 보니, 유저를 이해하기 위해서 그들의 검색어를 이해하��는게 매우 중요한 일이 된다. 그래서 시작과 끝에는 항상 검색어와 각종 지표가 빼곡한 엑셀시트가 함께한다. 심지어 최근에는 사람들의 취향 다양성이 높아지면서 엑셀 100만개로도 커버가 안되는 경우도 있다.
내가 받는 월급으론 억울해서 모든 과제마다 이 키워드를 다 볼 수 없고, 다 보고 싶어도 일정이 허용하지 않는다. 그러면 효율적으로 업무하기 위해서 적정수준까지 노가다 할 범위를 정하는게 중요하다. 하지만 지나치게 효율적이면 효과가 떨어지고, 고효과를 노리면 효율이 매우 떨어진다. 이 트레이드오프에서 효율,효과가 극대화되는 균형점을 찾을 수 있을까?
EDA는 PM,PO도 해야한다
내가 작업할 대상, 데이터의 분포를 알지 못하면 효율과 효과의 균형을 찾기 힘들다. 쉽게는 층화추출해서 랜덤샘플링하는 방법을 고민할지도 모르겠다. 데이터 지표를 보고 검토할 대상을 3~4로 그룹핑하고, 노출 고빈도 그룹에 보다 많은 샘플수를 할당해서 보는 방식이다. 샘플링은 전반적인 현황을 파악하는데는 효과적이지만, 운영 작업이나 리스크를 검토할때는 보지 않는 대상이 생기기 때문에 위험할 수 있다. 특히 고빈도의 경우 하나의 키워드나 객제가 많은 유저들에게 영향을 끼친다. 샘플링에 따라서 문제가 있는 부분을 놓치고 가게 될 수 있다.
EDA는 이 채널에서 많은 분들이 소개주셔서 자세한 설명은 하지 않겠다. Exploratory Data Analysis 는 목적을 달성하기 위해 어떤 분석이나 작업을해야할지 판단하기 위해 데이터의 패턴을 파악하는 일이다. 학부시절을 돌아보면 교수님께서 EDA라는 멋있는 말은 하지 않았지만, 뭘 하더라도 산포도부터 보고 시작하라고 말씀하신적이 있다. 통계적 분석이나 모델링을 위한 EDA라면 변수간의 관계를 파악하기 위해 산포도를 보고 시작하는게 좋지만, 오늘은 PM/PO의 노가다를 줄이기 위한 목적이기 때문에 산포도보다 실무에 도움이되며 엑셀에서 쉽게 사용할 수 있는 두가지 플롯을 소개하고자한다. 첫번째는 상자수염플롯, 두번째는 파레토플롯이다.
이 두개의 차트만 봐도 대충 몇번째까지 검토하면 될지, 직관적으로 판단하기 쉽다. 왜냐하면 두 차트 모두 데이터의 분포를 표현하는데, 상자수염은 주요 통계량을 한번에 �보여주고 있는 점에서, 일일이 평균, 중위수, 사분위수 등을 뽑아야하는 수고를 덜어준다. 그리고 파레토는 구간별로 관측값의 수를 비교하기 쉽고, 관측값이 많은 구간부터 적은 구간으로 정렬하여, 어느 구간을 작업하면 전체의 몇%를 처리할 수 있는지 파악하는데 쉽다.
상자수염플롯

상자수염플롯은 대상 데이터의 분포를 보여준다. 분포라고하면 최소값, 25%, 중위수, 75%, 최대값, 평균, 아웃라이어를 한 그림에 표현했다. 상자수염플롯을 사용하는 가장 큰 장점은 있어보이는 점이다..는 아니고, 하나의 그래프로 다양한 설명을 하기 쉽기 때문이�다. 구체적인 스펙은 제가 소개하는 것 보다, wiki를 보는게 더 도움이 되실 것이다.
예를 들면,
아웃라이어 때문에 중위수보다 평균값이 지나치게 높아요. 그래서 우리는 평균을 보면 안됩니다.
75%의 impression에 영향을 주려면 검색량이 하사분위수인 xx인 검색어까지 커버를 해야합니다
A그룹과 B그룹은 평균이 같지만, A 그룹의 데이터는 평균에 모여있는 반면, B는 평균과 위아래로 멀리 흩어져있습니다.
특히, 평균이 정말 대표값으로 적절한가? 평균은 아웃라이어에 취약하다. 표본 전체를 대표하는 대표값이 아닌 경우가 생각보다 많다. 상자수염플롯으로 아웃라이어가 얼마나 강력한지, 중위수와의 차이를 보고 평균을 쓸지 말지 판단��할 수 있다. 적어도 평균을 쓰더라도 아웃라이어를 제외한 평균 (절사평균)을 사용할지 말지를 판단할 수 있다. 평균이 같은 두 집단이 정말 비슷한 집단인지 비교하기도 좋다. 평균은 같은데, 평균에 데이터가 모인 집단일 수 있고, 평균 근처에는 데이터가 없고 양끝에 몰린 쌍봉형 분포일 수 있다. 이를 상자수염플롯으로 쉽게 구별할 수 있다.
개인적으로는 노가다를 줄이기 위해서 샘플링을해서 작업을 하는 경우가 많은데, 이때 표본이 실제와 비슷한 분포로 잘 뽑혔는지 확인하기 위해 자주 쓴다. 그리고 대표값을 함수로 각각 구하기 귀찮아서 이 플롯을 쓰기도 한다.
파레토플롯
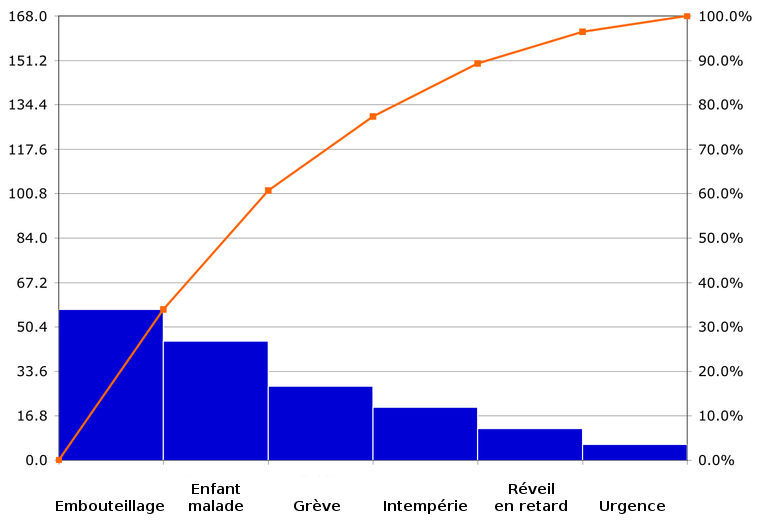
상자수염플롯은 아웃라이어, 최대, 상사분위, 중위, 평균, 하사분위, 최소 값만 보여준다. 좀 더 구간을 잘게 쪼개서 보고 싶다면? 파레토 플롯(차트)을 사용한다. 파레토 차트는 변형된 히스토그램이다. 히스토그램은 구간별로 관측값의 수를 보여준다. 파레토 차트도 정해진 갯수의 구간을 만들거나, 적당한 수준의 구간을 자동으로 설정한다. 다만 히스토그램과 차이점은, 히스토그램은 구간이 작은값에서 큰값 순서로 나열된다면, 파레토차트는 관측값이 많은 구간에서 적은 구간으로 내림차순된다. 따라서 구간의 값이 들쭉 날쭉 할 수 있다. 하지만 어떤 구간이 비중을 가장 많이 차지하고, 구간별 관측값이 어떻게 줄어가는지, 어떤 구간이 중요한지 쉽게 알 수 있다. 그리고 누적 분포 플롯도 같이 노출된다. 따라서 80% 정도 커버하려면 몇개 구간을 타게팅해야할지 쉽게 판단할 수 있다. 따라서 반드시 챙겨야할 구간들에 대해서 우선순위를 정하는데 도움이 많이 된다.
상자수염플롯과 파레토플롯은 엑셀에서 버튼 한번 클릭으로 만들 수 있다. 그 간편성 대비 업무의 수준을 높이는 효용은 매우 높다. 업무를 효율적으로 하고, 데이터의 분포도 쉽게 잘 판단하여 의사결정을 잘 하기 위해서 PM,PO,기획자도 엑셀에서 제공하는 간단한 차트로 EDA를 시작하고, 실수 없이 짧은 시간에 업무를 마무리하고…�여유가 아닌 다음 업무에 착수하며 생산성을 높이시길 빌겠다.
P.S. 이 글에서는 언급하지 않았지만 산점도도 많이 사용한다. 통계적 분석을 할때는 많이 보았지만, 일상적인 PM,PO,기획자 업무에서는 잘 사용하지 않아서 소개하지 않았다. 하지만 관심이 생겼다면 산점도에 대해서도 어떻게 쓸 수 있을지 스스로 고민해봐도 좋을 것 같다.