Table Of Contents
이 글은 작성자 블로그에서도 보실 수 있습니다.
서비스가 성장하기 위해서는 새로운 유저를 유입시키는 것도 중요하지만 기존 유저들이 제품을 계속해서 사용하도록 만들어야 합니다. AARRR 에서 두 번째 R을 담당하는 retention은 얼마나 많은 유저가 제품을 지속적으로 사용하고 있는지 측정하는 지표로, 서비스가 잘 성장하고 있는지 보여줍니다.
Retention을 시각화하는 방법 중 하나로는 cohort chart가 있습니다. Cohort는 공통점이 있는 유저 그룹을 의미하는데, 예를 들어 가입 날짜, 유입 채널 등으로 유저를 나눠볼 수 있습니다. Cohort chart를 그려보면 유저 그룹이 시간이 지남에 따라 어떻게 행동하는지 살펴볼 수 있습니다.
이 글에서는 python을 이용해 cohort chart를 그려보면서 retention에 대해 알아보겠습니다.
준비
가장 먼저 분석에 필요한 library를 가져와주세요.
from datetime import datetimeimport mathimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as sns
데이터
Kaggle 에서 찾은 Netflix audience behaviour - UK movies 데이터를사용하겠습니다. 데이터는 여기서 다운 받을 수 있습니다. 이 데이터는 2017년 1월부터 2019년 6월에 Netflix에서 컨텐츠를 클릭한 유저 데이터의 일부분입니다.
df = pd.read_csv('netflix_uk.csv')df.head()

- datetime: 콘텐츠를 클릭한 시간
- duration: 콘텐츠에서 이탈하기까지 걸린 시간 (초)
- title: 콘텐츠 제목
- genres: 콘텐츠 장르
- release_date: 콘텐츠 출시일
- movie_id: 콘텐츠 아이디
- user_id: 유저 아이디
본격적으로 데이터 전처리를 하기 전에 칼럼을 정리해 주겠습니다.
# (1) datetime 타입 수정df['date'] = pd.to_datetime(df['datetime'])# user_id, datetime, duration만 남김df = df[['user_id', 'datetime', 'duration']]
(1) datetime 변수 타입을 string에서 datetime으로 수정합니다.
(2) 앞으로 사용할 user_id, datetime, duration만 남겨줍니다.
Retention 준비 재료 - Core Event
Retention은 보통 재방문율이라고도 알려져 있지만 단순히 방문만 해도 retained 되었다고 한다면 유저가 서비스를 제대로 사용하고 있는지 확인하기 어렵습니다. 모든 서비스에는 유저에게 꼭 주고 싶은 가치와 연관된 이벤트가 있는데 이를 core event라 합니다. 쉽게 설명하면 유저가 제품을 이용하면서 계속 하면 좋겠는 행동을 의미합니다. Core event로 retention을 본다면 유저가 서비스에서 가치를 계속해서 가져가고 있는지 알 수 있습니다.
Netflix 데이터에서는 유저가 콘텐츠를 10분 이상 보는 걸 core event라고 정의할 수 있습니다. 홈페이지에 방문해서 아무런 행동을 안 하고 바로 이탈하거나 콘텐츠를 클릭해도 1초만 보고 이탈한 유저들은 Netflix에서 제공하고자 하는 가치를 경험했다고 하기 어렵습니다.
# (1) 10분 이상 컨텐츠를 본 데이터만 사용df = df[df['duration'] / 60 >= 10]# (2) duration 삭제df = df.drop('duration', axis=1)
(1) 10분 이상 컨텐츠를 본 데이터만 사용합니다.
(2) 이제 필요없는 duration은 삭제합니다.
Retention 준비 재료 - Usage Interval
제품의 usage interval을 어떻게 정의하느냐에 따라 똑같은 그래프로 더 많은 인사이트를 얻을 수도 있고 아닐 수도 있습니다. 예를 들어, 이용 주기가 분기별인 제품의 retention을 일별로 계산하면 당연히 Day 1부터 값이 급격하게 감소하고, 그 이후에도 계속 낮은 값을 가지기 때문에 어떠한 이야기를 하기에도 어려운 그래프가 되어버립니다.
Amplitude에서 발행한 Mastering Retention V1에서는 서비스 데이터로 usage interval을 정의하는 방법을 소개해 주고 있습니다.
- 일정 기간 내 core event를 최소 2번 수행한 유저 데이터를 수집합니다. 보통 60 - 90일 기간을 살펴보는데 탐색하는 기간은 서비스 특징에 따라 달라질 수도 있습니다.
- Core event를 두 번째로 수행하기까지 얼마만큼의 시간이 걸렸는지 계산합니다.
- 시간 간격에 따라 core event를 반복한 유저의 비율을 CDF 그래프로 그려봅니다.
- 80%의 유저가 이벤트를 반복한 시점을 찾습니다.
위 방법으로 Netflix 데이터의 usage interval을 찾아보겠습니다.
# (1) 2017-01-01 - 2017-03-31 기간 데이터만 사용df_sub = df[(df['datetime'] > datetime(2017, 1, 1)) & (df['datetime'] < datetime(2017, 3, 31))]# (2) 유저별로 이벤트를 처음 수행한 시간을 계산df_sub['first_event_date'] = df_sub.groupby('user_id')['datetime'].transform('min')# (3) datetime 칼럼 이름 수정df_sub = df_sub.rename(columns = {'datetime' : 'second_event_date'})# (4) first_event_date와 second_event_date이 같은 데이터 제거df_sub = df_sub[df_sub['first_event_date'] != df_sub['second_event_date']]# (5) user_id, first_event_date으로 정렬하고 user_id 별로 가장 첫 데이터만 사용df_sub = df_sub.sort_values(['user_id', 'second_event_date'])df_sub = df_sub.groupby('user_id').first().reset_index(drop=False)
(1) 2017-01-01 - 2017-03-31 기간 데이터만 살펴봅니다.
(2) 유저별로 core event를 처음 수행한 시간을 계산합니다. user_id를 기준을 group by 해주고 datetime의 최솟값을 찾습니다.
(3) datetime 칼럼 이름을 second_event_date으로 수정합니다.
(4) 모든 열에 first_event_date을 추가해 주었기 때문에 first_event_date와 second_event_date 값이 같은 데이터가 모든 user_id에 하나씩 있습니다. 이 데이터는 core event를 한 번만 한 것과 똑같은 의미를 가지기 때문에 삭제합니다.
(4) 관찰 기간에 core event를 세 번 이상 수행한 유저도 있을 수 있습니다. 하지만, 지금은 이벤트를 정확히 두 번 한 데이터만 있으면 되기 때문에 필요한 데이터만 남깁니다. first_event_date는 같은 user_id에서는 모두 같기 때문에 user_id, second_event_date으로 정렬하면 user_id 중에서 second_event_date가 가장 오래된 데이터가 위로 가게 됩니다. user_id를 기준으로 group by 해주고 가장 첫 번째 열만 가져옵니다.
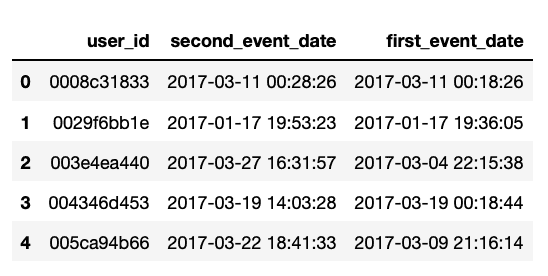
데이터를 전처리 해준 결과입니다. 테이블에서 세 번째 열을 보면 user_id가 003e4ea440인 유저는 2017-03-04에 처음으로 콘텐츠를 10분 이상 보았고, 23일 후인 27일에 두 번째로 보았습니다.
이제 CDF 를 계산해 보겠습니다.
def calculate_usage_interval(df):# (1) first_event_date와 second_event_date 사이에 몇 일이 있는지 계산df['diff_days'] = (df['second_event_date'] - df['first_event_date']).dt.days# (2) diff_days별로 유저 수 집계count = df.groupby('diff_days').count().iloc[:, 0]# (3) diff_days의 pdf 계산pdf = {}for index, value in enumerate(count):pdf[index] = value / sum(count)# (4) cdf 계산cdf = np.cumsum(list(pdf.values()))return cdf
(1) Core event가 처음 일어난 시간과 두 번째로 일어난 시간 사이에 며칠이 있는지 계산합니다.
(2) diff_days 별 유저 수를 �셉니다. 유저 아이디는 중복되어 있지 않기 때문에 단순히 count를 사용합니다.
(3) PDF부터 계산합니다. 전체 유저 중 diff_days가 특정 값을 가지는 비율을 계산합니다.
(4) PDF의 누적 합을 계산합니다.
def plot_usage_interval(cdf):# 0.8과 가장 가까운 위치의 값을 프린트print('80% threshold:', np.abs(cdf - 0.8).argmin(), 'days')# CDF 시각화plt.plot(cdf)plt.axhline(y=0.8, color='green', linestyle='-')plt.title('usage interval')plt.xlabel('days')plt.ylabel('percentage')plt.show()
cdf = calculate_usage_interval(df_sub)plot_usage_interval(cdf)
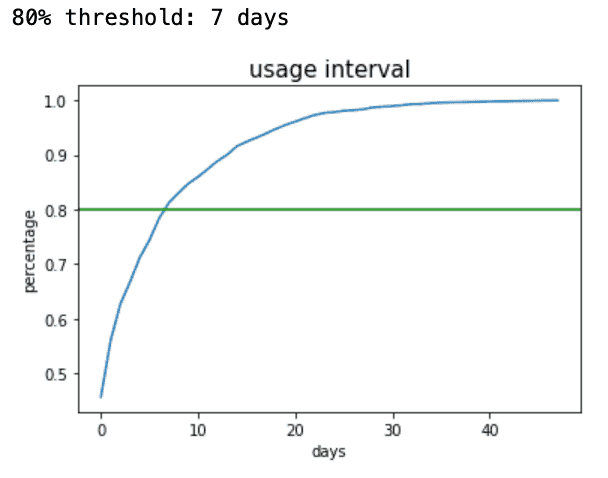
Netflix 데이터에서는 약 80%의 유저들이 콘텐츠를 10분 이상 본 날로부터 7일째 되는 날 또 다시 콘텐츠를 10분 이상 보았습니다. 즉, usage interval이 7일이라고 할 수 있습니다.
Cohort Chart 그리기
이제 앞에서 정의한 core event와 usage interval을 참고해 cohort chart를 그려보겠습니다. 먼저 그래프를 그릴 수 있도록 데이터를 처리해 줘야 합니다.
def calculate_retention_matrix(df):# (1) date 칼럼 추가, usage interval에 맞춰 날짜를 truncatedf['date'] = pd.to_datetime(df['datetime']).dt.datedf = df.drop('datetime', axis=1)df['date'] = df['date'] - pd.to_timedelta(pd.to_datetime(df['date']).dt.dayofweek, unit='d')# (2) 유저별로 이벤트를 처음 수행한 날짜를 계산df['cohort'] = df.groupby('user_id')['date'].transform('min')# (3) cohort마다 date를 기준으로 몇 명의 유저가 이벤트를 발생시켰는지 집계df_cohort = \df.groupby(['cohort', 'date']) \.agg(cnt=('user_id', 'nunique')) \.reset_index(drop=False)# (4) date와 cohort 사이에 몇 일이 있는지 계산df_cohort['diff'] = \[math.floor(x) for x in ((df_cohort['date'] - df_cohort['cohort']).dt.days) / 7]# (5) cohort를 index, diff를 column으로 하는 pivot 테이블을 만듦cohort_pivot = \df_cohort.pivot_table(index = 'cohort',columns = 'diff',values = 'cnt')# (6) cohort별로 유저 수를 셈cohort_size = df.groupby('cohort').agg(cnt=('user_id', 'nunique'))['cnt']# (7) cohort_pivot dataframe을 cohort_size로 나눠 비율 계산retention_matrix = cohort_pivot.divide(cohort_size, axis = 0)return retention_matrixretention_matrix = calculate_retention_matrix(df)
(1) 날짜 계산을 쉽게 하기 위해 datetime으로 date를 만듭니다. 그리고 주별 retention 그래프를 만들기 위해 date를 해당주의 월요일로 치환합니다.
(2) 주어진 데이터에서 이벤트를 처음 수행한 날짜를 기준으로 유저를 나눕니다. 보통 가입 날짜로 cohort를 만들지만, 가입 데이터가 없기 때문에 첫 번째 이벤트 발생 날짜를 사용하겠습니다.
(3) Cohort마다 시간이 지날수록 몇 명의 유저가 core event를 하는지 셉니다.
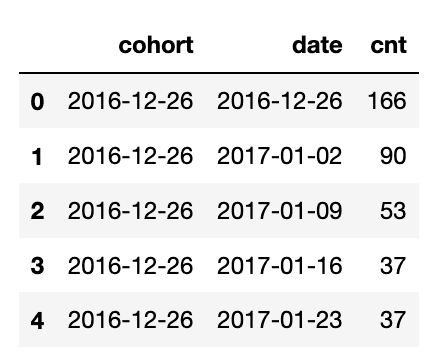
위 표는 df_cohort의 일부분입니다. 세 번째 열을 보면 2016-12-26 cohort에 속한 유저 중 53명이 2017-01-09 주에 core event를 했다고 할 수 있습니다.
(4) date와 cohort 사이에 몇 주가 있는지 계산합니다.
(5) cohort를 index, diff를 column, cnt를 값으로 하는 pivot 테이블을 만듭니다.
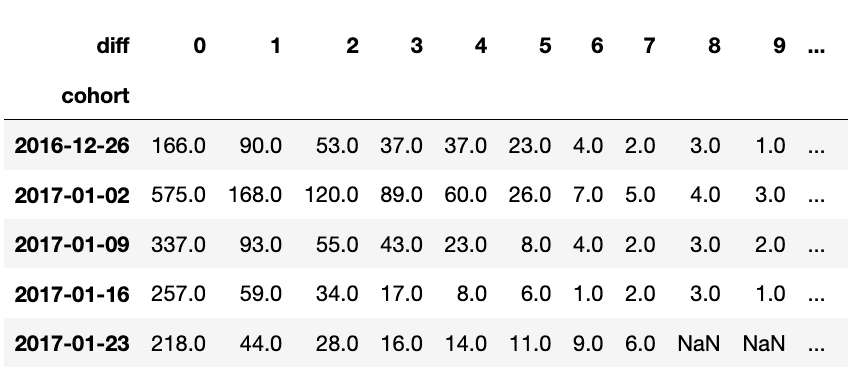
(6) 값 그 자체로도 의미가 있을 수 있지만, 우리는 비율을 계산하고 싶기 때문에 cohort 별로 유저 수를 셉니다.
(7) 위에서 계산한 값으로 비율을 계산합니다.
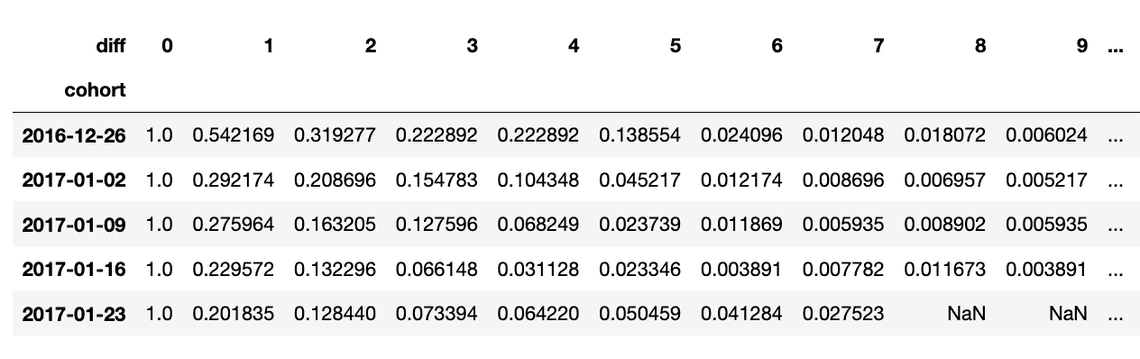
2016-12-26 cohort를 보면 당연히 0주에는 100% 유저가 core event를 했고, 1주일 후에는 54%, 2주일 후에는 31% 유저가 core event를 했다는 것을 알 수 있습니다.
드디어 모든 준비가 끝났습니다. Cohort chart를 그려보겠습니다.
def plot_cohort_chart(retention_matrix):# 그래프에 의미없는 값은 보여주지 않기 위해 안 나와도 되는 값의 위치 표시mask = retention_matrix.isnull()mask.iloc[:, 0] = True# cohort chart 시각화plt.figure(figsize = (20, 18))sns.heatmap(retention_matrix,mask=mask,annot=True,fmt='.0%',cmap=sns.cubehelix_palette(8),linewidths=.1)plt.title('cohort chart', fontsize=25)plt.xlabel('week', fontsize=15)plt.ylabel('cohort', fontsize=15)plt.show()plot_cohort_chart(retention_matrix)
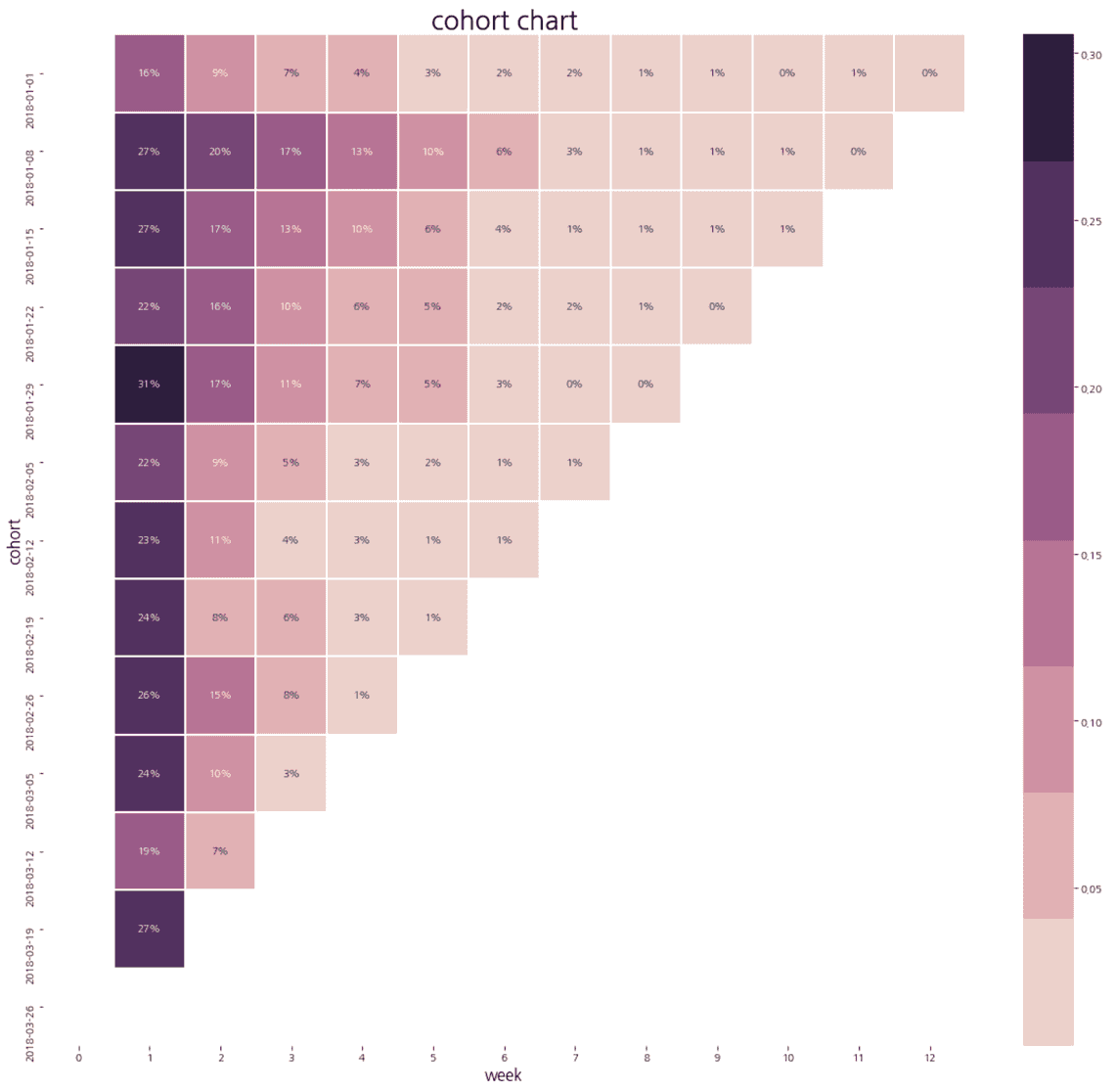
2018-01-08부터 2018-04-01 기간의 데이터만 사용해 그려보았습니다. 가장 왼쪽에 있는 행은 각 cohort의 week 1 retention입니다. 2018-01-01 cohort에서 week 1 retention은 16%인데 이는 2018-01-01 주에 core event를 처음 수행한 유저의 16%가 일주일 후에도 core event를 했다는 것을 의미합니다. 그 옆의 9%는 2018-01-01 주에 core event를 처음 수행한 유저의 9%가 이 주일 후에도 core event를 했다는 것을 의미합니다.
Cohort chart를 보면 다른 cohort와는 달리 값이 특이한 cohort가 있습니다. 2018-01-08 cohort는 다른 cohort에 비해 시간이 지날수록 retention이 떨어지는 폭이 작습니다. 이렇게 값이 특이한 cohort가 있다면 해당 주에 무슨 일이 있었는지 확인해 보는게 중요합니다. 만약 해당 주에 오프라인 행사를 진행해 행사로 유입된 유저들이 많다면 이 유입 채널이 retention 상승과 연관 있다는 가설을 세울 수 있습니다.
Retention을 시각화하는 또 다른 그래프로는 retention curve가 있습니다. Cohort 별로 retention을 보면 좋은 점도 있지만 데이터를 한눈에 보기 어렵다는 단점이 있습니다. Retention curve는 usage interval 별로 retention을 평균 내서 그리는 그래프로 서비스의 retention 현황을 한 번에 볼 수 있습니다.
def plot_retention_curve(retention_matrix):# usage interval별로 retention 평균 계산retention_avg = retention_matrix.mean(axis = 0) * 100# retention curve 시각화plt.figure(figsize = (10, 8))plt.plot(range(0, len(retention_avg)), retention_avg)plt.title('retention curve', fontsize=25)plt.ylabel('percentage', fontsize=15)plt.show()plot_retention_curve(retention_matrix)
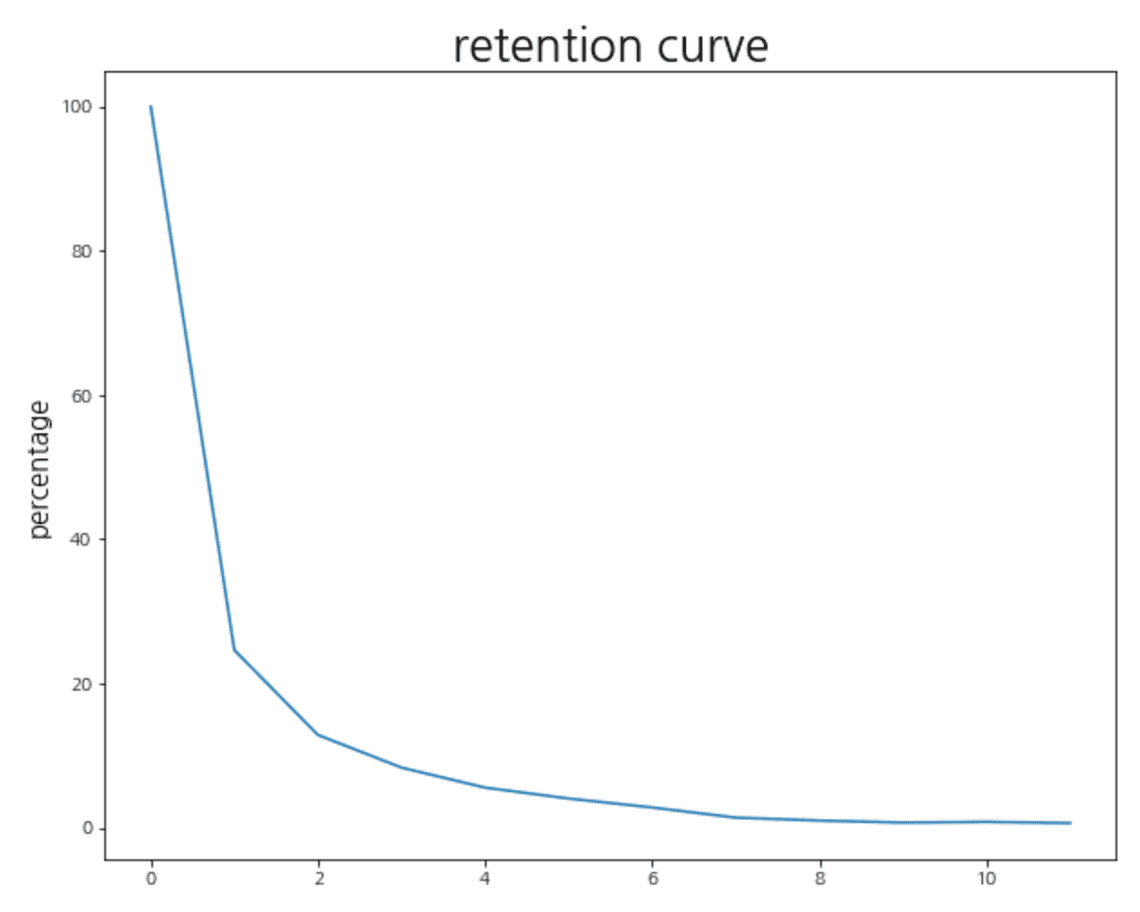
Cohort chart 보다 많은 인사이트를 얻기는 힘들지만, 한눈에 retention을 확인할 수 있다는 점에서 retention curve도 자주 사용됩니다. 위 그래프를 보면 Netflix의 week 1 평균 retention은 약 22%이고 시간이 지날수록 계속 감소하다 약 2%로 수렴하고 있습니다.
마무리
유저가 서비스를 계속 잘 사용하고 있는지 (또는 없는지) 알았다면, 이제 할 일은 어떻게 하면 retention을 올릴 수 있을지 고민하는 것입니다. 이 글에서는 단순히 cohort를 가입 날짜 또는 core event를 처음 수행한 날짜로 보았지만 다른 다양한 기준으로 유저를 나눠볼 수 있습니다. Netflix로 예를 들면 플랫폼, 유입 경로, 나이 등 유저의 특징을 사용해 볼 수도 있고 구독 지불 방법, 특정 영화를 본 유저와 보지 않은 유저, 좋아요를 클릭한 유저와 클릭하지 않은 유저 등 유저의 행동을 기준으로 나눠 볼 수 있습니다. 그리고 만약 특정 cohort의 retention이 유난히 좋다면 더 많은 유저들을 이 cohrot로 만들기 위해 제품 개선을 시작해 볼 수 있을 것입니다.