Table Of Contents
도메인 없이 인과추론이 가능할까?
인과추론은 도메인에 상당 부분 의존할 수 밖에 없는 방법론입니다. 도메인에 대한 지식이 있어야 관심의 대상 (결과, outcome)을 정의할 수 있고, 이에 직접적으로 개입할 수 있는 요인 (처치, treatment)을 선정할 수 있습니다. 그리고 처치가 결과에 주는 영향을 정확하게 파악하기 위해서는, 이 둘에 영향을 미치는 교란변수 (confounder)들을 알고 있어야 합니다. 사실 처치와 결과는 상식선에서 선정하는 것이 가능할 수 있지만, 교란변수를 알기 위해서는 도메인에 대한 지식 없이는 어려운 지점들이 많습니다.
하지만 전문가라 하더라도 관찰된 변수가 수도 없이 많을 경우 이 관계들을 사전에 정확하게 아는 것이 어려울 수 있습니다. 그래서 완전히 data-driven하게 변수간의 그래프 구조를 식별하기 위한 시도로 causal discovery라는 방법이 있습니다. 하지만 causal discovery는 변수의 형태를 제한하는 등의 제약이 없으면 작동하기 어려우며, 변수간의 모든 조합을 고려하는 것은 계산량이 너무 많은 방법입니다.
인과추론으로 무엇을 알고 싶은데?
그러면 다시 원점으로 돌아가봅시다. 인과추론을 통해 알고 싶은 것은 무엇인가요? 어떤 실험/처치/행동/정책이 가져온 효과를 정량적으로 분석하고 싶은 것이었죠. 그렇다면 사실 변수간의 모든 관계를 알 필요는 없습니다. 왜냐하면 효과를 추정할 때 bias를 야기할 수 있는 교란변수를 보정했다 (모형에 넣었다)는 사실이 중요하지, 변수들간의 관계 자체는 bias에 영향을 전혀 미치지 않기 때문이죠. 사이에 어떤 관계가 있는 지를 개를 다 확인할 필요가 없다는 뜻입니다. 대신 어떤 가 처치와 결과에 영향을 주는 로 작용하고 있는지 개만 확인하면 됩니다. 훨씬 문제가 간단�해지죠?
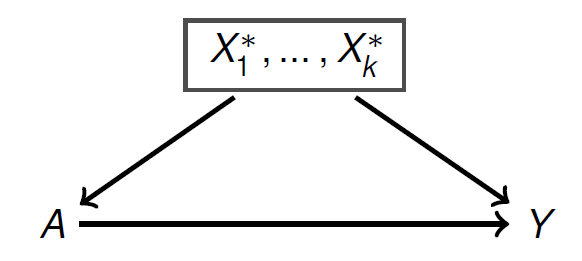
그래서 우리는 도메인에 대한 지식이 부족해도, 혹은 알고는 있지만 수많은 변수들을 수작업으로 일일이 가려내는게 어려워서 교란변수를 모형 기반으로 보정하는 방법에 대해 알아볼 것입니다. 대신 모형기반의 교란변수 보정이라고 해서 도메인에 대한 지식이 전무해도 실시할 수 있는건 아닙니다. 기본적인 가정에 대해 알아보도록 하겠습니다.
모형 기반의 교란변수 보정
모형 기반으로 교란변수를 보정하려면, 잠재적 교란변수의 대상은 한정해줄 필요가 있습니다. 적어도 변수들간의 시간적 선후관계는 알아야 합니다. 그래서 시간적으로 처치 이전에 발생한 변수 (pre-treatment covariate)만을 걸러서 남겨주어야 합니다. 우리가 다루는 변수는 교란변수, 처치와 결과 동시에 영향을 주는 변수이기 때문입니다. 처치 이후에 정해지는 변수라면 처치에 영향을 주기는 어려우니까요.
더불어 교란변수 보정이라고 해서, 단순한 Lasso 회귀모형으로 결과 를 처치 와 일부의 잠재적 교란변수 로 설명하려는 시도는 적절하지 않습니다. 계속 강조하고 있듯, 교란변수는 처치와 결과에 모두 영향을 주는 변수입니다. 단순히 Lasso 같은 모형에 넣고 끝나면, 해당 변수는 결과 를 예측하기 위한 모형일 뿐입니다. 그 결과로 선택된 는 교란변수라고 말할 수 없으며, 교란변수가 아니기 때문에 정확한 추정도 어렵고, 인과를 이야기하는 것도 어렵습니다. 그래서 모형 기반의 교란변수 보정 방법은 결과 에 대한 모형 뿐만 아니라, 처치 에 대한 모형도 고려해주어야 합니다. 실제로 이를 위한 모형들은 결과와 처치에 대한 모형을 동시에 적합합니다. 이를 위한 선형모형이 아닌 머신러닝 기반의 모형을 살펴보겠습니다.
트리 모형 기반의 교란변수 보정
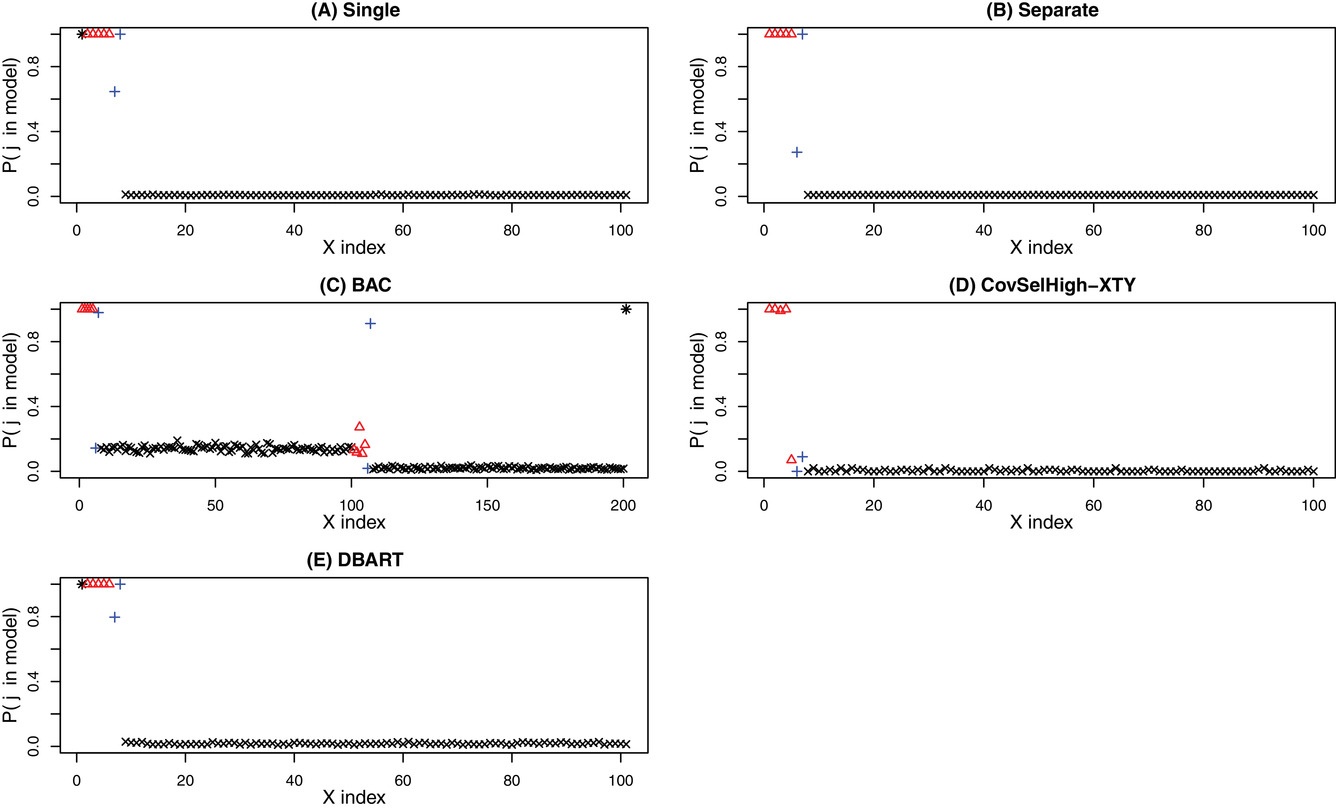
머신러닝 기반의 교란변수 보정 모형은 인과 효과에 대한 추정은 정밀하게 수행할 수 있으나, 일반적으로 어떤 변수가 교란변수로 작동하는지 알 수 없습니다. 하지만 베이지안 트리 앙상블 모형인 BART를 이용하면, 놀랍게도 1) 정확한 효과 추정, 2) 교란변수일 확률까지 동시에 수행하는 것이 가능합니다 (Kim et al., 2023). 해당 모형은 처치 에 대한 BART와 결과 에서 나무 분기에 동시에 사용되는 변수들에 더 큰 가중치를 주어 학습하는 방식입니다. 그 결과 교란변수가 아닌 변수들은 최종적으로 모형에 전혀 포함되지 않고, 교란변수 혹은 결과 에만 영향을 주는 변수만 선택되어 정확한 인과효과 추정이 가능하다는 장점이 있습니다. 제 경험상 적은 데이터 ()에서도 상당히 효과적으로 작동하는 모형입니다.
뉴럴넷 기반의 교란변수 보정
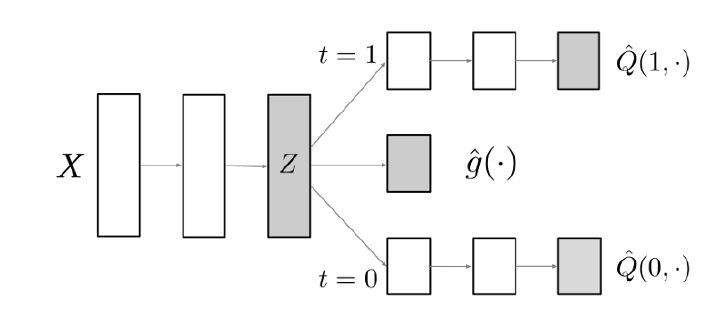
뉴럴넷을 기반으로 데이터 기반의 교란변수 보정을 하고 싶다면, 이를 위한 모형으로 Draggonet (Shi et al., 2019)이 존재합니다. 해당 모형은 잠재적 교란변수 들로 네트워크를 거쳐 처치 에 대한 예측을 수행하고, 여기서 만들어진 가중치들로 다시 잠재적 결과 을 예측하는 모형입니다. 단순히 결과 을 예측하지 않고, 처치 에 대한 정보를 충분히 갖도록 모형이 구성되어 있어, 다른 뉴럴넷 모형에 비해 효과 추정이 우수하다고알려져 있습니다. 다만 데이터의 수가 적은 경우, 뉴럴넷 모형이다보니 좋은 성능은 고려하기 어려울 수 있습니다.
언제 쓸 수 있을까?
모형 기반의 교란변수 보정 방법은 결과 와 처치 의 정보를 종합해 모형을 구성하고, 이를 바탕으로 효과를 추정하는 방법입니다. 이를 위한 모형으로 머신러닝 모형이 많이 사용되다보니, 관측치 의 개수가 충분하면서 잠재적 교란변수의 개수 가 많은 경우에 사용하는 것이 적절합니다. 모형이 엄청나게 무겁지는 않지만, 굳이 설계된 실험 같이 간단하게 분석할 수 있는 문제를 이렇게 풀 필요는 없습니다. 이미 관측이 끝났지만 데이터는 충분히 주어져 있는 경우에, 사후적으로 사용할 수 있는 방법이라고 이해하시면 될 것 같습니다.
참고자료
- Python Dragonnet 적용 코드
- R 교란변수 보정을 위한 BART 적용 코드
- Kim, C., Tec, M., and Zigler, C. Bayesian nonparametric adjustment of confounding. Biometrics (2023).
- Shi, C., Blei, D., adn Veitch, V. Adapting neural networks for the estimation of treatment effects. In Advances in Neural Information Processing Systems (2019).